



.png)

.png)


.png)

Understanding Large Language Models: The Geometric Structure of Concepts
Feb. 28, 2025.
4 mins. read.
 16 Interactions
16 Interactions
What if AI organizes knowledge like the human brain—or even the universe? Researchers uncover stunning geometric patterns shaping how large language models understand the world.
About the Writer

About the Editor






Introduction
The rapid advancement of artificial intelligence has led to increasingly powerful large language models (LLMs), but how exactly do they represent and process information? Recent breakthroughs in research, particularly through the use of sparse autoencoders (SAEs), have revealed a fascinating geometric structure underlying concept representation in these models. By analyzing these structures, researchers have identified three distinct organizational levels: “atomic” scale, where semantic relationships form crystal-like structures; “brain” scale, where clusters of concepts exhibit modularity akin to biological brain lobes; and “galaxy” scale, where the overall structure of the concept space forms a distinctive shape suggestive of hierarchical information compression.
This article explores how these newly discovered structures offer deeper insights into the inner workings of LLMs, providing pathways for improving model efficiency, interpretability, and application.
Atomic Scale: Crystal Structures in Concept Space
At the smallest scale, SAE-extracted feature spaces display geometric formations known as crystals, revealing fundamental semantic relationships between concepts. These structures manifest in parallelograms and trapezoids, illustrating consistent transformations between related words or ideas.
For example, a well-known relationship is observed in the (man, woman, king, queen) parallelogram, where the vector difference between “man” and “woman” is approximately equal to the difference between “king” and “queen.” Similarly, a trapezoidal structure appears in (Austria, Vienna, Switzerland, Bern), where the difference vectors representing “country to capital” mappings are proportionally aligned.
Overcoming Noise with Linear Discriminant Analysis
Initial attempts to identify these structures were hindered by distractor features, such as word length, which obscured meaningful semantic patterns. To address this, researchers applied Linear Discriminant Analysis (LDA), which filters out irrelevant information, revealing clearer and more refined crystal structures. This preprocessing step greatly enhanced the clustering quality of concept relationships, improving our understanding of how LLMs encode meaning at a granular level.
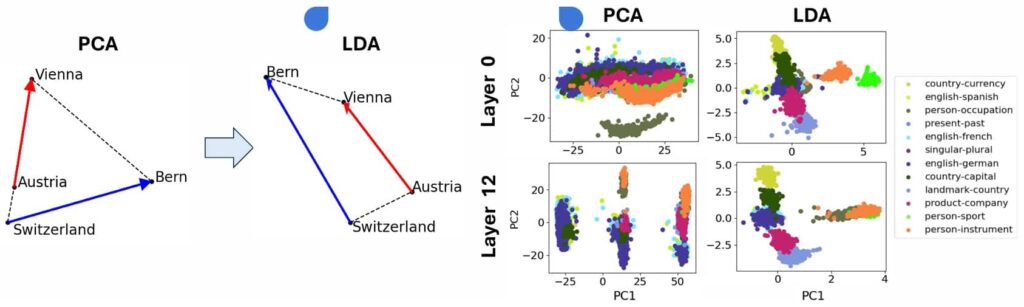
distractor dimensions, tightening up clusters of pairwise Gemma-2-2b activation differences (right). (Credit: Li et al., “The Geometry of Concepts: Sparse Autoencoder Feature Structure.”)
Brain Scale: Functional Modularity and Concept Lobes
Moving beyond individual relationships, researchers have discovered functional modularity in SAE feature spaces, reminiscent of the lobes in biological brains. These “lobes” consist of spatially clustered, functionally related features that tend to activate together when processing documents.
Using co-occurrence statistics and spectral clustering techniques, researchers identified distinct lobes for various thematic domains. For example:
- A “math and coding” lobe, where features related to logic, computation, and programming cluster together.
- A “short-text dialogue” lobe, which corresponds to informal conversations, chat interactions, and social media.
- A “long-form content” lobe, where features associated with scientific papers and in-depth articles are concentrated.
These lobes were validated through multiple statistical methods, including adjusted mutual information metrics and logistic regression models that successfully predicted functional lobe membership based on geometric positioning within the feature space.
Galaxy Scale: The Large-Scale Structure of Concept Space
At the highest level of abstraction, the overall geometry of the SAE feature space exhibits a distinct large-scale shape, deviating significantly from a simple Gaussian distribution. Rather than being isotropic, the concept space follows a power-law distribution, forming a structure researchers have dubbed the “fractal cucumber.”
Shape and Information Compression
Analysis of the covariance matrix eigenvalues revealed that the point cloud’s structure is governed by a power-law decay, with the steepest slopes appearing in the middle layers of the model. This suggests that LLMs may employ hierarchical information compression, where higher-level concepts are stored in fewer principal components for greater efficiency.
Clustering and Entropy in Middle Layers
Another key discovery is the non-random clustering of features, particularly in middle layers, where clustering entropy is significantly reduced. This implies that these layers serve as a bottleneck for information processing, efficiently organizing concepts in a way that balances generalization with specificity.

Conclusion
The hierarchical organization of concept representation in LLMs, as revealed through SAEs, provides critical insights into their inner workings. The “atomic” scale uncovers fundamental semantic relationships through crystal-like structures, the “brain” scale highlights functional modularity akin to biological cognition, and the “galaxy” scale reveals large-scale geometric patterns that may govern information compression.
These findings offer a new perspective on how LLMs encode, store, and process knowledge, paving the way for future advancements in AI interpretability and efficiency. By leveraging these insights, researchers can develop more structured, transparent, and adaptable models, enhancing the real-world applicability of artificial intelligence.
References
Li, Yuxiao, Eric J. Michaud, David D. Baek, Joshua Engels, Xiaoqing Sun, and Max Tegmark. “The Geometry of Concepts: Sparse Autoencoder Feature Structure.” arXiv.org, October 10, 2024. https://arxiv.org/abs/2410.19750.
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.












3 Comments
3 thoughts on “Understanding Large Language Models: The Geometric Structure of Concepts”
This is really fascinating! The way LLMs organize concepts—from crystal-like structures to brain-like lobes and a "fractal cucumber"—gives deep insight into their inner workings.
🟨 😴 😡 ❌ 🤮 💩
This article brilliantly unveils the geometric structures in LLMs—atomic crystal-like relationships, brain-like modularity, and galaxy-scale hierarchical compression. These insights into how AI organizes knowledge pave the way for more efficient, interpretable, and adaptable models. A must-read for understanding the future of AI
🟨 😴 😡 ❌ 🤮 💩
Fascinating insights into how LLMs organize concepts through crystal structures, functional lobes, and large-scale geometry. The discussion on information compression and AI interpretability is especially compelling!
🟨 😴 😡 ❌ 🤮 💩