.png)

.png)


.png)

Introduction: Beyond Next-Token Prediction
The success of large language models (LLMs) has largely been driven by their capacity to predict the next word in a sequence. This deceptively simple mechanism has allowed models like GPT-4 and Claude to generate essays, code, and even solve math problems with increasing fluency. But beneath this fluency lies a serious limitation: while LLMs can mimic human responses, they often falter when true reasoning is required—especially when faced with complex, multi-step problems. The problem, as researchers from Stanford, UC Berkeley, and SynthLabs.ai have argued, is not just a matter of scale, but of structure. Their proposed solution is a framework called Meta Chain-of-Thought (Meta-CoT)—a novel approach that could reshape the very way AI models think.
The Limits of Traditional Chain-of-Thought
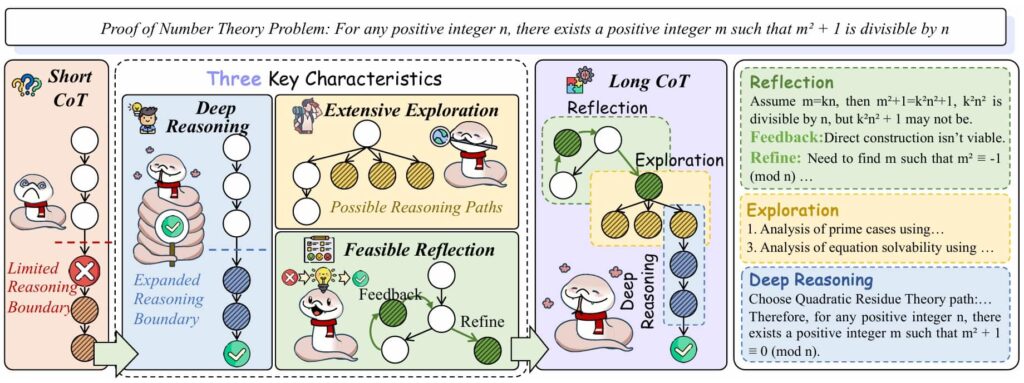
Chain-of-Thought (CoT) prompting has been a major advance in LLM reasoning. By guiding the model to “think step by step,” CoT allows it to perform intermediate calculations or logic checks before arriving at a final answer. However, as the researchers demonstrate, CoT still falls short in situations that demand non-linear reasoning, exploration of alternatives, or the ability to revise flawed lines of thought.
The key insight is that complex problems are not solved by a simple left-to-right generation of thoughts. Instead, they involve latent internal deliberations—mental “moves” we don’t usually write down. CoT captures the output of a reasoning process, but not the process itself. This is where Meta-CoT comes in.
What Is Meta Chain-of-Thought?
Meta-CoT extends the traditional CoT framework by modeling the reasoning process behind the reasoning. Instead of treating the sequence of logical steps as fixed, Meta-CoT introduces latent variables that represent the internal search, trial-and-error, and self-correction mechanisms that underlie human reasoning.
Think of solving a math problem like navigating a maze: you try one path, hit a wall, backtrack, and try another. Traditional CoT records only the final successful path. Meta-CoT aims to capture the full journey—including the dead ends and detours. This richer representation is essential for solving problems with high complexity, such as International Mathematics Olympiad puzzles or algorithmic challenges where the solution space is vast and unintuitive.
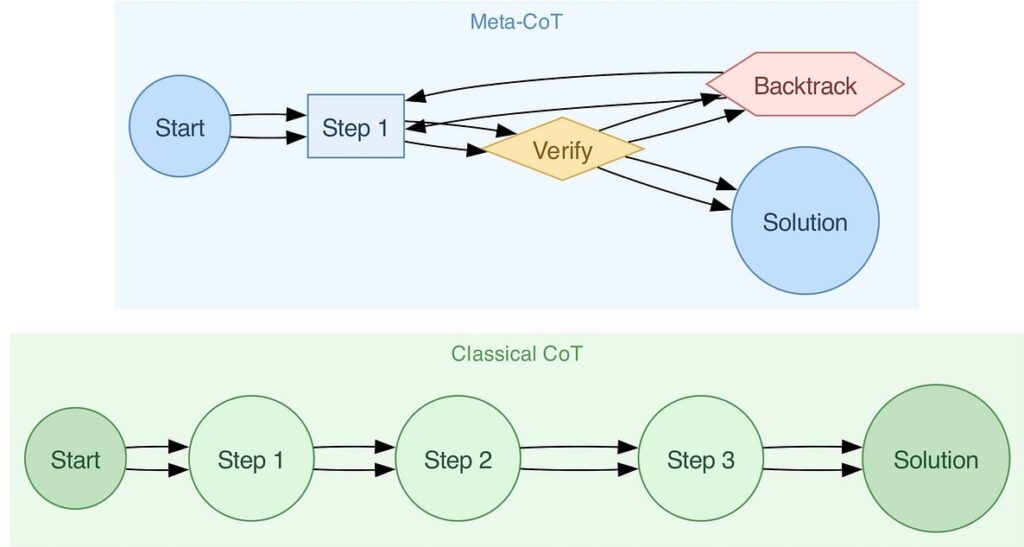
The Case for System 2 Reasoning
The researchers frame Meta-CoT as a form of System 2 reasoning, drawing from cognitive psychology’s dual-process theory. Where System 1 is fast, intuitive, and automatic, System 2 is slow, deliberate, and reflective. Most LLMs today operate as turbocharged System 1 engines. Meta-CoT aspires to introduce a controlled, deliberative layer—one that can search, revise, and verify its own reasoning in real time.
Implementing Meta-CoT: Search, Supervision, and Self-Correction
The three pillars of the Meta-CoT pipeline:
- Inference-Time Search: At its core, Meta-CoT relies on structured search during inference. Rather than generating a single output, the model explores multiple reasoning paths, evaluates their quality, and selects the best. Algorithms like Monte Carlo Tree Search (MCTS) and A* are used to simulate this cognitive search process, enabling backtracking and pruning of weaker lines of reasoning.
- Process Supervision: Instead of only rewarding correct final answers, Meta-CoT training involves supervising the reasoning process. This is done through Process Reward Models (PRMs) that evaluate partial solutions. Verifier models assign scores to intermediate reasoning states, guiding the model toward promising paths even before a final answer is reached.
- Meta Reinforcement Learning (Meta-RL): To internalize these strategies, the researchers employ reinforcement learning post-training. Here, the model learns not only which answers are correct, but which sequences of thought tend to produce correct answers. Over time, this allows the model to internalize search procedures and develop a kind of cognitive intuition for complex problems.
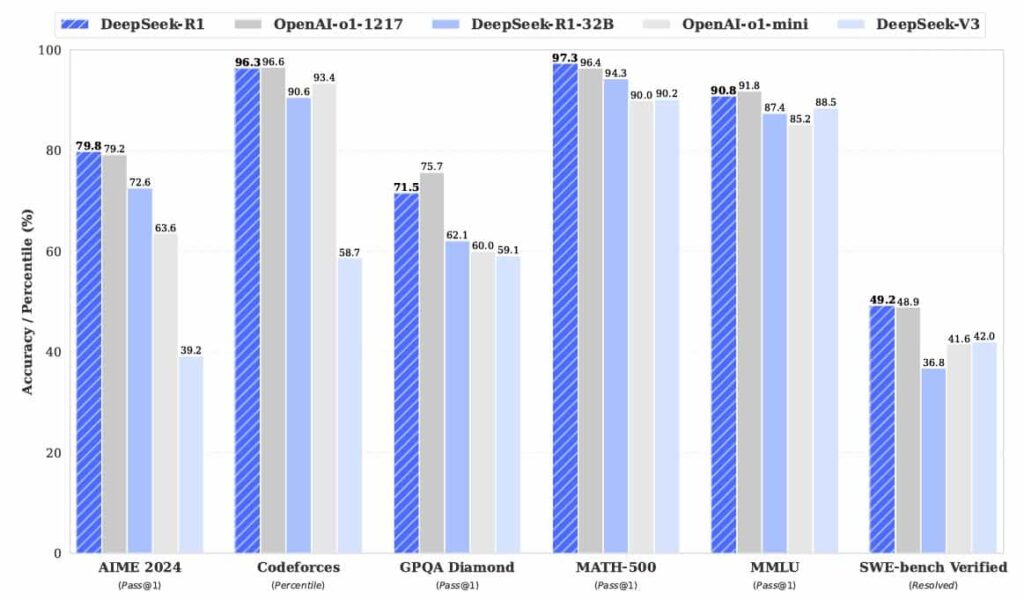
Real-World Performance and Empirical Evidence
Evidence for Meta-CoT’s effectiveness comes from experiments on challenging benchmarks like HARP and the “Big MATH” dataset—collections of complex math problems beyond the reach of traditional CoT models. Models trained under Meta-CoT principles, such as OpenAI’s o1 series, significantly outperform their predecessors, especially on problems that demand deeper reasoning.
Interestingly, these models also generate longer solutions. This isn’t verbosity—it reflects genuine cognitive effort. Just as a student who carefully works through a tough math problem writes more, Meta-CoT-equipped models produce richer reasoning trails. The number of tokens used scales with problem difficulty, a strong indicator that the model is engaging in deeper thought rather than shallow pattern matching.
Adaptive Thinking: From Self-Correction to Backtracking
Another critical component of Meta-CoT is the ability to revise and backtrack. Experiments show that when trained on data containing intentional errors followed by corrections, LLMs can learn to recognize flawed reasoning and reset to earlier points. This capability is crucial for domains where false starts are common, such as scientific hypothesis generation or legal reasoning.
Moreover, Meta-CoT enables models to adapt the amount of computational effort they expend. On simpler problems, models complete tasks in fewer steps; on harder ones, they explore longer, more diverse paths. This mirrors how humans allocate mental energy—a hallmark of intelligent behavior.

Challenges Ahead
While promising, Meta-CoT is not without challenges. The framework requires significantly more computational resources during training and inference, making it expensive to scale. Training models to backtrack or self-correct also introduces complexity in dataset generation and evaluation. Furthermore, while internal search can be powerful, it risks becoming opaque. Making the reasoning process interpretable and trustworthy remains a major concern.
Another open question is whether reasoning ability scales smoothly with model size and training compute, or whether there are inflection points—moments when a model suddenly gains qualitatively new capabilities. Meta-CoT research may help uncover these “scaling laws” for reasoning.
Toward Thinking Machines
Meta Chain-of-Thought represents a fundamental shift in how we train and evaluate language models. Instead of teaching them what to think, we are now teaching them how to think. This evolution moves us closer to LLMs that do not merely recite learned patterns, but can reason through unfamiliar territory with insight, flexibility, and self-awareness.
In short, Meta-CoT may be the first serious step toward artificial intelligence that not only generates answers—but understands the questions.
Reference
Xiang, Violet, Charlie Snell, Kanishk Gandhi, Alon Albalak, Anikait Singh, Chase Blagden, Duy Phung, et al. “Towards System 2 Reasoning in LLMs: Learning How to Think With Meta Chain-of-Thought.” arXiv.org, January 8, 2025. https://arxiv.org/abs/2501.04682.
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.