



A new mind virus is propagating through Silicon Valley called Effective Accelerationism, or e/acc for short. People like Marc Andersson, Garry Tan and Martin Shkreli have used their Twitter bios to mark their support for the movement. The founder himself describes it as a memetic virus.
Adherents state that e/acc is an absolute moral imperative that we as a society could and should adopt and, in doing so, save us from untimely oblivion. They argue that the guardrails around technological development are slowing us down just when we, the human race, desperately need to speed up.
e/acc as a movement has received backlash. It comes from wealthy Americans, and it’s easy to suspect that this philosophy is just more mental gymnastics to soothe their conscience as they hoard wealth.
Yet what exactly is e/acc? Why do people love it? Why do people hate it? Is it just self-soothing nonsense? Or can proper implementation of its thesis spread the “light of consciousness” around the galaxy? Let’s go through it.
So what is e/acc?
Effective Accelerationism is an evolution of the accelerationist philosophies of British lecturer Nick Land, who believed in eschewing the standard structures of society – nationalism, socialism, environmentalism, conservatism – and placing all faith in the power of capitalist enterprise and the technological revolutions it created to steer the course of society.
Effective Accelerationism that takes that accelerant philosophy which initially should be guided towards Artificial Intelligence to usher in the Singularity and bring life to the next level of evolution. Anti-entropic life is a light in the dark chaos of the indifferent universe, but that’s not limited to homo sapiens as we’ve known them for the past 200,000 years – it includes all consciousness. By building AGI and synthetic life, we are on a moral crusade (the theory goes) against the infinite darkness and nothingness that is our cold dark universe. So far, so reasonable – if a bit righteous.
Techno-Capital-Memetic Monsters
e/acc – and this is where the problems creep in for many – believes in the techno-capital machine. It believes entirely that market forces should rule us. It is a philosophy that has glutted on capitalist thought for hundreds of years to arrive at the ultimate conclusion that human society is just grist for the mill of advancement.
It also believes that capitalist leaders are best placed and most knowledgeable to advance this society; small wonder why various tech leaders and VC firms are so enthusiastic about it. It believes that they should mandate the ‘effective’ accelerationism towards AI. It is 100% anti-regulation. Indeed, it is against anything that slows down the techno-capital-memetic behemoth – summated in the form of AI – that guides us to the promised land.
This market-absolutist’s vision of mankind’s evolution is foreboding. We give all the power to the billionaire class, in the hope they’ll give back at some unspecified time in the future. The idea that an AI singularity is our only way out of the problems we have made for ourselves is an alluring one – people find it hard to see any other optimistic path out of pollution, war, and death. Andersson’s techno-optimist manifesto makes it clear that the goal is abundance for all, energy forever, and an ever-increasing intelligence curve amongst society that generates benefit as a result.

Put Your Faith in the Light
This manifesto, and other e/acc materials, point to statistics that living standards, material prosperity and global security are at all-time highs, and it is technology that has brought us to this point. Yes it has created imbalance, but if we just keep going, we can eventually escape the gravity-well that keeps us stuck as limited humans and turn us all into technological supermen. All innovation and consciousness condensed into a techno-capital lifeform that spreads across the galaxy. A final culmination of the 2nd Law of Thermodynamics where free energy is captured into intellectual progress through the meta-systems we as a society create. Moral light in the endless black.
It’s easy to see how these fantastical visions have become something of a religious cult within Silicon Valley circles. These self-exculpating visions of hyper-utopian futures seem to serve merely as a moral ballast to the rapacious use of energy and capital aggregation by the largest companies to advanced AI agents for their own profit. It’s very easy to see this as mere evangelising in a bid to tear down AI regulations and oversight and succumb to the machine. They welcome our new AI overlords – and their mission is to convince you that you should too.
Hey Man, Slow Down
Accelerationism, ‘effective’ or otherwise, has always had a problem with the human cost. It erodes the human subject in the face of the increasingly complex systems that bind us. It seems strange that a philosophy so obsessed with human intelligence is so convinced of its ultimate redundancy. It views human consciousness as the jewel of creation, but ignores the suffering of just about everyone, all those except the top 0.01% who, by dint of inherited wealth or stock market luck, are appointed to effectively accelerate the rest of us. The fatalistic vision that humanity can’t, in effect, look after itself, seems to be a failure in understanding how we got this far in the first place.
There’s a reason you don’t drive 200mph on the freeway, even if your supercar can, because one small mistake and you and everyone else in the car is dead, and faster than the time it takes for the scream to leave your body. Let’s limit acceleration in AI for the same reason.
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.

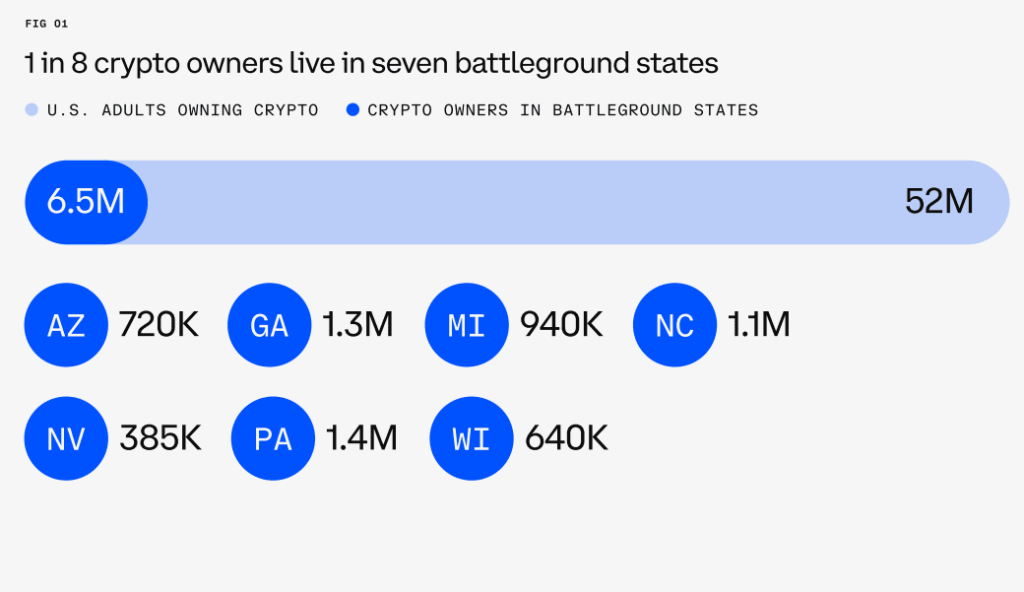
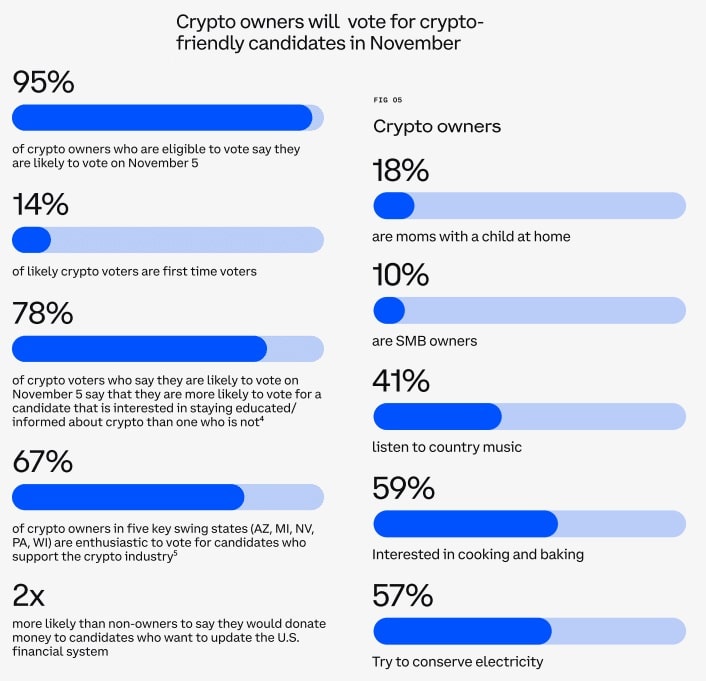
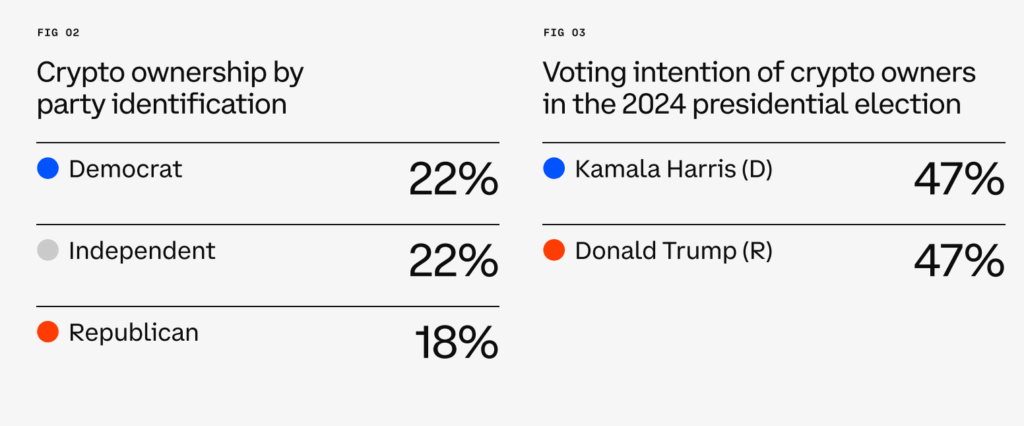
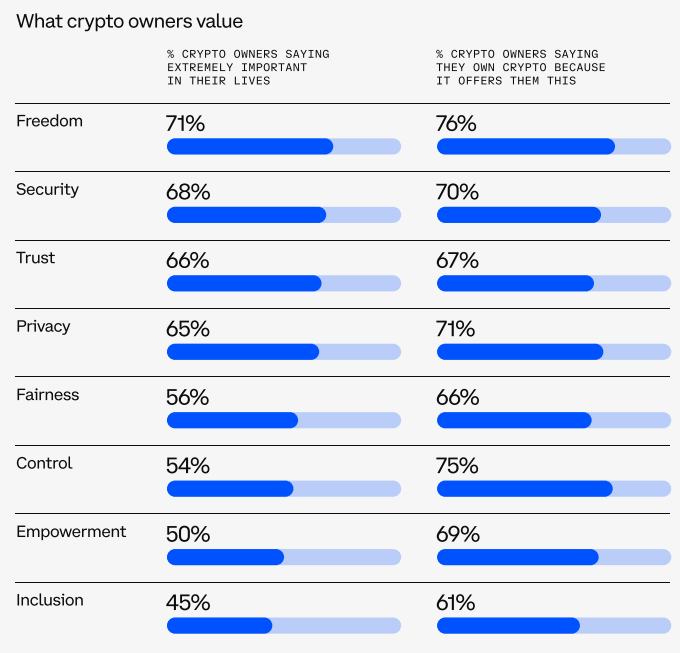



















.png)

.png)


.png)