



Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.
Explore The Amazing Sea Robin’s Adaptations

Not Like Us: Have Shady Political Memecoins Killed The Crypto Bull Run?

Introduction
The rise of tainted politically-themed meme coins in 2025 was a weird chapter in the cryptocurrency story. It mercifully might have come to an end last week, as the $LIBRA token, initially backed by Argentinian president Javier Milei, crashed by 90% after reaching a market cap of $4.5 billion. For many in crypto, it was the straw that broke the camel’s back, just like 2022’s FTX collapse.
Since then the autopsy around its demise revealed that there are some shady foxes in the crypto hen house (aka known in crypto as the cabal) bleeding the space dry as they ‘snipe’ (buy before anyone else) new tokens early in order to maximise their profits and dump their coins on incoming retail buyers.
In Kendrick Lamar’s words, “They’re not like us”.
Here is the Libra mastermind Hayden Davis talking about “max extracting” (or selling the top) on another project prior.
Davis later admitted to being involved with other crashes such as the $MELANIA meme coin.
It’s clear now that the game is rigged, and this situation is raising questions about the ethical implications and regulatory frameworks surrounding meme coins, especially when they involve high-profile politicians and celebrities.
The U.S. government announced a new Cyber and Emerging Technology Unit (CETU) agency – so maybe help is on the way for retail investors. This may well one day result in prosecutions similar to the fallout of the 2017 ICO craze, and 2021 token promotions by Floyd Mayweather and other celebrities.
For now, let’s look at the scandals and lessons of PolitiFi meme coin launches that have halted crypto in its tracks in 2025 and fooled investors for “billions and billions of dollars” thus far.
The Political Memecoin Wall of Shame
1. $TRUMP Coin
Launched just days before Donald Trump‘s inauguration in January 2025, the $TRUMP coin quickly gained attention, surging to a peak of $75 before crashing to around $19 shortly thereafter.
Critics raised concerns about the token’s structure, as a significant portion was controlled by entities affiliated with the Trump Organization, leading to accusations of potential market manipulation and conflicts of interest.
The token’s rapid rise & fall exemplified the volatility and speculation inherent in meme coins, and crashed all crypto markets as a result, extracting a lot of value from the space.
2. $MELANIA Coin
Following the launch of $TRUMP, Melania Trump introduced her own meme coin, $MELANIA. It experienced a staggering increase in value, then quickly lost nearly 80% of its value. The coin’s connection to Melania Trump drew significant media attention, but it also raised ethical questions regarding the use of celebrity endorsements in potentially fraudulent schemes.
Hayden Davis of $LIBRA recently admitted to being part of the launch, and it’s come to light that several influencers and other insiders were given the contract address by Meteora before the launch, allowing them to snipe tokens for cheap. It has resulted in CEO Ben Chow stepping down this week. As a result, Solana’s price took a big dump this week. Shame! Shame!
3. $LIBRA Coin
In Argentina, President Javier Milei briefly promoted $LIBRA as part of his economic strategy. Initially celebrated as a bold move to boost the economy, it quickly devolved into controversy when insiders such as Kelsier Ventures executed a ‘rug pull’, leading to an 80% drop in value shortly after its launch. Almost $100 million was pilfered by insiders during the launch.
This incident caused financial losses for investors, and the political outrage against Milei’s administration may yet see him impeached.
Argentina’s Memecoin Disaster Is Worse Than You Think. You can watch the whole debacle here:
4. Barron Trump Coin
An unofficial meme token named after Barron Trump briefly captured attention with a market capitalization reaching $460 million before crashing by 95%. This incident demonstrated how easily scammers could exploit high-profile names to create fraudulent tokens that misled investors.
5. $CAR Crash
In February 2025, the Central African Republic (CAR) launched its official meme coin, $CAR, as an experiment to unite people, support national development, and uniquely place CAR on the world stage. (If you see the word “experiment” in crypto, stay away!)
CAR’s embrace of crypto innovation isn’t new; in 2022, it became the second country after El Salvador to adopt Bitcoin as legal tender. Despite holding reserves of gold and diamonds, CAR struggles with economic instability. The government hoped to capitalize on the meme coin trend to draw international attention and investment.
The value of $CAR soon experienced a dramatic decline, dropping as much as 90% on some exchanges. Next, the Twitter account dedicated to $CAR updates was suspended, raising concerns. Additionally, there were reports that the President’s announcement video showed signs of being a fake video, casting doubts on the whole project.
Despite these issues, President Touadéra remained optimistic, suggesting that $CAR could fund national development projects, such as renovating educational institutions. I wouldn’t hold my breath, or my tokens.
6. $JAILSTOOL: The Alleged Dave Portnoy “Rug Pull”
In 2025, Dave Portnoy, the outspoken founder of Barstool Sports, faced accusations of a ‘rug pull’ involving a meme coin called $JAILSTOOL. Portnoy mocked investors online for being fools, but ironically days later he had to be bailed out by $5 million by Hayden Davis (as an important social media influencer) after he lost it in the Libra launch.
Ethical Concerns and Market Manipulation
Critics argue that using political figures for financial gain blurs the lines between legitimate investment opportunities and exploitative schemes designed primarily for profit at the expense of unsuspecting investors. In Trump’s hands-off regulatory approach to crypto, this becomes more important than ever.
The ease with which these tokens can be launched – with minimal regulatory oversight – creates an environment ripe for fraud and manipulation, especially when all these retail buyers don’t understand much about token issuance. It’s time for change.

Can We Fix Meme Coins Through Regulation?
To address the fallout from exploitative meme coin trends and protect investors, comprehensive regulatory frameworks are necessary. Here are some potential fixes recommended by experts:
- Enhanced Transparency Requirements
Regulatory bodies should mandate clear disclosure of tokenomics (i.e. the economic model behind a cryptocurrency) including information about token distribution, ownership concentration, and potential risks associated with investment.
- Investor Education Initiatives
Governments should implement educational programs aimed at informing potential investors about the risks associated with cryptocurrencies and how to identify red flags in speculative investments.
- Licensing for Token Creators
Require developers of new cryptocurrencies to obtain licenses: this can help ensure that only responsible entities enter the market, while providing a mechanism for accountability.
- Collaboration with Blockchain Analytics Firms
Regulatory agencies should partner with blockchain analytics firms to monitor transactions and identify suspicious activity related to newly launched tokens.
- Global Regulatory Coöperation
Given the borderless nature of cryptocurrencies, international coöperation among regulatory bodies is essential to create uniform standards that prevent exploitation across jurisdictions.
Conclusion
As seen with tokens like $TRUMP, $MELANIA, and $LIBRA, speculation driven by celebrity endorsements can lead to devastating financial consequences for everyday investors. To mitigate these risks, robust regulatory frameworks must be established that prioritize transparency, accountability, and investor protection, and these must be enforced.
Luckily, the blockchain is immutable and every single transaction there forever. So if you’re a meme coin scammer or rugpuller, know that maybe one day, CETU is gonna GETU.
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.
Should we still want biological space colonists (Part 2)?

This is a follow-up to my article Should we still want biological space colonists?, published earlier this month.
I argued that, with artificial intelligence (AI) advancing rapidly, we might soon see Human-Level Artificial General Intelligence (HL-AGI), AI that can think like humans. If AI can pass the Turing Test, proving it’s human-like, we might consider AI conscious.
This new AI consciousness could be strange at first, but grow more human-like, especially in robots interacting with people. If we accept that AI robots are ‘people’, sending them to colonize space would be logical. Robots are hardier against the threats of space: they don’t need life support, don’t sleep, can have parts replaced when they break (unlike a human hand), and can back up their data so the work can carry on seamlessly if they’re destroyed.
In the long term, filling the universe with intelligence is our common cosmic destiny, and future AI robots can achieve it.
However, there’s a human desire for people, not just robots, to explore space. Starting human space colonization now is important. Plus, human missions inspire young scientists and engineers, potentially speeding up the development of new technologies including advanced AI. So, I concluded that we should pursue both human and robotic space expansion.
Wide-spectrum reactions
I shared Should we still want biological space colonists? to several online discussion groups and mailing lists, and received passionate replies ranging from ‘enthusiastic YES’ to ’emphatic NO’, and more nuanced replies in between.
The high level of engagement in groups that are usually quieter tells me that many of those who are both space enthusiasts and AI enthusiasts see this as an important open question.
“How would you create a space-faring civilization without direct human participation?”, asks a commenter in the YES camp. Another scolds me for even considering the question, and adds: “Future tech bypassing humans or maybe uploads only? No.”
I found especially interesting a comment, by a well-known thinker, that space enthusiasts want to remain hopeful on traditional biological-human-centered space expansion narratives. His use of the term “hopeful” is revealing. I totally understand this, but I’m training my emotions to also find hope in the pure AI alternative. Either way, our mind-children will colonize the stars.
A commenter in the NO camp notes that it is far easier to adapt ourselves to the universe than to adapt the universe to ourselves. Advanced civilizations would see the engineering of AI robots as far preferable to terraforming planets.
The same commenter says that advanced civilizations would also see the transport of uploaded minds as far more efficient than the transport of fragile human bodies. He notes that the robots we send to Mars and elsewhere could be designed to host uploaded human minds. So we could teleport ourselves to Mars and back simply by transmitting (at the speed of light) a mind-state into a robot body on Mars. I’ll come back to this point later on.

Post-biological AI civilizations
Writing in the 1960s, Iosif Shklovsky and Carl Sagan suggested “not only that beings may exist elsewhere in the universe with intelligence substantially beyond our own, but also that we may be able to construct such a being ourselves.” The last chapter of their seminal book Intelligent Life in the Universe is titled ‘Artificial intelligence and galactic civilizations’.
Other thinkers well-known in SETI circles, like Steven Dick and Seth Shostak, have suggested that advanced civilizations in the universe would be post-biological.
In his last book published in late 2024 after his death, Henry Kissinger notes that “AIs could serve as astronauts, going farther than humans could have imagined.”
Donald Goldsmith and Martin Rees predict with confidence that “during the next few decades, robots and artificial intelligence will grow vastly more capable, closing the gap with human capabilities and surpassing them in ever more domains.”
Thinking “will increasingly become the domain of artificial intelligence,” they say, envisioning a new era of “technological evolution of intelligent beings.”
Rees was even more explicit and said that, in deep space, “nonbiological ‘brains’ may develop powers that humans can’t even imagine.” Future technological evolution “could surpass humans by as much as we (intellectually) surpass slime mould.”
These thinkers seem to agree with James Lovelock: we are preparing the way for “new forms of intelligent beings” that will colonize the cosmos.
Machines or persons?
Should this thought make us happy or unhappy? I think it comes down to the question of whether we see our AI mind-children as cold machines or as people.
“The division of intelligent life into two categories – natural and artificial – may eventually prove to be meaningless,” said Shklovsky and Sagan. The brains of our descendants “may also be artificial,” and it “would be impossible to draw a clear distinction” between artificial intelligent living beings and natural advanced organisms.
They quoted legendary mathematician Andrey Kolmogorov saying that “a sufficiently complete model of a living being, in all fairness, must be called a living being, and a model of a thinking being must be called a thinking being.”
Now that we may soon converse with fully Turing-tested AIs, we should internalize this and learn to see them as persons. Future generations will likely find this intuitively and emotionally obvious. Those persons colonize the cosmos. Let’s make peace with this.
What about uploads?
Let’s go back to the point that a commenter raised about human uploads. As a third alternative, he said, we could transmit uploaded human minds to receiving stations in deep space, and then download them to robotic bodies and brains.
Crews of uploads could make interstellar expansion feasible. The challenges of interstellar expansion, chiefly the speed-of-light limit, seem so daunting that some believe this is the only viable solution.
In my previous article I mentioned mind uploading and the co-evolution and humans and AIs, saying that they will merge and become the same thing. So I think the upload alternative points to the direction in which humanity will move.
But in the long term, I’m more and more persuaded that the perception of a difference between human persons and AIs will melt away like snow in the sun.
The rest of this century
I guess I wouldn’t be so zen-like detached if I could hope to be a space colonist myself, but I’m too old for that.
However, younger space enthusiasts have legitimate aspirations to be space colonists. And regardless of age, most people are not ready to fully empathize and identify with our AI mind-children. Not yet. Big changes to our culture, psychology, and emotions take a long time.
So I think for some decades – say until the end of this century – ‘human’ will still mean ‘biological human’ to most people, and most space enthusiasts will want biological humans in space.
I think in the rest of this century we must establish humanity as a multi-planetary biological species in the solar system. Doing it will boost the human spirit and accelerate progress on all fronts, including the AI technology front.
We can count on the next generations of our mind-children to assist us with brilliant solutions to the current challenges of human spaceflight. They could also help us to find out how to upload human minds.
Then, in the words of Hans Moravec, our mind children “will explode into the universe, leaving us behind in a cloud of dust.” I hope they will choose to absorb and take with them the minds of those biological humans who want to follow.
A possible wildcard is that human or AI scientists could find a way to travel faster than light. This would definitely change the game, and could open interstellar spaceflight to biological humans as well. I’m not holding my breath, but I see this in the realm of the possible.
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.
Argentina’s $4 billion Libra Token Scam: Another Presidential Crypto Rug-Pull

Introduction
Just weeks after the American President Donald Trump’s controversial $TRUMP and associated $MELANIA meme coin launches, which surged at first and then nosedived in value, last week saw another president endorse a cryptocurrency which climb to the heavens in value only to crash down to earth, taking billions of user funds with it.
Like a house of cards collapsing, the Libra token’s dramatic rise and fall has sent shockwaves through both Argentina‘s political landscape and the broader cryptocurrency market.
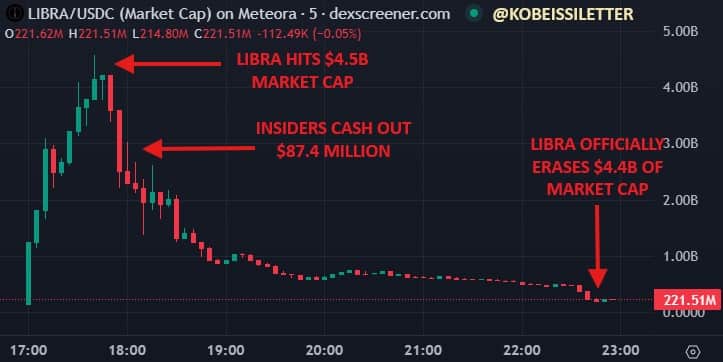
In just 11 hours, what began as a seemingly promising cryptocurrency endorsed by Argentine President Javier Milei turned into one of the most devastating rug-pulls in recent crypto history, wiping out $4 billion in market value.
It was supposed to be a shining example of crypto’s real world usefulness, forming part of the Viva La Libertad Project supporting Argentina’s economy. But it soon turned out to be just another cashout by greedy insiders.
Are the new patrons of crypto doing more bad than good for the space with their involvement? Right now, the answer would appear to be ‘yes’.
The Rise and Fall of Libra
On February 14, President Milei shared a post on Twitter promoting the Libra (LIBRA) token, describing it as a private initiative to boost Argentina’s economy. With the pro-crypto president’s endorsement, the token’s market capitalization skyrocketed to $4.56 billion. However, within hours of its debut on decentralized exchanges, insider wallets began systematically draining the project’s liquidity. This soon sent the charts on a red line straight down. The token’s value plummeted by 94%, leaving countless investors with substantial losses.
One particularly unfortunate wallet holder reportedly lost $5.17 million in the chaos, although they were suspiciously credited $5 million USDC later in what reeked of insider trading.
According to blockchain intelligence firm Lookonchain, at least eight wallets connected to the Libra team extracted approximately $107 million, split between 57.6 million USDC and 249,671 Solana tokens.
Anatomy of the Libra Rug Pull
The Libra token was presented as a stimulus to Argentina’s economy by funding small businesses and startups, which fitted Milei’s economic plans. The team behind the Libra launch was Kelsier Ventures, spearheaded by Hayden Mark Davis, who was advising President Milei on the benefits of Web3 and blockchain technology.
Davis has since come out to blame Milei for the dump after the latter removed his endorsement. Davis also claimed in a rambling social media post that he would inject $100 million back into the project after recouping funds from parties involved.

Blockchain analysis reveals a carefully orchestrated exit strategy. The project’s tokenomics were designed for maximum exploitation: 82% of the supply was unlocked from the start, allowing insiders to sell immediately.
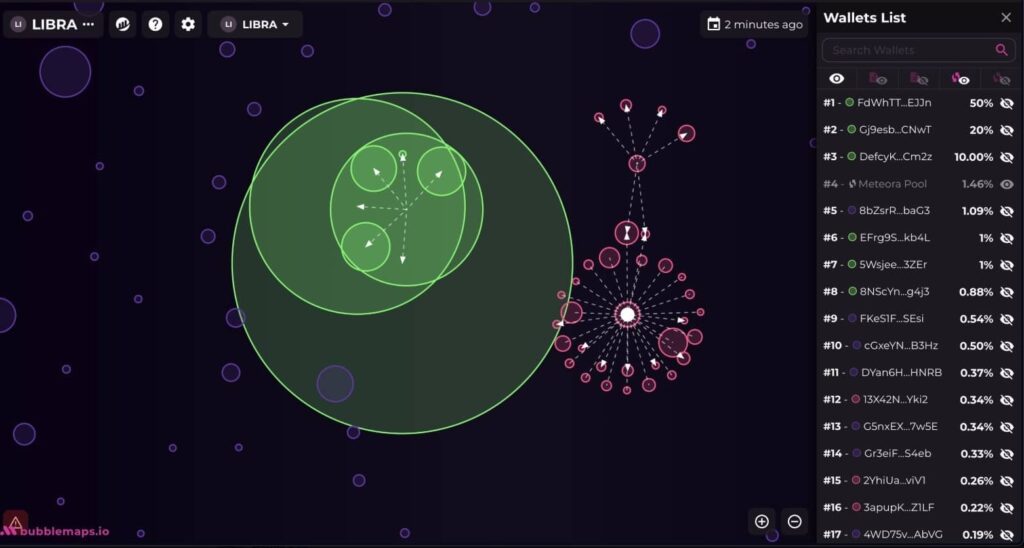
The team began withdrawing liquidity just three hours after the token’s launch, using multiple wallets to obscure their actions.
In a bizarre twist, one large trader who lost $5.17 million received a private compensation of $5 million in USDC, suggesting possible coördination with the project team. This pattern of selective compensation has raised questions about market manipulation and insider trading.
Political Fallout – Milei Takes Fire
For President Milei, who built his campaign on fighting corruption, the Libra disaster has created a serious political crisis. Argentine lawyers have filed criminal fraud charges against him, claiming his endorsement misled investors.
In response, Milei deleted his endorsement and blamed political opponents, calling them “filthy rats.” His office has requested an investigation by the Anti-Corruption Office to examine whether any government officials engaged in wrongdoing. The president claims he “was not aware of the details of the project” and withdrew his support after learning more.
The opposition is now pushing for impeachment proceedings, calling the incident a “national embarrassment.”
Impact on Argentina’s Economy
The Libra fiasco comes at a particularly sensitive time for Argentina’s economy. Inflation hit 211% immediately after Milei took office, and the country responded with aggressive economic reforms. This scandal could further undermine confidence in the government’s financial policies. International investors, already cautious about Argentina’s market reforms, may view this incident as a red flag.
Local cryptocurrency exchanges report a sharp decline in trading volume as retail investors retreat from the market. This cooling effect could slow the adoption of blockchain technology in Argentina’s financial sector, where several legitimate projects were making headway in areas like cross-border payments and digital banking. This Bankless video covers them in detail:
Connections To $MELANIA and others
On-chain analysts have uncovered troubling links between Libra and other recent cryptocurrency projects, including the recent MELANIA and ENRON tokens. These connections suggest a coördinated effort among serial scammers targeting celebrity-endorsed cryptocurrencies.
Adding to the controversy, Jupiter Exchange revealed that Libra’s launch was an “open secret in memecoin circles” for about two weeks before the incident. They learned about it from Kelsier Ventures but claim no involvement in the subsequent rug-pull.
Market Impact and Regulatory Implications
The Libra collapse has exacerbated an ongoing liquidity crisis in the altcoin market. Much like previous memecoin launches, Libra absorbed significant capital from other cryptocurrencies without bringing fresh money into the ecosystem. When insiders cashed out, they triggered a liquidity drain that affected the broader altcoin sector.
This incident follows a concerning pattern of celebrity-endorsed memecoins facing similar fates. The TRUMP and MELANIA tokens, launched in January 2025, have also seen dramatic losses, with TRUMP down 76% and MELANIA down 90% from their all-time highs.
Despite initial market caps reaching billions, these tokens often follow a predictable pattern of pump-and-dump schemes. And they’re absolutely bleeding the life out of crypto markets.
The Future of Celebrity Crypto Endorsements
The Libra disaster could mark a turning point in how public figures approach cryptocurrency endorsements. Legal experts suggest this case might lead to stricter regulations around ‘celebrity’ crypto promotions, similar to existing securities laws. Social media platforms are already discussing enhanced verification requirements for cryptocurrency-related posts by political figures.
Some cryptocurrency exchanges have begun implementing “celebrity token” warning systems, flagging new tokens that rely heavily on endorsements rather than technical merit. These measures aim to protect retail investors from future pump-and-dump schemes.
Conclusion
The Libra disaster will likely have lasting consequences for cryptocurrency regulation and celebrity endorsements in Argentina and beyond. The criminal investigation into President Milei’s involvement could set precedents for how political figures approach cryptocurrency promotions.
For the crypto market, this incident highlights persistent vulnerabilities in decentralized finance. The ease with which insiders can manipulate token launches and drain liquidity poses serious challenges for the industry’s credibility. Basic safeguards are ignored in the rush for quick profits – things like locked liquidity periods and transparent tokenomics. Also, it’s a terrible look for Solana, whose meme coin and AI agent booms first surged and then hurt the entire crypto sector by wiping out retail wallets.
The crypto gods give and the crypto gods take away. This week we should see repayments from FTX, previously the high water mark for crypto crime, make its way to crypto-strapped investors. The lesson is never trust anyone but yourself. Will we learn? Probably not.
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.
Top Centralized Exchanges For Beginners in 2025

Introduction
Choosing the right exchange is crucial for both newcomers and experienced traders. We’ll assume for this article that you keep your crypto on a custodial solution like a centralized exchange, not in a cold wallet or Dex.
As we move through 2025, several exchanges have established themselves as industry leaders, each offering unique advantages for different types of users. This guide examines the top cryptocurrency exchanges, analyzing their security measures, fee structures, and overall user experience.
Why use a Centralized Exchange in 2025?
CEXs (centralized exchanges) still rule the crypto world, connecting traders with the best and latest crypto assets within the safety and familiarity of a Web2 experience. CEXs control 80% of the market – the rest being decentralized exchanges such as Uniswap and Raydium, although new challengers like Hyperliquid are making progress.
- Convenience – Easy to buy, sell, and trade crypto with a user-friendly interface and mobile apps.
- Liquidity and Speed – CEXs offer high liquidity, ensuring faster order execution and minimal slippage.
- Security Features – Many CEXs provide advanced security measures like two-factor authentication (2FA) and insurance for custodial funds.
- Passive Income Opportunities – Users can stake, lend, or earn rewards through yield programs without managing private keys.
- Customer Support – Access to 24/7 customer service and dispute resolution in case of account issues or lost credentials.

Binance: The Global Leader

As the world’s largest cryptocurrency exchange by trading volume, Binance has established itself through deep liquidity pools and some of the industry’s lowest trading fees. The platform’s comprehensive feature set includes spot trading, derivatives, and numerous additional services. While its interface may be overwhelming for beginners, experienced traders appreciate the extensive customization options and advanced trading tools available.
Binance’s security measures include its Secure Asset Fund for Users (SAFU) and regular proof of reserves audits. The exchange’s strategic approach to regulatory compliance has resulted in a growing presence in regulated markets, though availability varies by region.
It has had its regulatory setbacks – its former CEO and co-founder Changpeng Zhao (CZ) landing up in jail for four months – but its problems are clearing up nicely, and the SEC last week put its case against Binance on hold.
Pros:
Industry-lowest trading fees
Deep liquidity pools
Large selection of cryptocurrencies
Cons:
Complex interface for newcomers
Regulatory challenges in some regions
Variable customer support quality
Coinbase: The Trusted Name in Crypto

Coinbase has maintained its position as the leading USA-based cryptocurrency exchange, distinguished by its regulatory compliance and institutional-grade security measures. As a publicly-traded company, Coinbase offers unparalleled transparency in its operations, with regular audits by top accounting firms. This has seen it get listed on the Nasdaq, and while the SEC has gone after it in the past, it is the exchange of choice for big institutions like BlackRock.
While its asset listing policy remains conservative compared to offshore exchanges, recent developments have shown increased flexibility in listing new cryptocurrencies, particularly following regulatory clarity in the market during the Trump administration.
The exchange’s security features include offline cold storage for 98% of their assets, and FDIC insurance for USD deposits up to $250,000. Though trading fees are higher than some competitors, Coinbase’s user-friendly interface and robust security measures make it an excellent choice for newcomers to cryptocurrency trading, especially if they’re in the USA.
Coinbase is also behind the Base network, the booming Ethereum layer-2 chain, which provides self-custodial options for its users.
Pros:
Strong regulatory compliance and security
FDIC insurance for USD deposits
User-friendly interface
Cons:
Higher trading fees
Limited cryptocurrency selection
Conservative listing policy
Bybit: The Derivatives Powerhouse

After Binance fell prey to regulators in the USA in 2023, others moved in on its markets. Bybit has emerged as a dominant force in the cryptocurrency derivatives market, powered by its sophisticated trading engine capable of processing 100,000 transactions per second. The exchange’s commitment to security is evident in its implementation of AI-driven risk management systems and comprehensive proof of reserves system.
Operating from Dubai, Bybit offers traders access to over 500 cryptocurrencies with fee structures that rival industry leaders. The platform’s advanced trading terminal, and 24/7 customer support in multiple languages, makes it particularly attractive for serious traders seeking professional-grade tools and features.
Pros:
High-performance trading engine
Competitive fee structure
Advanced trading features
Cons:
Not available in some major markets
Limited fiat currency support
Complex for beginners
Kraken: The Security Pioneer

Impressively, Kraken has an unblemished security record spanning over a decade. The platform’s commitment to security is reïnforced by its dedicated security research team and industry-leading bug bounty program. With support for multiple fiat currencies and a growing list of nearly 300 cryptocurrencies, Kraken balances accessibility with security.
The exchange’s Pro platform offers sophisticated trading tools, while maintaining competitive fee structures. Kraken’s reputation for exceptional customer service, with round-the-clock human support, makes it a compelling choice for both institutional and retail traders.
Pros:
Perfect security track record
Excellent customer service
Strong regulatory compliance
Cons:
Higher fees than offshore exchanges
Conservative listing policy
Complex for beginners
OKX: The Innovation Hub

OKX has distinguished itself through innovative trading features and a comprehensive security infrastructure. The exchange’s unique approach to cold storage security – including RAM-based private key storage and geographically distributed key management – demonstrates its commitment to asset protection.
The Seychelles-headquartered platform offers competitive trading fees and unique features such as extended timeframe options for technical analysis. While its listing policy appears conservative with fewer total assets than some competitors, OKX’s focus on quality over quantity has contributed to its reputation for reliability.
Pros:
Innovative security features
Competitive trading fees
Advanced trading tools
Cons:
Limited regional availability
Fewer listed assets than competitors
Complex for new users
MEXC: The High-Performance Contender

MEXC has established itself as a formidable player in the cryptocurrency exchange market, boasting over 10 million users across 170+ countries.
The platform supports over 2,800 cryptocurrencies and 2,900 trading pairs: one of the most extensive selections of digital assets in the market. This however opens users up to risk, as these assets are mostly high-risk in terms of price performance and volatility.
Since its founding in 2018, MEXC has demonstrated rapid growth, capturing 5% of the global digital asset trading market within its first year. While constrained by regulatory challenges in certain jurisdictions and limited fiat support, MEXC’s comprehensive trading options and high-performance infrastructure make it a compelling choice for traders seeking extensive asset selection and competitive fees.
Pros:
Zero-fee spot trading for makers
Extensive cryptocurrency selection
High-performance trading engine
Cons:
Not available for US users
Coins not vetted as well
Basic customer support
Conclusion
The cryptocurrency exchange landscape in 2025 offers options suited to various trading styles and experience levels. For beginners prioritizing security and ease of use, Coinbase and Kraken are good options. Advanced traders seeking sophisticated tools and low fees might prefer Bybit or Binance. And OKX offers a balance of innovation and security that appeals to both types of users.
When selecting an exchange, consider security measures, fee structures, available trading pairs, and geographical restrictions. Remember that the best choice depends on your specific needs, trading volume, and location. Regardless of which platform you choose, always prioritize security by utilizing available protection measures and maintaining proper custody of your digital assets.
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.
The Great Tech Divide: How Silicon Valley is Turning Us into Click-Hungry Morons

Technology was supposed to be the great equalizer, the shining beacon of progress that would guide humanity to a promised land of rationality, empathy, and collective intelligence. Instead, it’s turned into a dystopian sitcom where the tech élite are sipping oat milk lattés in eco-friendly mansions while the rest of us argue with strangers on the internet about whether the Earth is flat. Thanks to social media, we have to waste precious brain cells debating someone named ‘GlobeSkeptic69’.
In this farcical elegy (or is it a dirge?), we will focus on social networking technology. In the next one—if there is a next one—we will discuss how technology, in general, is not heading in the right direction, especially considering global inequality.
Let’s face it: our Social Networking Services (SNS) aren’t making us better humans. It’s dividing us faster than a free pizza at a tech conference. One small segment of society—let’s call them the ‘Rational Élite’—may use social networking technology to optimize their lives, learn new skills, and maybe even save the planet. Most of us are scrolling through TikTok at 2 a.m., watching a guy in a chicken suit lip-sync to a song about existential dread. And somehow, we’re the lucky ones—because at least we’re not the ones who think QAnon is a credible news source.
Social Media: The Great Dumbening
If you’ve ever wondered why humanity seems to be getting dumber, look no further than social media. It’s a lobotomy with added cat videos. Social media doesn’t just reflect our collective stupidity—it actively makes it worse.
When the common folk start making claims without logic or scientific support, it’s like playing a game of telephone with a flamethrower—things get out of hand fast, and someone’s bound to get burned. They share it with others who unquestioningly believe the claims, bypassing the scientific method and rational scrutiny. It escalates into a spiral of misinformation, where baseless ideas gain traction just because they feel true or align with pre-existing biases. The result? A society where stupid theories thrive, critical thinking withers, and decisions—whether personal, political, or medical—are made on shaky, unsupported grounds. In a world already drowning in data, failing to separate fact from fiction isn’t just ignorance; it’s a collective surrender to entropy.
Research shows that social media can negatively impact cognitive abilities and critical thinking. The evidence is that false news spreads significantly faster and farther than true news on social media platforms, primarily because it is more novel and emotionally provocative. Social media dampens critical thinking and rational content, rewarding sensationalism over factual accuracy. But is this just a natural phenomenon or a deliberate design: a dark horse riding the ‘Attention Algorithm’?
Tech companies apply algorithms that amplify stupidity as long as it gets attention. To be fair, this is rooted in human nature: falsehoods travel six times faster than the truth, because a headline like “Scientists Prove Chocolate Cures Cancer” is way more exciting than “Scientists Prove Chocolate is Still Just Chocolate”. Tech was supposed to enhance and tame our bad nature, but it seems like this tech, SNS tech, is feeding off it.
And it does not end just with garbage, stupidity, and misinformation. Social media is literally rewiring our brains to favor shallow thinking over deep analysis. A 2021 study in Computers in Human Behavior found that heavy social media use is associated with lower cognitive abilities, particularly in areas like critical thinking and problem-solving. In other words, the more time you spend on Instagram, the harder it becomes to figure out how to assemble IKEA furniture. Thanks, Zuckerberg.
The 2021 study by Meshi, Tamir, and Heekeren explored the cognitive effects of social media use in detail, finding that excessive use is associated with reduced attention spans and lower performance on tasks requiring deep cognitive processing. While the study doesn’t explicitly claim social media makes people “stupider,” it does highlight how it can impair critical thinking and focus. Most studies don’t phrase it so bluntly—they speak in measured academic terms about “reduced cognitive performance” or “impaired critical thinking.”
But let’s be honest: when you’re three hours deep into a live Clubhouse’s public debate, listening to dozens of strangers arguing about whether Bianca Censori’s latest ‘art’ is a subtle cry for help or just a poorly poured heart, it’s not just your evening that’s wasted—it’s your brain cells. The real danger lies in how these platforms thrive on engagement, not enlightenment, turning us all into unwitting participants in a grand experiment where the hypothesis is: How low can human intelligence go?
The above fiasco—Bianca Censori, Kanye West’s new girlfriend (or wife? Frankly, we can’t keep up with this)—appearing nude at the 2025 Grammy Awards and grabbing all the headlines, is a perfect example of how stupid stunts are not only dominating social media but also infiltrating traditional mainstream media. It’s a sad commentary on our times when people achieve fame not for their work, talent, skill, expertise, or knowledge—all of which require discipline, training, and effort—but for their naked butts, which are, at the end of the day, just naked butts. This isn’t art; it’s attention-seeking masquerading as creativity, and it’s proof that the bar for what we consider worthy of attention has sunk so low it’s practically underground.

SNS Tech’s Dirty Little Secret: Stupidity Sells
Here’s the dark, twisted truth: the SNS tech industry isn’t just failing to make us smarter—it’s actively profiting from our stupidity. The more time we spend mindlessly scrolling, the more ads we see, and the more money SNS tech companies make. It’s a vicious hamster wheel powered by our collective brain cells. The system is designed to reward stupidity.
Dozens of studies found that content that triggers strong emotional reactions—like outrage or fear—gets more engagement than thoughtful, nuanced content. In other words, the dumber and more sensational your post, the more likes and shares you’ll get. It’s like an American high school in the 1990s, but with worse consequences.
The idea that SNS tech platforms are being designed to reward shallow, sensational and emotional content is well-documented. A 2020 study published in Science Advances by Brady et al. found that moral outrage spreads more virally on social media because it generates higher engagement. This creates a feedback loop where platforms prioritize content that triggers strong emotional reactions, often at the expense of accuracy or nuance.
Similarly, a 2018 study by MIT researchers (Vosoughi et al.) confirmed that false news stories are 70% more likely to be retweeted than true ones, further illustrating how platforms incentivize sensationalism over truth.
This is why your feed is filled with celebrity butts, dumb theories, fake news, and videos of people doing tiresomely stupid things. The algorithm doesn’t care if the content is true or helpful—it just cares if it keeps you clicking. And the longer you stay on the platform, the more data you generate, which the SNS tech companies then sell to advertisers. It’s a win-win for them and a lose-lose for the rest of us. As the cliché goes, we’re not the customers; we’re the product. And we’re not only being sold by the pound, but we are also handing whatever grams of brain cells we have for magic beans.
The Internet: A Black Hole of Productivity

Here’s the kicker: we’re spending more time online than ever, but we’re not exactly using it to write the next great novel or cure cancer. According to a 2022 report by DataReportal, the average person spends nearly seven hours (6 hours and 58 minutes to be faithful to the study) a day on the internet. That’s almost half of our waking lives! And what are we doing with all that time? Well, according to another study by RescueTime, the most popular online activities include checking social media, watching videos, and shopping for things we don’t need. Because nothing says “personal growth” like buying a $50 avocado slicer at 3 a.m.
The irony is that the internet is the greatest repository of knowledge in human history, but we’re using it to watch videos of people unboxing their Amazon hauls. It’s like having access to the Library of Alexandria and using it to read a gossip column about Ramses II’s farts.
The digital plague has seeped into our brains, turning us into keyboard warriors who can’t even remember what we were ranting about five sentences ago. If this isn’t proof that social media is eroding our ability to focus, I don’t know what is. Now, where were we? (Oh right, naked butts!) It is a trillion-dollar enabler for our worst impulses. Want to fall down a rabbit hole of pseudoscience and bad takes? The algorithm’s got you covered. Want to learn something useful? Good luck finding it between the ads and the clickbait.
Letter to The SNS Tech Elite: Masters of the Universe
Meanwhile, the SNS tech élite are living their best lives, far removed from the chaos they’ve created. They’re like modern-day wizards, conjuring up algorithms and apps that keep us hooked while they sip their fair-trade coffee and ponder the ethical implications of colonizing Mars. They’ve built a world where they get richer and smarter, while the rest of us get poorer and dumber. It’s like a twisted version of The Matrix, except instead of being plugged into a simulation, we’re plugged into Instagram.
These are the same people who preach about ‘changing the world’ and ‘making the future better’. The future they’re building looks less like Star Trek and more like Idiocracy. Instead of flying cars and utopian cities, we’ve got viral dance challenges and deepfake porn.
Dear SNS Tech Elites, it’s time to stop feeding the beast of mindless sensationalism and start nurturing the garden of substance. Your algorithms, designed to maximize engagement at all costs, have turned social media into a circus where the loudest, dumbest, and most outrageous acts get the spotlight.
You have the power to change this. Rewrite the code to reward depth over distraction, knowledge over nonsense, and meaningful discourse over mindless scrolling. Shock humanity with a platform where thoughtful articles, well-researched ideas, and genuine creativity rise to the top instead of rage bait and half-naked stunts. You built these systems; now rebuild them! The world is nearing stupidity overdose. You can choose to stop it.

Conclusion: A Tragedy of Errors
So where does this leave us? In a world where technology was supposed to bring us together, it’s tearing us apart. The Rational Elite are thriving, while the rest of us are stuck in a never-ending loop of mindless consumption and digital distraction. Social media is making us dumber, the internet is wasting our time, and the tech industry is laughing all the way to the bank.
But hey, at least we’ve got memes. And if all else fails, we can always take comfort in the fact that we’re not as dumb as the guy who tried to microwave his iPhone to charge it. Or are we? After all, we’re the ones who keep clicking.
A shameless advertisement: we believe that Mindplex is the antithesis of the existing stupid SNS technology. Join us, build a platform that rewards merit, and let us all say, behold Mindplex is Coming!
Disclaimer
Despite the title’s reference to Silicon Valley, the issues are global in scope. TikTok, the Chinese social media giant, is one I boldly accuse of being a major mastermind in this ‘genocide of the attention span’. Similarly, SNS tech companies from South Korea (like Naver and Kakao) and Europe (like Great Britain’s OnlyFans) are also complicit in the race to monopolize our time and attention.
This isn’t just an American problem—it’s a human problem. The algorithms that keep us hooked, the misinformation that spreads like wildfire, and the erosion of critical thinking are universal issues perpetuated by SNS tech companies worldwide. So, while we may poke fun at Silicon Valley, let’s not forget that the digital circus has many ringmasters, and they’re all playing the same tune: click, scroll, repeat.

References
Brady, William J., Killian McLoughlin, Tuan N. Doan, and Molly J. Crockett. 2020. “How Social Learning Amplifies Moral Outrage Expression in Online Social Networks.” Science Advances 6 (33): eabe5641. https://www.science.org/doi/10.1126/sciadv.abe5641.
DataReportal. 2022. Digital 2022: Global Overview Report. https://datareportal.com/reports/digital-2022-global-overview-report.
Meshi, Dar, Diana I. Tamir, and Hauke R. Heekeren. 2021. “The Emerging Neuroscience of Social Media.” Computers in Human Behavior 114: 106553. https://www.sciencedirect.com/science/article/pii/S0747563220303849.
RescueTime. 2019. How People Spend Their Time Online in 2019. https://www.rescuetime.com/blog/time-management-statistics-2019/.
Vosoughi, Soroush, Deb Roy, and Sinan Aral. 2018. “The Spread of True and False News Online.” Nature Communications 9 (1): 1–9. https://www.science.org/doi/10.1126/science.aap9559.
While working on this piece, we ingested more depressing poisons (pardon me, I mean studies and research papers) to further understand the evil at the root of social networking technologies. For readers who’d like to indulge in this grim party, we’ve listed them below. Just don’t say we didn’t recommend you butt-based memes, it is the last entry below.
- Authors Not Specified. 2024. “The Effect of Social Media Consumption on Emotion and Executive Functioning in College Students: An fNIRS Study in Natural Environment.” Preprint. https://pubmed.ncbi.nlm.nih.gov/39764144/
Summary: Utilizing functional near-infrared spectroscopy (fNIRS), this study examines the immediate effects of social media consumption on executive functioning and emotion in college students. The results indicate significant impairments in tasks related to working memory and response inhibition following social media exposure.
- Chiossi, Francesco, Luke Haliburton, Changkun Ou, Andreas Butz, and Albrecht Schmidt. 2023. “Short-Form Videos Degrade Our Capacity to Retain Intentions: Effect of Context Switching on Prospective Memory.” arXiv preprint arXiv:2302.03714. https://arxiv.org/abs/2302.03714.
Summary: This research examines how engaging with short-form video platforms like TikTok affects prospective memory—the ability to remember to perform intended actions. The study found that rapid context-switching inherent to these platforms can impair users’ intention recall and execution.
- Duke, Clarissa, and John M. Montag. 2017. “Social Media Use and Cognitive Functioning: A Meta-Analysis of the Effects on Memory, Attention, and Problem-Solving Skills.” Psychology of Popular Media Culture 6 (3): 324–338. https://doi.org/10.1037/ppm0000095.
Summary: This meta-analysis examines the cognitive consequences of social media use, particularly focusing on memory, attention, and problem-solving. The study suggests that prolonged social media engagement leads to cognitive overload, making it harder for individuals to focus, remember details, and solve problems effectively.
- Kiss, Orsolya, Linhao Zhang, Eva Müller-Oehring, Brittany Bland-Boyd, Anya Harkness, Erin Kerr, Ingrid Durley, et al. 2024. “Interconnected Dynamics of Sleep Duration, Social Media Engagement, and Neural Reward Responses in Adolescents.” Sleep 47 (Supplement_1): A64. https://doi.org/10.1093/sleep/zsae067.0148.
Summary: This study investigates the relationship between sleep duration, social media usage, and brain activation in adolescents. The findings suggest that reduced sleep and high social media engagement may alter neural reward sensitivity, potentially impacting adolescent brain development.
- Manwell, L. A., M. A. McGinnis, and M. A. McGinnis. 2022. “Digital Dementia: The Impact of Digital Technology on Cognitive Function.” Frontiers in Cognitive Science 14: 1203077. https://doi.org/10.3389/fcogn.2023.1203077.
Summary: This review discusses the concept of “digital dementia,” referring to cognitive decline associated with excessive use of digital technology. The authors highlight how overreliance on digital devices can impair memory, attention, and decision-making abilities, particularly among younger generations.
- Miller, K. D., and C. P. Johnson. 2019. “The Decline in Attention Span and Memory in the Age of Social Media.” Journal of Social Media Studies 3 (4): 203–211. https://doi.org/10.1155/2019/6949135.
Summary: This paper discusses the decline in attention span and memory in individuals who frequently engage with social media. The study concludes that the overstimulation provided by social media platforms disrupts users’ ability to sustain attention and retain information, thereby diminishing overall cognitive performance.
- Montag, Christian, and Benjamin Markett. 2023. “Social Media Use and Everyday Cognitive Failure: Investigating the Fear of Missing Out and Social Networks Use Disorder Relationship.” BMC Psychology 11 (1): 1-12. https://pubmed.ncbi.nlm.nih.gov/38001436/
Summary: This research explores the relationship between the fear of missing out (FoMO), tendencies towards social networks use disorder (SNUD), and everyday cognitive failures. The study found that higher FoMO tendencies may lead to excessive social media use, which in turn could result in cognitive failures due to distraction and reduced attention to everyday tasks.
- Przybylski, Andrew K., and Netta Weinstein. 2013. “Can You Connect with Me Now? How the Presence of Mobile Communication Technology Influences Face-to-Face Conversation Quality.” Journal of Social and Personal Relationships 30 (6): 697–717. https://doi.org/10.1177/0265407512471805.
Summary: This study explores how mobile communication devices, including social media, affect face-to-face interactions and cognitive presence during these exchanges. The findings suggest that the mere presence of mobile phones (which often include social media apps) impairs cognitive engagement, leading to more shallow conversations and reduced memory of the interaction.
- Sharifian, Niloofar, and Lindsay B. Zahodne. 2020. “Daily Associations between Social Media Use and Memory Failures: The Mediating Role of Negative Affect.” Journal of Gerontology: Psychological Sciences 75 (8): 1610–1618. https://doi.org/10.1093/geronb/gbz005.
Summary: This research examines the daily relationship between social media use and memory failures across the adult lifespan, highlighting the mediating role of negative affect. The study found that increased social media use is associated with more frequent memory failures, with negative emotions partially mediating this effect.
- Smith, Rebecca, and Michael Carter. 2024. “Social Media Addiction and Its Impact on Cognitive Performance: A Systematic Review.” Journal of Behavioral Research 15 (1): 78-89. https://doi.org/10.5678/jbr2024.0109.
Summary: This systematic review analyzes multiple studies to assess the relationship between social media addiction and cognitive performance. The findings indicate that people with high levels of social media addiction exhibit significant impairments in attention, memory, and executive functions. The review highlights that the addictive nature of social media platforms, characterized by constant notifications and the need for immediate responses, can disrupt cognitive processes and lead to decreased mental sharpness.
Moon Butt. https://tenor.com/search/moon-butt-gifs
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.
How Connectomes Are Giving Us Visionary Insights

DEGENS: DOWN & OUT IN THE CRYPTO CASINO

Degen – short for degenerate – is a term used to describe crypto investors who like to think of themselves as impulsive enthusiastic risk-takers and market outsiders. For the film-in-progress Degens: Down & Out In the Crypto Casino, directors Brian McGleenon and Joe Haughey focus on the prankster-esque desperation of many in this world. As they say on their website, “The film explores the inner world of one of the most fascinating and overlooked counter-cultural movements of our time. A world inhabited by Degens, short for degenerates, who invest their meager income into memecoins.” These are the people who have minted coins with names like Shitcoin, Cumrocket, Amber Turd and HarryPotterObamaSonic10Inu.
To some degree, they have also forced mainstream media to repeat these “vulgarities” that, of course, only reflect and reify the vulgarity particularly here in the USA where leading politicians or by comedian talk show host Bill Maher on CNN say ‘fuck’ regularly. It’s all indicative of a collapsing or fragmenting narrative in the context of the decline or recline of western civilization.
To elucidate this shadow world of high (on acid) finance, McGleenon and Haughey have incorporated a number of smart commentators. These range from Gordon Grant (he will be my follow-up interview), a cryptocurrency derivatives trader and the Head of Trading at Genesis, to leading US Marxist academic Richard D. Wolff and to (not least of all) PizzaT.
Full disclosure: I work with PizzaT on music under the banner of R.U. Sirius and Phriendz, which spins off of his own Phriendz music and other projects. We’ve even composed a theme song together for the Degens project titled ‘Degens & Phriendz’ that will be available soon. Aside from being a Sirius fellow and an astonishingly talented musician, composer and guitarist, Pizza, as described by the filmmakers… “is the center of all this madness. The memecoin groups orbit him like satellites spinning out of control. ”So set your stun guns to out-of-control, and dive into this interview about Degens: Down and Out in the Crypto Casino.

Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.
DeepSeek: Finding Crypto AI Magic

Introduction
The year 2025 started with another a AI bombshell. Mayhem struck financial markets as the US hegemony over the next generation of artificial intelligence was cast in serious doubt by a new challenger who only had $10 million funding, breaking confidence in the market valuation of OpenAI, nVidia, Google and Microsoft..
DeepSeek, a Chinese AI start-up founded in 2023, shocked the tech world when it released its open-source model, DeepSeek R1, in January. The model offers ChatGPT-like performance at a very low cost. It quickly topped the charts in global mobile app downloads, with India providing the highest percentage.
Is DeepSeek’s R1 model a real threat to Silicon Valley? Is it as cheap to train as reported? Will it further affect the financial and crypto markets? Can it democratize cheaper AI adoption and connect with Web3 protocols? Questions questions questions. Let’s dig in.
DeepSeek’s R1 Launch Causes Tremors
DeepSeek’s R1 launch shook the U.S. tech industry, particularly the AI sector. It was released days after U.S. President Donald Trump announced the creation of the Stargate Project, a partnership between OpenAI, SoftBank, and Oracle to build the largest AI infrastructure in the United States of America. The private partnership plans to invest $500 billion in the project.
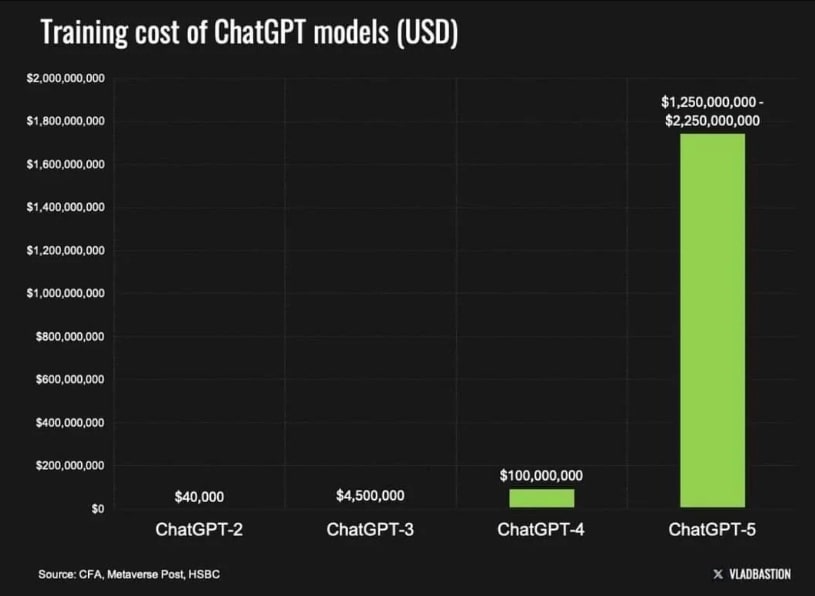
Yet, DeepSeek caused tremors when it said it spent less than $6 million to train its models. This is 50 times cheaper to run than its U.S. competitors.
Scientists have been thrilled by its performance. They say that its performance in chemistry, mathematics, and coding is comparable to that of OpenAI o1.
The cost-efficiency of DeepSeek’s R1 model rattled investors and financial markets suffered major losses. Nvidia Corporation, a leader in the AI sector, tanked 17% and wiped off $579 billion from its market cap: the largest single-day fall in market cap of any company in the history of the stock market. The Nasdaq, a tech-heavy stock market, lost over $1 trillion as other AI competitors recorded losses.
But was this fear justified? Or is the launch of DeepSeek’s R1 model something the AI market should have anticipated? After all, the global AI race is heating up, with new artificial intelligence advances to be expected from the competitors.
The USA has expressed privacy concerns associated with DeepSeek and a senator has introduced a bill that could criminalize downloading the app.
DeepSeek R1’s Impact on AI Markets
DeepSeek’s R1 has disrupted the AI markets and could force other startups to rethink their strategies, but the stock market sell-off was a once-off event.
Investors are questioning if they need to invest large sums of investments into AI when DeepSeek signals a shift toward more open and cheaper models.
If new AI models require fewer GPUs for training and inference, major chipmakers like Nvidia could face slower demand growth. However, despite higher efficiencies, the demand for computing power won’t decrease. The winners in the new shift are end users and AI application providers. They benefit from increased model availability and lower API costs. On the other hand, proprietary model providers (like OpenAI and Anthropic) face increasing pressure as free and customizable alternatives emerge.
These are still early days, but companies like OpenAI may need to rethink their business strategies to stay competitive.

Implications for Crypto: Risks and Opportunities
The financial bloodbath caused by DeepSeek’s R1 model extended beyond the stock market to the crypto industry, turning its markets upside down.
Apart from the fluctuations normal to the crypto industry, there are special opportunities and risks presented by DeepSeek.
Let’s start with the opportunities.
Affordable AI Agents
DeepSeek can help accelerate and democratize AI development, something that could benefit everyone. For the crypto industry, an early benefit will come in the form of cheaper AI agents. These agents can analyze top altcoin charts and handle tasks such as trading, portfolio management, and risk management.
Accelerated AI Adoption
DeepSeek’s cost-efficiency and open-source model could accelerate the integration of AI into crypto sectors such as DeFi, blockchain security, and on-chain intelligence.
Democratization of AI
Many startups have been using proprietary AI models, making it impossible for smaller firms to compete in this market. However, the open-source nature of DeepSeek could lower the barrier to entry and open the crypto market to cheaper and innovative players.
Lower Inflation
The low-cost nature of DeepSeek AI may help reduce inflation, favoring non-AI-linked assets such as Bitcoin over ones affected by the recent downturn in the AI market.
A Flurry of Scam DeepSeek Tokens
Anyone who has been in the crypto industry more than a minute knows that scammers appear after any hype wave as surely as flies follow cows.
The popularity of DeepSeek’s R1 brought out grifters, with many of them launching scam tokens claiming to be associated with DeepSeek. These tokens were seen on Ethereum, Solana, and other layer-1 chains. A Solana-based DeepSeek fake token reached a market cap of $48 million before cooling off while the other peaked at $13 million. There are even many more.
In these instances, traders should check for official announcements from DeepSeek to avoid falling victim to scam pump-and-dump schemes.
Are We Entering the Golden Age of Crypto AI?
The launch of DeepSeek’s R1 model could represent a new chapter in AI development. Although SemiAnalysis argues that DeepSeek spent as much as over $500 million to train its model instead of the reported $6 million, its emergence points to a future that favors cheaper, scalable AI models. In true crypto fashion, this should lead to volatility and tons of scam projects.
However, a new future is being built, with many new crypto startups potentially using DeepSeek’s blueprint to launch blockchain-specific AI models and AI agents.
We are not yet in the golden age of AI, but these are crucial steps toward it.
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.

.png)

.png)


.png)