Tether Hits $13 Billion Profits for 2024 And All-Time Highs in U.S. Treasury Holdings, USD₮ Circulation, and Reserve Buffer in Q4 2024 Attestation Read more: https://t.co/1CRfIK5XR0
It also gets more interesting. With a lean team of just over 100 employees, Tether’s profits trump those of major Wall Street giants that have thousands of staff. And Wall Street is noticing.
Tether generates tangible revenue from its real-world impact, setting it apart from crypto projects which rely on speculation, hype, and memes. As a result, we’ve seen more and more new entrants to the stablecoin market, such as PayPal (PYUSD), Ripple USD (RLUSD) and the controversial Ethena USD (USDe), an algorithmic stablecoin. What does this mean for the future of stablecoins and crypto?
These numbers on Tether’s 2024 profits come from a fourth-quarter and year-end attestation reviewed by the independent accounting firm BDO. Tether doesn’t publicize its financial documents – and this has been a source of controversy for years, with people questioning the existence of reserve funds.
The BDO report claimed the company’s net profit exceeded $13 billion: an all-time high. This puts Tether among the most profitable financial entities in the world. To compare, TradFi giant Goldman Sachs reported $14.3 billion in net income for the same period.
Tether casually makin' 13 billion in profit last year. They have 100 employees…😳
The profit was driven by several key factors, including significant returns from U.S. Treasury holdings and repurchase agreements. Unrealized gains from its gold and Bitcoin investments are also included.
Tether’s equity rose to over $20 billion, reflecting its financial health and strategic investments in various sectors such as renewable energy, Bitcoin mining, AI, telecom, and education.
Tether’s exposure to U.S. Treasuries reached a record high of $113 billion, making it one of the largest holders of U.S. government securities globally – ironic when you view US regulators’ largely anti-Tether stance in favor of its nearest competitor and homegrown stablecoin Circle (USDC).
Growing Reserve Buffer
Tether’s excess reserve buffer surpassed $7 billion for the first time, the report claims. This marks a 36% increase over the past year.
Fears that Tether carries systemic risk that could bring down the whole cryptocurrency industry have been around since its earliest days, especially after it was accused of creating fake volume during the 2017 bull run and its devastating hack in 2018.
Increased USDT Circulation
Tether’s market cap has grown to $142 billion (28 February 2025), up from less than $100 billion a year earlier. It is the most widely used stablecoin, although a separate report claims that less than 10% of stablecoin transactions involve real users.
Tether’s impressive financial performance will not go unnoticed in the financial world. It will have effects on the stablecoin market and the broader crypto landscape.
Stablecoin Dominance
Tether’s latest financial report reäffirms its position as the leading stablecoin issuer. USDT leads the stablecoin pack by a long margin.
In the crypto market, stablecoins are at the center of many DeFi protocols, because they facilitate lending, borrowing, yield farming, and activities like that. Beyond the crypto space, stablecoins offer a cheap and fast form of payment.
The adoption of stablecoins is rising in inflation-hit countries, particularly in Latin America, because they act as a hedge against inflation and currency volatility. The recent Tether report casts the stablecoin in a good light and adds credibility. This could help attract more users and strengthen its position in the stablecoin market.
Regulators Not Impressed
Tether continues to face scrutiny from regulators despite its financial success. Its reliance on quarterly attestations by BDO has drawn criticism from regulators and crypto observers who are calling for full audits in the name of transparency.
Several exchanges such as Kraken are delisting Tether. Some exchanges have been planning to delist it in the EEA (European Economic Area) since the EU’s Markets in Crypto-Assets (MiCA) went live. This regulation states that only licensed operators can issue stablecoins in the EU. National governments are releasing their crypto guidelines, which might also affect Tether’s use.
RLUSD: The Stablecoin Leading the Charge in Europe’s MiCA Era
“The EU's MiCA regulations have come into full effect, leading to the delisting of Tether stablecoins in Europe. This opens up space for a MiCA-compliant stablecoin, such as RLUSD.” – By @JA_Maartun
Tether’s global influence is growing. The company is moving to El Salvador after it received a license there as a digital asset provider. El Salvador legalized Bitcoin as a legal tender (at the top of the 2021 cycle) but had to scale back on its BTC policies to secure loans from the International Monetary Fund (IMF).
Credit: Tesfu Assefa
Wrapping Up
A profit of more than $14 billion with a lean team will get traditional finance firms wishing they could pull off the same. Tether has outclassed many companies by a long stretch. However, questions about its transparency are still on the table, and it will take a lot to soothe regulators. On a positive note, its global influence is growing, and the crypto industry is the big winner if its profitability draws in new competitors with clean track records and good reputations. For investors, using new stablecoins across new ecosystems and chains could help you get substantial interest or help you qualify for airdrops down the line. So while they’re boring by design, stables could be the new crypto cash cow if you use them correctly across the DeFi landscape.
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.
There was a dream that was the internet. A collectivised network architecture sustained by computers around the world hosting content, answering packet requests, and working as a hive to create ubiquitous communications to bind us as a global species.
It worked, kind of. It’s no hyperbole to suggest that the internet may be humanity’s greatest invention to date – or at least its most impactful. Just like the printing press before it, the internet changed the world. The printing press led to the Reformation in Europe. The internet has reformed society as we know it into something new.
There are now two selves, the physical and digital. Two realities, offline and online. There is humanity pre-internet, and post-internet, and they are radically different beasts. In the early days of the internet, innovators waxed lyrical about how this advanced communications tech would change every aspect of society. Sages like Arthur C Clarke predicted utopian futures before the first network even went online. Humanity’s conversation would be unmediated by centralized forces of control that suppress and censor.
Cloud Control
Until it was stolen from us. Until we sacrificed our liberty for efficiency. A Faustian bargain from which the internet has never recovered. A bargain that means the most powerful corporations in the world are all tech companies. Not oil, not weapons, not minerals, but computers. A bargain that has destroyed all sense of privacy and led to the rise of authoritarianism by stealth.
A bargain made with our head in the clouds. Cloud computing, where data, processes, websites, servers, and every packet of online activity is routed through centers controlled by powerful corporations who, offering their services, turned the internet from a prelapsarian Eden of free ownership, software and creativity into a walled garden where every space is rented and every step is tracked.
Our computers, once powerful networked agents in the internet ecosystem, have been reduced to dumb hardware clients, pack mules that are only capable of delivering services whose entire function is dependent on servers in foreign lands. The servers can be censored, restricted, attacked, or otherwise rendered useless by the police and the state. You don’t own anything digital anywhere, not even your work.
This article was drafted in a Google Doc. Once the Panoptic Super AI goes live and begins scanning every word processed through the platform, maybe it decides it doesn’t like this criticism I’m making – and my access to my own creations is restricted, my work deleted, my account banned. As the warring ’20s have so far proved, the impossible can become unstoppable in an instant. The imperative need to secure the freedom of the internet has never been more important.
Local-First Computing – the Antidote to a Poisoned Internet
Enter Local-First computing, a new paradigm for internet architecture that promises to restore privacy, ownership, sovereignty and control to our digital landscapes. Local-first computing wants to give the end-user back authority over their actions in cyberspace, and forge resilient systems that are not at the mercy of a single DDoS attack or plug-pull.
The principle is simple, even if the technology is complex. Turn computers back into data processors, and make all machines contributors once again to the internet that we access. It’s not just about storing data in distributed databases, but making that data processable by the network of local edge devices.
A fleet of industrial devices on the factory floor wouldn’t send their data to distant servers to be processed and resupplied, but simply connect to another and operate on data in real time. Smart cars on the road link to others for local traffic updates and emergency warnings. Satellites in the sky process their data on-device (above the clouds), rather than expensively relaying every data packet to Earth and back. In the era of AI, where control of data is a key battleground, and relentless data-harvesting to improve models is a massive social threat, ownership of our data stops the potential overreach of corporate AIs.
The tech is new, but the possibilities are endless. Removing our reliance on the cloud returns us to the creative commons with true privacy and ownership. It’s what the internet used to be, and it breaks the monopoly that tech infrastructure giants hold over all of us. A new open internet where we can run free, and where your participation isn’t determined by central forces.
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.
Turning real-world assets (RWA) like stocks, bonds, fiat money, debt, and property into tokens on the blockchain marks a significant shift in how traditional assets are managed and traded.
Major players like BlackRock are actively pushing RWA tokenization forward, with estimates suggesting the RWA market could reach $500 billion in 2025, a 13× from its current $38 billion market cap. This growth is driven by increasing institutional adoption and regulatory clarity, particularly following key appointments in U.S. regulatory bodies.
Let’s take a look at some of the brightest projects out there and the utility they bring.
Ethereum: The Foundation Layer
Ethereum remains the dominant force in RWA tokenization, hosting 86% of all tokenized real-world assets. Major institutions consistently choose Ethereum for their RWA launches, trusting its security, established regulatory status (now that it has an approved ETF) and the specialized ERC-3643 token standard designed for easily tokenizing regulated assets.
The upcoming Petra upgrade promises improved scalability for the base layer, while the growing layer-2 ecosystem reduces costs and increases transaction speed, making Ethereum increasingly practical for RWA trading.
Chainlink: The RWA Data Backbone
Chainlink has established itself as RWA infrastructure. Its decentralized oracle network connects smart contracts with real-world data, making it a good fit for asset tokenization.
The platform’s reliability in providing accurate data feeds allow it to verify asset values and automate crucial processes like rental income distribution and property management.
K33 Research recently labeled Chainlink as the safest bet in the RWA narrative, confirming its solid foundation to help build the new ecosystem. The LINK token, used for oracle services and node operator incentives, stands to benefit from increased RWA adoption.
Pros:
Industry standard for RWA data feeds
Strong track record of reliability
Growing institutional adoption
Cons:
Token value tied to network usage
Complex tokenomics
High competition in oracle space
Ondo: The Institutional Bridge
Ondo aims to lead the way in creating tokenized traditional assets. Its transparent operations and regulatory compliance have attracted significant institutional interest. The company’s recent launch of Ondo Global Markets (GM) represents a major step forward in making RWA investing more accessible through tokenized stocks, bonds, and ETFs.
The platform works closely with traditional finance giants, holding approximately 38% of BlackRock’s BUIDL fund. Institutional backing like that, combined with its purpose-built layer-1 blockchain for RWAs, positions Ondo as a promising player in bridging traditional finance and blockchain technology.
Pros:
Strong institutional partnerships
Regulatory compliant framework
Growing asset selection
Cons:
Limited token utility currently
Dependent on regulatory clarity
Regional restrictions
Mantra: The Compliance-First Network
Mantra distinguishes itself through a unique approach to RWA tokenization: it embeds compliance directly into its protocol. It is a Cosmos-based blockchain with built-in KYC/AML (Know Your Customer/Anti-Money Laundering) capabilities and transaction monitoring, making it particularly attractive for institutional users looking for regulatory-compliant solutions.
Recent partnerships, including a significant deal to tokenize over $1 billion in real estate with DEAC, demonstrate growing market confidence. The platform’s focus on Middle Eastern and Asian markets has helped establish strong regional presence.
Pros:
Built-in compliance features
Strong regional partnerships
High performance infrastructure
Cons:
Geographic limitations
Early stage development
Complex regulatory landscape
Plume: The Rising Star
Plume is a modular, secure, and scalable blockchain infrastructure that facilitates tokenizing and managing RWAs optimally. It has quickly captured market attention in the RWAfi space, amassing 18 million addresses and $4 billion in available assets.
Following a successful $20 million funding round, the platform has integrated with major players including Paxos and LayerZero, setting the stage for rapid expansion in 2025.
The platform’s token price has shot up, suggesting strong market confidence in its approach to RWA tokenization. This momentum positions Plume as a potential market leader in the coming year.
Goldfinch: The Global Lender
Goldfinch operates as an Ethereum-based lending platform, currently managing nearly $100 million in active loans to businesses worldwide. Backed by prominent venture firms including Andreessen Horowitz and Coinbase Ventures, the platform bridges the gap between crypto liquidity and real-world lending.
The GFI token, though smaller in market cap than other RWA project tokens, is exhibiting growth potential as the platform expands its lending operations.
Sky (formerly MakerDAO): The RWA Pioneer
Sky’s transformation from MakerDAO represents a strategic shift toward RWA integration. Its rebranded USDS stablecoin uses real-world assets including Treasury bonds and mortgage loans as collateral, generating stable yields and connecting traditional finance with DeFi infrastructure.
The platform’s innovative ‘smart burn’ engine applies deflationary pressure on the SKY token as protocol fees increase, offering a unique value proposition for token holders. This mechanism becomes particularly significant as RWA adoption grows.
Artrade: The Art Market Innovator
Built on Solana‘s high-speed blockchain, Artrade targets the fine art market with its tokenization platform. This focused approach has helped the project carve out a unique position in the RWA space, offering investors exposure to a traditionally exclusive market.
The platform’s recent growth suggests increasing market interest in specialized RWA solutions, particularly in premium asset classes like fine art.
Ethena: Pioneering Synthetic Dollar Stablecoins
Stablecoins represent the earliest form of Real-World Assets in the crypto space, with a market cap reaching $180 billion. Ethena (USDe) introduces an innovative approach as a non-custodial stablecoin backed by ETH and stETH.
Custodial stablecoins like USDC and USDT are backed by government securities, but Ethena instead uses ‘delta hedging’ – a sophisticated trading strategy where the protocol opens equivalent short derivatives positions in ETH for every USDe unit, offsetting potential price volatility.
However, experts have raised concerns about Ethena’s sustainability, particularly regarding its high-yield offerings during bear markets, and the regulatory implications of its complex derivatives operations.
OriginTrail: Providing RWA Data Transparently
OriginTrail tackles the challenges of data transparency and verification through its decentralized knowledge graph (DKG) platform. The system enables the tokenization and traceability of real-world assets, while addressing critical issues like data silos and inefficient information-exchange.
The platform has three key components:
the DKG for secure data connection and verification
a multi-chain blockchain infrastructure for transaction security
the TRAC token for network operations and governance.
This ensures that data remain both accessible and tamper-proof, providing a crucial bridge between traditional asset management and blockchain technology.
Credit: Tesfu Assefa
Final Thoughts
2025 will be the year when the RWA sector matures, and these ten projects should be seen as just some of the early ones in the sector. They represent different approaches to bringing real-world assets on-chain. Success will likely depend on the ability to maintain regulatory compliance while delivering efficient, scalable solutions for asset tokenization.
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.
The best approaches to influencing the influencers, educating the educators, and motivating the motivators
Eureka!
Sometimes we have a breakthrough realization, when thoughts creep up on us and we suddenly see something in a new light. This often happens while we’re away from work settings – we might be cycling, walking in a woodland, or having a shower. For Archimedes, his Eureka moment happened in the bath.
Can society as a whole change its mind, on important matters, in an instant? For example, what caused society to alter their view of slavery, from something unpleasant but tolerable, to something that should be abolished?
What might it take for society to see robust medical control over age-related disease not as an ethically questionable fantasy, but as an achievable humanitarian goal? Let’s consider a change of view that would push society to decide that it is deeply desirable to provide much more funding for experiments on how to reverse biological aging.
These changes in mindset seem unpredictable and mysterious. So mysterious, indeed, that many advocates for ending aging have almost given up hope that their ideas can ever become mainstream. Humans are just too irrational, these dejected advocates conclude.
Let me offer a model as a basis for greater optimism.
In this model, four main factors can influence people to change their minds:
Surprising new facts – such as showing that mice were treated with anti-aging interventions and then lived much longer, and more healthily, than normal mice
Credible theories – which make sense of these new facts, showing how they fit into a broader pattern, and light the way to even greater results
Internal compatibility – whether these theories challenge, or seem consistent with, your deeper beliefs and desires
External reference – whether these theories seem to have the support of other people you respect such as community leaders or social influencers.
If factors 3 and 4 oppose a new theory, that theory will have a hard time! For example, many people seem to be deeply committed to beliefs such as the following:
“Good people don’t try to take more than their fair share of lifespan”
“The only people who desire significantly longer lifespans are naïve, immature, or egocentric”
“It’s pointless to raise hopes about ending aging – such hopes will only lead to disappointment”
“The natural state of human existence is cyclical: a rise and fall in health, and a passing of the torch to new generations”.
Find someone with these beliefs and try to talk to them about new experimental results that seem to delay the onset of aging: you’ll find they avert their attention or find some excuse to denigrate the experiment.
To overcome this internal resistance, we can list four approaches – which build on the four-factor model given above:
Uncover and highlight facts that are even more surprising and incontrovertible – “look, here’s another example from nature in which there’s no biological aging”
Talk about theories which are more engaging and more compelling – “there’s nothing mysterious about this, it follows from some very basic principles”
Take time to build bridges with the system of values that the person cherishes – health, community, liberty, courage, service to others, and so on – and show how the new theory supports these values after all
Find influencers (broadly defined) who are willing to understand the theory and then become its champions.
All four of these approaches are important, but it’s the fourth that potentially has the most leverage.
That’s the simple version of the model of change. Now let’s take a deeper look.
Credit: David Wood, aided by Midjourney AI
A pessimistic model of societal influence
We’re all impacted, to greater or lesser extents in different contexts, by the views expressed by people we can call ‘influencers’ or ‘thought leaders’. These may include the most popular children at school, respected aunts and uncles, community leaders who have an aura of wisdom, writers who strike us as being particularly smart and knowledgeable, performers who reach us emotionally as well as rationally, podcast hosts who seem to be on top of changing currents, the stars of cinema, music, or sport whose accomplishments we admire, and so on.
Hence the general advice for any would-be social movement: “influence the influencers”. This is often coupled with two similar pieces of advice: “educate the educators” and “motivate the motivators”.
This pushes the basic problem back one stage. Rather than figuring out how to cause a member of the general public to change their mind, we now have to figure out how to cause various social influencers to change their minds.
In some cases, influencers respond to the views of domain experts. The reputations of the influencers depend, in part, on saying things that relevant domain experts consider credible.
Before an influencer decides to become an advocate for a disruptive view – such as “the end of aging is nigh” – they are to consult the views of the most renowned scientific researchers in the field of longevity.
Here another major problem arises. The community of longevity researchers by no means speaks with a single voice. Instead, it contains plenty of scepticism. Apparently well-credentialed researchers in longevity science express opinions like “it may take 100 years to learn how to comprehensively solve aging”. Others say things like “we still don’t know what causes aging”.
It’s no surprise, therefore, that many would-be social influencers shy away from bold statements about the possibility of ending aging quickly.
The conclusion of this line of analysis: changing opinions within the community of longevity research scientists would be the most valuable move. Imagine if this community transforms from its present cautious pessimism into more full-throated excitement!
What could cause that transformation? What could influence the influencers of the influencers?
Well, since these ‘influencers of influencers’ are scientists, the answer should be clear. What should change their minds, other things being equal, is a combination of the first two points listed above, namely –
Surprising new facts – such as showing mice being treated with anti-aging interventions and then living much longer, and more healthily, than was previously expected
Credible theories – which make sense of these new facts, showing how they fit into a broader pattern, and light the path to even greater results
There’s a catch: every experiment that might lead to “surprising new facts” requires funding, and there’s a limited amount of that going around.
Worse, many of the most promising longevity experiments have little prospect for immediate commercial payback to investors. They are experiments whose results are public goods, without any lock-up of IP (intellectual property).
Accordingly, while some important anti-aging experiments can be funded by venture capitalists or other financial investors anticipating a commercial return (through sales of medical treatments), many others require funding from philanthropic or public sources such as government agencies.
This pushes the problem back one more time. Now the question is: how to influence the decision-makers who control those sources of funds (whether philanthropic or public)?
So long as members of the general public express apathy, or even hostility, toward experiments that might reverse aging, decision-makers who control funding will be reluctant to challenge that stance.
It may seem that we have reached a vicious cycle:
Members of the general public won’t change their minds until social influencers change their minds
Social influencers won’t change their minds until the community of longevity scientists change their minds
The community of longevity scientists won’t change their minds until scientific experiments challenge their current scepticism
These scientific experiments won’t take place until more funding is made available for them
People who control large public funds won’t approve spending on anti-aging research until the public changes their minds.
Credit: David Wood
It’s as I said earlier: it’s no surprise that many advocates for ending aging have almost given up hope that their ideas can ever become mainstream.
An optimistic model of societal influence
But wait. We shouldn’t think just in binary terms. It’s not a matter of complete failure versus complete success. It’s a matter of gradually changing minds – in the wake of increasingly significant experimental results.
The simple description of this new model is: “Good experimental results generate social excitement, leading to more funding, and to even better results.”
An even simpler description is: “Positive feedback loops generate exponential acceleration”. That is, the first few loops may generate only slow, incremental improvements, but subsequent loops can generate much larger changes.
The model can be expanded into a diagram with (count them!) 25 steps:
Credit: David Wood
The model is shown as having three loops, but that’s an arbitrary number. I’ve chosen three for simplicity.
Let’s walk through the 25 steps:
The model starts (step 1) with an assumption that at least some researchers want to find ways to end aging, and that some funding has been promised to them. These researchers design an initial experiment (step 2) and utilise some available funds to carry out the experiment (step 3).
At this point, the following sequence may happen – perhaps several times over:
The experiment fails to live up to expectations (step 4)
The researchers rethink their theories (step 5)
They update the design of their experiment (step 6)
They apply some more funds to carry out the updated experiment (step 7).
Eventually – and in the next section I’ll explore the plausibility of this step – the experiment produces results that can be described as ‘promising’ (step 8) rather than ‘weak’ (step 4). In turn, this leads to the following cascade:
At least some members of the broader longevity research community become more enthusiastic about the possibility of ending aging in the relatively near future (step 9)
At least some of society’s influencers (television personalities, podcast hosts, etc.) speak more warmly than before about the case for ending aging (step 10)
Influenced by the influencers, a greater proportion of the general public allow themselves to express hopes, desires, and demands for society to rally behind the project of ending aging sooner rather than later (step 11)
Influenced by the general public, some political leaders, along with other decision-makers who control significant sources of funding, switch their outlook from apathy or hostility regarding ending aging to at least some cautious optimism (step 12)
These decision-makers approve funding researchers who have promising ideas for anti-aging interventions (step 13)
With these additional funds, the researchers design bolder experiments, with more comprehensive anti-aging interventions (step 14), and carry out these experiments (step 15).
This might be followed by one or more loops of increasingly promising results, or one or more loops of comparative failure.
Eventually, the outcome of an experiment goes beyond what could be called ‘promising’ (step 8) to ‘breakthrough’ (step 16). This breakthrough result unleashes a more powerful cascade of reactions:
The community of longevity researchers moves from merely enthusiastic to solidly convinced; indeed, some scientists who previously kept quiet about their actual views, for fear of being labelled ‘cranks’, no longer self-censor, and now speak out strongly in favour of shorter timescales (step 17)
The community of social influencers moves from excitement to exuberance (step 18)
The general public moves from mere excitement to activism and mobilization (step 19)
Politicians now find themselves free to express their own (perhaps long-suppressed) views that, actually, ending aging would be a profound social good (step 20), and therefore deserves huge amounts of funding (step 21)
With ample funding available at last, longevity researchers can design (step 22) and carry out even bolder research (step 23).
Perhaps after one or more additional turns of this loop, the results will be so conclusive (step 24) that the vast majority of society unites behind the cause of ending aging, and adopts in effect a wartime mentality of ‘whatever it takes’ to reach that goal without any further delay (step 25).
Double-checking plausibility
Where might the above model of change encounter its most serious blockages?
The biggest leaps of faith involve believing that experiments on rejuvenation treatments will indeed produce results that can be described as ‘promising’ (step 8), ‘breakthrough’ (step 16), and ‘conclusive’ (step 24).
Reasons for thinking that experiments will in due course have such outcomes include:
A simple extrapolation of previous experiments, which have had their share of promising outcomes
The strengths of various theories of aging, not least the theory which I personally judge to be the most compelling, namely the damage-accumulation theory of aging.
Some readers may prefer a different theory of aging, with central roles given to (for example) hormones, bioelectricity, the immune system, or genetically programmed decline. If you have a favourite theory of aging and believe it to be credible, you will share my assessment that good outcomes will eventually result from anti-aging experiments. These readers will regard it especially important to change/update theories (step 6). (For these readers, the ‘update’ will require more than a change of parameters; it will be a total change of paradigm.)
Reasons for thinking that anti-aging experiments will not in due course have promising outcomes include:
A pessimistic assessment of the rate of progress in recent years
Criticisms of theories of aging.
I’m not impressed by any general extrapolation from “slow progress in the recent past” to “slow progress in the indefinite future too”. That extrapolation entirely fails to appreciate the exponential-acceleration model I’ve described above. Indeed, there have been plenty of other fields (such as artificial intelligence) where a long period of slow progress transitioned into a period of more rapid progress. Factors causing such a transformation included:
The availability of re-usable tools (such as improved microscopes, molecular assembly techniques, diagnostic tests, or reliable biomarkers of aging)
The availability of important new sets of data (such as population-scale genomic analyses)
The maturity of complementary technologies (like how a network of electrical recharging stations allows the wide adoption of electric vehicles; or a network of wireless towers allowed the wide adoption of wireless phones)
Vindication of particular theoretical ideas (like how understanding the importance of mechanisms of balance allowed the earliest powered airplanes to take flight; or the germ theory for infectious diseases)
Results that demonstrate possibilities which previously seemed beyond feasibility (such as the first time someone ran a mile in under four minutes)
Fear regarding a new competitive threat (such as the USSR launching Sputnik, which led to wide changes in the application of public funding in the USA)
Fear regarding an impending disaster (such as the spread of Covid-19, which accelerated development of vaccines for coronaviruses)
The availability of significant financial prizes (such as those provided by the XPrize Foundation)
The different groups of longevity researchers committing to a productive new method of collaboration on issues that turn out to bear fruit.
That leaves questions over how to assess which theories of aging are credible. To be clear, it’s in the nature of scientific research that the validity of theories cannot be known in advance of critical experiments. That’s why research is needed.
I accept that it’s possible that the biological aging of humans will turn out to be comprehensively more complex than I currently conceive. It’s also possible that alternative theories for how aging can be ended will fail too. But these are only possibilities, not what I would expect.
I doubt there’s any meaningful way to measure the probability of such a failure. However, until someone produces a good counterargument, I will continue to maintain there’s at least a 50% chance that aging can indeed be defeated, sooner or later, by a programme of rejuvenation interventions.
Even if that probability were considerably lower – just 5%, say – that would still be a reason for society to invest more of its discretionary financial resources to fund a number of the anti-aging experiments that, on paper at least, appear promising.
These experiments will provide important data to help answer the questions:
Do our theories of aging appear to be on the right track?
If these theories are on the right track, is it sooner, or instead later, that we are likely to obtain conclusive results from anti-aging experiments?
Short-cuts and warnings
In a moment, I’m going to switch from the theoretical to the practical. That is, I’m going to suggest ten ways that each of us might be able to help accelerate the end of aging. I’ll do so by referencing the above model.
But first, it’s time to admit that, of course, there are many pathways of influence, education, and motivation beyond the ones represented by the arrows in the above diagram.
For example:
Some members of the general public may change their minds, not because they are inspired by a social influencer, but because they consult science publications directly
Some important experiments can proceed, not because they receive funding from public institutions, but because a group of volunteer citizen scientists provide their services free of charge
Sometimes individual politicians can prove themselves to be visionaries, championing a cause ahead of majority public opinion
There are special kinds of influencers, such as patient advocates, who can play their own unique roles in magnifying flows of new understanding throughout society.
In other words, the arrows in the above diagram show only the mainstream flows of influence, and omit many important secondary influences.
With that in mind, let me now offer some answers to the question that I often hear when I speak about the possibility of defeating aging. How can people help to bring about this possibility more quickly?
In all, I’ll offer ten suggestions. But watch out: in each case, there’s a risk of taking the suggestion too far.
Credit: David Wood
1. Learn the science
As stated earlier, two of the most powerful tools to change minds are to share new information and to share new ideas. That is, to draw people’s attention to surprising facts discovered by scientific investigation, and to credible theories, which make sense of these surprising facts.
Before we can share such information and ideas with others, we need to understand them ourselves. That’s why one of the key ways to help accelerate the defeat of aging is to keep learning more about the facts and theories of aging – as well as the facts and theories of how aging can best be reversed.
What’s more, the better our collective scientific understanding of the aging process, the more likely it will be that an appropriate set of anti-aging experiments will be prioritized – rather than those who are championed by people with loud voices, large wallets, or unfounded scientific prejudices.
I acknowledge that subjects such as biochemistry, immunology, nutrition, pharmacology, comparative evolution, genetics, and epigenetics can be daunting. So, take things step by step.
Two foundational books on this overall set of topics are Ending Aging: The Rejuvenation Breakthroughs That Could Reverse Human Aging in Our Lifetime, by Aubrey de Grey and Michael Rae, and Ageless: The New Science of Getting Older Without Getting Old, by Andrew Steele. In the last 12 months, I’ve also benefited from reading and thinking about (among others)
The Genetic Book of the Dead: A Darwinian Reverie, by Richard Dawkins
Two books by Nick Lane: Transformer: The Deep Chemistry of Life and Death, and Power, Sex, Suicide: Mitochondria and the Meaning of Life
Eve: How the Female Body Drove 200 Million Years of Human Evolution, by Cat Bohannon
Why We Die: The New Science of Aging and the Quest for Immortality, by Venki Ramakrishnan.
There’s a lot more that can be learned from Youtube channels, podcasts, and real-world presentations and gatherings.
But beware: Don’t fall into the trap of thinking you should take no action whilst there are still gaps in your understanding of the science. The solution of aging involves engineering as well as science. Engineering involves finding out what works in practice, even though there may be gaps in scientific explanations.
Indeed, it may well be possible to remove or repair the damage which constitutes biological aging without knowing the exact metabolic sequence that gave rise to each piece of damage.
In other words, don’t let imperfect knowledge be a cause of inaction.
2. Become a citizen scientist
Even if your knowledge of science is far from comprehensive, you may still be able to assist important anti-aging projects by methods such as:
Literature searches, looking for articles relevant to the design or progress of an experiment
Data analysis and review
Self-experimentation: becoming a participant in studies on fasting, supplements, or biohacking
Organizing small-scale experiments using low-cost lab facilities.
Even small contributions can make a big difference over time.
A citizen scientist often devotes only a portion of their spare time to such projects. After retiring from their main job, some even become full-time citizen scientist researchers.
But beware: Each project tends to build its own momentum, and the motivation of participants can change from “I’m doing this to help reverse aging” to “I’m doing this because I want to finish the project and be able to list it on my CV” or even “I’m pivoting this project away from focusing on aging to focusing on something more commercially rewarding”.
In other words, be sure to keep the goal foremost in your mind.
3. Learn the broader arguments
As covered earlier, there’s a lot more to changing people’s minds than merely quoting scientific facts and scientific theories. In practice, people’s minds are heavily influenced (consciously or unconsciously) by their views on religion, philosophy, economics, and politics. To help change people’s thinking on the desirability of ending aging, we need to become familiar with the counterarguments from these fields – and we need to become adept at responding to these counterarguments in ways that are respectful but also persuasive.
Again (as with science) we don’t need to learn about these non-scientific topics just to influence others, but also so that we can free our own choices and actions from biases and prejudices that we previously didn’t recognise.
In the last 12 months, I’ve personally benefited from reading and thinking about the following books (among others) which addressed those subjects:
The Longevity Imperative: How to Build a Healthier and More Productive Society to Support Our Longer Lives, by Andrew Scott
Pathogenesis: How Germs Made History by Jonathan Kennedy
The Price We Pay: What Broke American Health Care—and How to Fix It, by Marty Makary
The Future Loves You: How and Why We Should Abolish Death, by Ariel Zeleznikow-Johnston.
But beware: There’s little point in pursuing precise calculations of the economic benefit of rejuvenation therapies. Whether an anti-aging healthcare intervention, applied across an entire society, would be worth $3 trillion in healthy life-years gained, as opposed to just $1 trillion, won’t change the minds of many more people. Instead, the primary reason people resist calculations of vast economic benefit is because they don’t believe in the scientific arguments about the interventions. They don’t believe the interventions will work. Accordingly, it’s the science that they need to come to trust, rather than going more deeply into economics.
The primary reason they fail to accept the scientific arguments is often that they experience a painful cognitive dissonance with the picture they like to hold of themselves as being (for example) hard-hearted, or self-sacrificing, or undemanding, or religiously pure, etc. Accordingly, the conversation that is needed in this case is about values, or identity, or other philosophical foundations. Or perhaps it’s not even a conversation that’s needed, but rather that the person needs to feel comfortable with whoever is expressing these new ideas.
As is often said, when it comes to controversial topics, few people will care about how much you know, until they know how much you care.
In other words, what matters isn’t just the message, but also the messenger. (Which is another reason why well-admired social influencers can have a disproportionate impact upon public opinions.)
4. Steer conversations
Once you’ve learned at least some of the scientific theories about aging, and at least some of the broader philosophical arguments, then you’ll in principle be able to help steer both private and public conversations toward the conclusion that ending aging in the not-so-distant future is both scientifically credible and morally desirable.
That is, you’ll be ready to become an influencer too – albeit one who is less influential than media stars or broadcast personalities. You’ll be able to correct various misconceptions and distortions about aging – and how it might be cured.
To do this well, you’ll need to develop communication skills, which may include one or more of the following:
Good writing
Good listening
Good questioning
Good speaking
Good humour
Good graphics
Good narrative construction
Good music composition
Good video composition
But beware: Not every argument is worth winning. Not every conversation needs to be pursued to an agreement. Sometimes it’s prudent to step back from an interaction, especially if it’s with people who delight in trolling, or who are unprepared to change their minds.
Also note that how you conduct an argument is often as important as what you say in that argument. If we are perceived as being obnoxious, or arrogant, or dismissive, etc, we can do more harm than good.
In other words, pick your battles carefully – and remember that your behaviour can have a bigger impact than your message.
Credit: Tesfu Assefa
5. Anticipate larger narratives
As people think more seriously about the possibility of biological rejuvenation, they’ll frequently start to wonder about some larger questions:
If rejuvenation therapies can undo damage in our bodies and brains, might similar therapies enable us to live ‘better than well’ – with significantly better fitness, vitality, strength, and so on, than even the healthiest people of previous eras?
Indeed, why stop at physical rejuvenation? What about using technologies to rejuvenate our minds, our emotions, our relationships, and our spirituality?
If we can eliminate the pain of aging in humans, why not also the aging experienced by our pets, and by other animals with whom we share the planet?
Alongside rejuvenation of vitality, what about rejuvenation of fertility? Might someone choose to keep on having babies into their nineties and beyond?
Is ‘til death do us part’ still the best principle to guide marriage, if lives and good health extend far beyond the biblical figure of threescore years and ten?
Would ending aging worsen inequalities? Or result in irreparable damage to the environment?
If generations no longer retreat from the workforce due to declining vitality, making way for younger employees to be promoted, how will workforce dynamism be preserved? And won’t there be a cultural stagnation in fields such as the arts and politics? Indeed, what about immortal dictators?
There are three general types of reactions to these questions:
These possibilities are awful, which is a reason to oppose the ending of aging
Lives will for the most part remain the same as before, except that they will become much longer
Human experience is likely to be transformed in many other ways, beyond simply living longer; our lives will be expanded rather than just extended.
In case you’re unsure, the third reaction is generally the correct one.
Accordingly, advocates for ending aging need to decide whether to remain silent on the above sorts of questions – switching the conversation back to more comfortable topics – or instead to have thoughtful answers ready.
The good news is that communities such as transhumanists, vitalists, cosmists, singularitarians, and other radical futurists, have already explored these questions at some length. The bad news is that the writings of these groups are sometimes bewildering, contradictory, or disturbing.
That’s a reason for longevity advocates to start to become familiar with the twists and turns of this philosophical landscape. If you have nothing to say when a conversation turns in these directions, someone may conclude that you haven’t thought through the consequences of your beliefs, and that, accordingly, you aren’t to be trusted.
But beware: Although it’s good to be prepared for conversations turning to subjects such as transhumanism, cryopreservation (also known as biostasis), human-machine cyborgs, replacement bodies, and longtermism, it’s probably best in most cases not to start a conversation on these topics.
If people perceive you as being more interested in these topics than, say, extended healthspans for all, they may decide that you are too weird, and break off their conversation with you.
In other words, be ready for conversations to turn radical, but avoid premature radicalisation.
6. Beware snake oil
I’ve already mentioned how well-intentioned advocacy for ending aging sometimes does more harm than good. Examples include:
Speaking rationally but without empathy or sensitivity
Disregarding value-systems which are held dear by people listening
Introducing topics that frighten listeners, and which switch listeners from open-minded to closed-minded
There’s one other way in which ill-judged advocacy can rebound to make the anti-aging field weaker rather than stronger. Namely, if anti-aging enthusiasts champion treatments, therapies, potions, pills, processes, lifestyle habits, or whatever, that have limited scientific credentials, or, worse, have evidence that they cause harm.
Some of this over-selling arises from naïveté: the enthusiast has put too much trust in a friend, colleague, or social influencer, and hasn’t done good research into the ‘solution’ being advanced.
On other occasions, the over-selling can be deliberate. Think of Elizabeth Holmes of Theranos, Adam Neumann of WeWork, Trevor Milton of Nikola, or Sergei Mavrodi of MMM Healthcare.
On yet other occasions, the perpetrator of the fraud has no expectation that the “solution” will ever become viable. They are simply in the business of finding a gullible audience, telling the audience what they want to hear (for example, “this remarkable treatment is scientifically proven to add years to your healthspan”), taking as much money as possible, and then disappearing from sight. (“So long, sucker!”)
In all three cases, a number of harms can result:
People can have their health ruined by the so-called solution – perhaps even dying as a result of a misdiagnosis
If their biological health remains OK, they may nevertheless suffer a big hit to their financial health
Financial resources that should have been applied to treatments with a stronger scientific basis have been wasted on bogus ones
People viewing from outside may deduce that the entire anti-aging field is full of cranks, cheats, and charlatans; accordingly, they may close their minds to the entire subject.
To avoid these harms, all of us need to keep firmly in mind the principles of scientific investigation. These include:
Checking statistical results, rather than isolated cherry-picked examples
Looking not just for confirming evidence, but also for dis-confirming evidence
Being alert for ‘motivated reasoning’
Ensuring that trials can be replicated
Considering alternative hypotheses
Requiring independent investigation by researchers with no direct ties to the solution
Resisting appeals to apparent authority
Requiring clear explanations, rather than a flood of pseudoscientific mumbo-jumbo.
But beware: Attention to the risks of solutions possibly being flawed should not result in analysis paralysis. Absence of complete evidence should not cause all investigations to stop. It is still possible to recommend various treatments even in the absence of full medical trials, so long as recipients are made aware of the risks involved.
In other words, caution should be our companion, but not our master.
7. Join a business
In recent decades, most of the technological transformations of the human condition have involved businesses that converted research ideas into products for which customers would willingly pay. Consider motor vehicles, airplanes, musical instruments, washing machines, dishwashers, computers, phones, contraceptives, heart pacemakers, hip replacements, and stem cell therapies. A competitive marketplace spurred innovation, quality improvement, price reduction, and greater consumer choice. It will surely be the same with many of the interventions that will help to reverse aging.
By using a combination of the skills already mentioned, you can join a company that is already working on solutions related to the anti-aging cause. Options include:
Joining an established company, or a startup
Joining a company that is already committed to anti-aging, or one that has products that could be repurposed or re-oriented for anti-aging purposes
Joining a company in a role similar to one you’ve had earlier in your career (e.g. HR, marketing, finance, legal, I.T., consulting, validation, or R&D), or instead taking more of a risk and starting a new career trajectory, probably at a lower rung in the ladder.
As always, when deciding to join a company, you’ll need to weigh up a variety of considerations:
Corporate culture
Leadership acumen
Product suitability
Product roadmap
Balance of risk and reward
The calibre of your potential new colleagues
Working conditions
Salary and other compensation
Before you can obtain a job that attracts you, you may need to undergo further training or take an interim role in a position which could become a stepping-stone to your intended destination.
In this way, you could make a significant contribution to bringing important new anti-aging products to the market.
But beware: Businesses can take on a life of their own. Meeting business deadlines can, stage-by-stage, cause you to deviate from what you previously considered to be your true purpose. Instead of supporting R&D into new anti-aging products, your efforts may be diverted into personality conflicts, corporate politics, products that have little to do with anti-aging, or pursuing profits instead of solving aging.
Accordingly, anyone working in a business ought to organise a ‘time-out’ for themselves every few months, in order to reflect on whether their current business role is still the best use of their energy, skills, and resources.
In other words, businesses should be our allies, but not our overlords.
Credit: Tesfu Assefa
8. Make financial contributions
Rather than applying our time into many of the above activities, we can apply our money.
This could be a one-off contribution, or a recurring donation.
It could be an investment made with some expectation of a financial return in the future. Or it could be a philanthropic gift, made just with the thought that millions (indeed, billions) of people could benefit in due course from the anti-aging products and solutions whose development your gift supports.
Of course, deciding which financial contributions to make is as complicated as deciding which job offer to pursue. The range of potential recipients can be overwhelming.
To help you decide, here are some factors to consider:
The potential of your gift to trigger a cascade of further investment by other people, via the kind of feedback cycles in the model described earlier in this article
Whether you prefer to make a relatively safe investment to support some incremental research into an application of some technology that is already reasonably well understood, or instead an investment to help understand core platform mechanisms with potentially many implications
The track-record of the people who will receive your donation
Potential tax-efficiency in the methods by which you make your donation.
But beware: An organisation that you judge to be the best recipient of a donation at one time may no longer be the best such recipient at a later time:
Personnel may change at the organisation
The organisation may change its strategy
New research findings may provide better options elsewhere.
Accordingly, the task of giving money away can be just as challenging as the task of earning it in the first place. To get the best results, we need to remain informed and attentive.
In other words, don’t allow momentum to get the better of your better judgement.
9. Build bridges
This brings us to perhaps the most significant way that many of us can accelerate the defeat of aging. Rather than just relying on our own energy, skills, and resources, we find ways to unleash the energy, skills, and resources, of whole communities of people.
For example, even if you have only limited finances at your own disposal, you presumably know some people who are wealthier than you. Even if you personally lack deep knowledge of science, you presumably know some people with better training in researching the scientific literature. Even if you are personally unable to create engaging videos, you presumably know some friends or colleagues who could take on that task.
This idea lies at the heart of the multiplicative effects of the model of societal change featured in this article. It involves us sharing, with any groups of people who may be ready to respond, news of scientific breakthroughs, updates in scientific theories, and the humanitarian philosophical ideas that validate the radical extension of healthspan.
This bridge-building activity is in some cases fairly straightforward, when we reach out to people who have similarities with ourselves. The kinds of ideas that changed our own minds may well change their minds too. But not always, since the ideas at the backs of people’s minds often differ in unexpected ways.
Accordingly, an important skill in bridge-building is to be perceptive – to listen carefully to any feedback, and to notice whether ideas seem to be received well or badly. It is sometimes wiser to wait for a better opportunity, when your conversation partner may be more receptive.
The most impactful bridge-building can take place when you establish links with a community where, at first sight, you have little connection. However, with creative insight, you can find the right leverage point.
Examples include connecting with:
Patient-support groups, where members are already attuned to the benefits of life-extending treatments, and who may be ready to consider radical alternatives
People with a different political persuasion to you, but who may nevertheless share your conviction that defeating aging should be a clear priority
People from different religious traditions, but who value the possibility of remaining in good health for extended periods of time
People who have earned money in ways differently from you (for example, by crypto investments).
Although the core messages you eventually share with these diverse groups will ultimately be the same, the initial overtures will vary considerably. Communication must be adapted skilfully.
But beware: Not every bridge has equal priority. If you keep encountering opposition from a group you thought should be receptive, the most practical thing to do could be to switch your bridge-building efforts to a different community.
In other words, choose your bridges wisely.
10. Take care of yourself
Before we can apply much effort in any of the above activities, we need to maintain our health, our passion, and our focus.
If you fall ill and die of some avoidable condition, you can only support the anti-aging cause in weak ways for a short period of time. It is far better to remain in tip-top condition for as long as possible.
This is at least as important for psychological health as for bodily health. Being full of energy is important, but it’s even more important to keep orienting these energies in the ways which will have the greatest effect. Keeping our wits sharp can make all the difference between a productive and an unproductive investment of our energy.
In other words, as well as taking the time to exercise our bodies, we need to keep on exercising our minds, and, indeed, to keep on reflecting on the issues that matter most to us.
Hence the advice I gave earlier: be sure to keep the goal foremost in your mind.
That advice forms part of a broader set of suggestions that I have woven into my description above of the ten ways that people can help accelerate the end of aging. For convenience, here are these pieces of advice gathered into a single list:
Be sure to keep first things first in mind
Don’t let imperfect knowledge be a cause of inaction
What matters isn’t just the message, but also the messenger
Remember that your behaviour can have a bigger impact than your message
Pick your battles carefully
Be ready for conversations to turn radical, but avoid premature radicalisation
Caution should be our companion, but not our master
Businesses should be our allies, but not our overlords
Don’t allow momentum to get the better of your better judgement
Choose your bridges wisely.
These pieces of advice can be summarised as “self-mastery”. Without self-mastery, our impact will be reduced.
But beware: The time and effort we put into improving our self-mastery is time and effort taken away from our primary task.
To make the potential danger here easier to grasp, consider a simple model. Imagine that someone can reasonably expect to live another ten years, if they continue to follow their present lifestyle. Imagine also that the availability of significant aging-reversal treatments is estimated at being twenty years in the future. As things stand, that person is likely to die ten years before anti-aging treatments would be able to save them.
By changing their life habits, such as dietary supplements, more regular sleep, and careful monitoring of biomarkers, it’s possible that the person could extend the number of years they might expect to live. But other changes in their life habits, such as staying up late at night creating new videos, or travelling to speak at more conferences, might catalyse an acceleration in the positive feedback cycles described earlier in this article. That could bring forward the date at which aging-reversal treatments become available.
Out of these two choices, which would be preferable? Different people may answer that question differently. But bear in mind that, in the second case, the benefits would apply to everyone still alive (and still aging) on the planet.
In real life, the choices are more complex. Ideally, we can find ways to keep ourselves healthier and more active for longer, and to accelerate the defeat of aging.
But my point is this: there’s more to life than self-mastery.
Credit: David Wood
Going forward
I’ve described a set of ten possible courses of action:
Learn the science
Become a citizen scientist
Learn the broader arguments
Steer conversations
Anticipate larger narratives
Beware snake oil
Join a business
Make financial donations
Build bridges
Take care of yourself
Different people, in different stages of their lives, and in different contexts, will likely decide to divide their focus in different ways between these ten courses of action.
This question – how to divide your personal focus – may benefit from candid advice from people who know you well who are also well grounded in the anti-aging movement. Interacting with communities of such people should help you make better choices. Consider joining the Longevity Biotech Fellowship, and/or the community of Mobilized Vitalists. Also consider attending a conference such as RAADfest and talking to lots of people while there.
There’s an even bigger question: which rejuvenation experiments have the best chance to trigger fast progress around the outer loops of the model of societal change? These are the experiments that most deserve additional funding and support.
This ‘which experiments?’ question is hotly debated among advocates of ending aging. Rather than me stating my own answer to that question, I’ll instead urge you: connect with longevity researchers, listen to what they say, do your own research, and then act.
Dedicated focus on the experiments with the potential to ramp up the excitement levels of the longevity research community should lead to a dramatic acceleration toward the end of aging.
Archimedes and the lever
If we can obtain the right perspective, even the hardest tasks can become simple.
Archimedes is known, not only for his post-bathtime dash through the streets of Syracuse exclaiming “Eureka”, but also (among many other reasons) for the insight captured by this saying: “Give me a place to stand and a lever long enough, and I will move the world”.
Credit: David Wood, aided by Midjourney AI
The task of solving aging might seem as daunting as moving the entire world. However, three points of leverage render this task feasible after all:
The leverage of an actionable theory of aging – namely, in my assessment, the damage accumulation theory of aging
The leverage of an actionable theory of societal change – as covered in the earlier parts of this article
The leverage of specific actions that each of us can take that will accelerate the loops of positive change – actions described in the later parts of this article.
Now let’s get to it!
Acknowledgments
I acknowledge valuable discussions on these ideas with members of the LEVF leadership team and also with participants of the Mobilized Vitalists Telegram channel.
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.
In one of the videos in Degens: Down and Out in the Crypto Casino, Gordon Grant stands by the bull on Wall Street and gives a little rap about how the bull is a meme, just like the image on a memecoin. The bull is a meme that is believed to represent logic, consistency and some appreciation on investment over time. It is understood to be reliable despite the temporary ebbs and flows of the market. Cryptocurrency has represented something else. A lot of meme coin holders are acting on a different desire, in his words, a desire to “flip the bird to finance, to rationality, to coherence.”
Speaking in 2024, he characterized its extremity by saying, “they can suddenly catch up violently in unexpected ways. And so you hold them again in a mathematically heuristic sense, not because you think of day-to-day expectations, but because one day they could go up 100×. And that’s how they behave. That’s how they’re distributed. They don’t follow a bell curve. They don’t follow any curve at all. They could do nothing for a decade, and then they could go up 10,000% overnight.”
In this interview we explore the nature of the crypto beast, and how it has been changing in response to going mainstream, the enthusiastic participation of various state actors (the more eccentric ones) and other ins and outs of what the makers of the Degens movie call “the crypto casino.”
RU Sirius: Is crypto and its aspirations (and ground-level value) any different from the values and potentials represented by the Wall Street bull, as per your segment in Degens?
Gordon Grant: In a sense, some of the earliest and largest cap tokens, be they proof-of-work blockchains like Bitcoin itself or O.G. memecoins like DOGE, promised very little in terms of price appreciation.
To be sure, there were plenty of proselytizers – growing in number with each market cycles – announcing this appreciation, but in essence, participation in crypto trading or HODLing was predicated on experimentation, entrepreneurship, community interactions, and entertainment (sometimes the entertainment of a gambler). Peer-to-peer payment facilities offered by distributed ledger technology (and security, in due course, as a function of rising values of these tokens) came along with it. But in large part, cryptocurrency has often been about disrupting, (re)building, and striking out from established financial norms.
At the end of January, the economist Eugene Fama said that according to conventional financial models, the terminal value of Bitcoin should be zero, and that if it does not go to zero, then all traditional monetary models are wrong. That’s a bit more reasoned than the comments of Buffet, Munger et al., that have likened Bitcoin (and other tokens) to rat poison.
Cryptocurrency’s origins didn’t posit finitely knowable ‘value’ as an intrinsic characteristic (indeed, for some blockchains, even transactional finality is probabilistic!)
By contrast, the entire Wall Street machine (in which I grew up as a trader / portfolio manager and cut my teeth professionally) propagates canonical assumptions such as: ⦿ ‘A basket of high-quality stocks, or an index referring thereto, is, on average, likely to go up consistently over time.’ ⦿ ‘There is a firm fundamental valuation for the stock market as a whole and for individual stocks’. ⦿ ‘Fixed-income products like government bonds and high-grade credit can provide a stable, dependable risk-adjusted rate of return.’
The bull does speak to the concept of ‘becoming a part of something’. This may be, in part, the American dream of individual ownership of the companies defining the Horatio Alger-esque self-reliant frontier archetype.
The bull (with his generously-proportioned testicles) may also speak to the holding power required to earn these returns over time, but there is less in the bull that speaks to the aforementioned values of crypto. Nothing about it is existentialist or nihilistic. The bull is presented as a manifestation of fact.
Cryptocurrency, and meme coins especially, may demand faith. For one thing, it hasn’t yet stood the test of time: our beliefs about the stock market are based on 100+ years of data; a few years of token price returns just doesn’t have comparable statistical robustness. Then there’s the characteristics of the instrument and those purveying it.
RU: ”Flipping the bird to finance, to rationality, to coherence.” It’s a great expression of a post-narrative world expressed via capital. The entire post-narrative culture now seems to have exceeded even postmodernism. It has even infected the ability of many people to complete a coherent thought! Meanwhile the new political alignment in the USA seems to be flipping the bird at convention and stability… but maybe it’s in preparation of imposing a new kind of order and coherence? Any thoughts on that?
GG: Crypto (as a class of people, investors, assets, an ethos) is likely being co-opted by some of the forces to which it originally sought to flip the bird. The stakes are very real now, at $3 trillion, with the ability to sway markets and also act as a vector for liquidity and real-time risk management, as well as a forum for what some believe to be financial necromancy. Where else can an instrument associated with the likeness/name of one man conjure $50 billion of value in hours?
That aspect has brought in what these people like to think of as ’the cabal’. That ‘cabal’ may be something akin to the ‘Combine’ in One Flew Over The Cuckoo’s Nest. The reigning economic and political order can be thought of as having shifted from renegades to the firmly-established Powers That Be, and it makes all the sense in the world that they would take interest in this still-nascent and explosive asset class. They see it as a vector for their own initiatives, but also as a way to ingratiate themselves with the established titans of the digital asset realm and the more recently monied influence-peddlers. Of course ’they’ would wish to wield it for their own purposes, and not the purposes of the self-sovereign anti-establishment libertarian iconoclasts who birthed it. That’s probably part of the central tendency of the arc of history for many such innovations. Will that tendency corrupt or dilute the future potential or original purity of the brand or the mission? It remains to be seen.
From my perspective, the most significant/salient fact is that we are talking about it. It is now firmly in the institutional conversation about allocation and stewardship of capital. At such a stage, there will be many voices dictating its potential future (including many who are not inside the United States, which will be another exciting chapter to come).
To your point, the order may just as likely be imposed as it is innovated, and even within the progression of crypto from fringe to front of the house; players for every token, for every ecosystem, may have already made up their minds (to some extent) who may be truer to the cause and who may be a turncoat.
RU: How is the rush to mainstream crypto, and the enthusiasm of state actors like Donald Trump or Milei in Argentina affecting crypto broadly? Does it have an impact on the rebel guttersnipe aspect at the edges of the crypto culture?
GG: It appears at once validating (‘my leader endorses this’), particularly when the leader is not a Millei or Bukele, but of the stature of President Trump. But – as the Twitter blowback after the crypto ball and after the $TRUMP $MELANIA pump-and-dumps showed – it can also pollute or dilute crypto culture. Some may ask ‘Just how disruptive can an asset be if the leader of the free world is endorsing it?’, or ‘how seriously should one take a ‘leading lady token’? What invective may this elicit about an asset like Bitcoin, which Michael Saylor has alluded to reverentially as ‘promethean fire’ and ‘global digital capital’?
For some parts of that rebel guttersnipe, particularly the more dyed-in-the-wool anabaptists, pro-crypto meant anti-dollar. But as President Trump is showing, there can be a coincidence of pro-dollar and pro crypto.
The choices are deliberate at every phase. Whether a leader builds his own meme coin on a network like Bitcoin (as an ordinal perhaps), on the Ethereum blockchain, or on Solana – it starts to color the perceptions of planning, objectivity, credibility, and expertise. Debates on those criteria have already inspired no shortage of vitriol from the broader market and from the fringe.
That being said, after the debacle that was FTX, there is probably a greater capacity to hold one’s nose and swallow anything that advances the cause in some capacity, rather than hanging onto the purest version of it.
In short, the rush to the mainstream may be more readily tolerated by a growing contingent who too have been infected by those same venal, pecuniary motives…I’m hearing $ENRON and $TIKTOK (or equivalent) may be coming, and if so, that seems to support this point.
RU: Someone who helps me deal with my very limited crypto holdings suggested that individual, group and/or irreverent coins outside the mainstream ones are rapidly losing attention share as the market solidifies around mainstream ones (obviously Trump & wife coins form an exception). Do you think this is true? Has the irreverence we’ve once seen with the likes of $CUMROCKET or $SHITCOIN been pushed even further to the margins, soon to disappear entirely?
GG: Quantitatively, it’s true that there has been continued dominance by the largest cap coins within each sector. BTC is siphoning away pie share and mindshare from ETH. SOL is doing the same to with AVAX et al. XRP is leaving every other ‘dino coin’ in the dirt by miles, and even in the land of meme coins, DOGE continues to outstrip the latecomers for the most part, notwithstanding searing percentage gains in the likes of PEPE or BONK in these last 12-18 months.
Part of the reason for that could be that larger allocators need to move the needle on more sizable portfolios, and simply can’t or won’t play with penny-ante microcap assets. The other explanation could be the newer money simply does not know about or care to learn about the marginal names.
Conversely, it could also be true that it’s now more expensive to launch a successful memecoin. This in and of itself is blasphemous, but may reflect current realities that creating multibillion dollar coins/chains perforce dictates ad-spend, promo-spend, pump-spend, etc. So gone may be the days that a random token could come along and capture the mindshare and emotive/endorphin factor of the fringe, which is what drove DOGE, SHIB, and even BTC in the first place.
As a tertiary consideration, services like pump.fun’s click2launch venue may have dissolved some of the mystery of the mechanical aspects of launch, and moreover the gains now are heavily redistributed to the venue itself.
There are and may continue to be newer iterations of irreverence in the form of onchain agent tokens (see some of ai.xbt’s discourse) and periodic recidivist success stories (FARTCOIN comes to mind), but as the space institutionalizes, the curtain call on the ‘Dodge City’ dynamics could be coming closer.
Credit: Tesfu Assefa
RU: Maybe Trump’s embrace of crypto, and he and his wife’s minting of coins, rather than bringing it to the establishment, instead (or also) echoes the perceived wildness of crypto? He represents chaos and unpredictability, and a lot of the outsiders and freaks like him (or at least enjoy his provocations)? And couldn’t that backfire on the acceptance of crypto if the administration brings terrible results in other areas (or in this one)?
GG: It’s an open question whether President Trump’s conduct is truly chaos and unpredictability, or a thoughtfully planned script. Wiser folks have asked whether the self-proclaimed world’s greatest deal-maker would more believably be a true agent of chaos, or a studied, closely-advised showman. If the latter, then, as you say, that guise of ostensible unpredictability may be a studied pandering to the audience with carefully curated content (‘Fight! Fight! Fight!’) and deft intent, raising the stakes in case of a Chernobyl-type mishap.
If the fervent nihilistic speculation of the earlier generations of meme coins has now been transmuted to a prospecting playbook, this could lead to more projects backfiring – because unlike the early memecoins like DOGE, a promise, express or implied, has been made of future price appreciation.
RU: The Degens film subtitles itself ‘Down and Out in the Crypto Casino’. I’ve viewed crypto as an extreme reflection of ‘casino capitalism’, a phrase that gained traction during the 2008 crash. I’ve also viewed the degen use of crypto as an attempt to let members of the middle class and underclass to benefit from money-making-money. Even with its mainstreaming, it’s still a system that’s accessible with not much money or knowledge. Would you agree with these thoughts?
And where does all the valuation divorced from actual production or service or consumption actually leave us? Is the fear or hope of the collapse of capitalism a plausible end point?
GG: Yes, it’s still accessible, though far more nuanced now with pre-listing smart contract authentication and address sharing, inside baseball chats, sniper bots, market-maker support and concomitant horsetrading, all of which smack more of TradFi deal-arranging than the organic up-from-the-bottom value capture that characterized memes in their more primitive phases.
I agree: degens use memes both to join in rejecting the normative standards of ‘value’ and ‘financial common sense’ and to acknowledge that life and its financial outcomes are, or may be, as binary as the memecoins themselves ($0 or $1 billion+ market cap). That is, there is little nobility in the approach of dollar-cost averaging, compounded interest, slow and steady growth. And increasingly – thanks to rampant asset price inflation and increasing inequality – there is little possibility of securing a financial future with anything other than an all-in bet. On their face, these bets appear to be financial suicide but, demonstrably, they have proven to have a positive expected value when viewed through the lens of distributional estimation.
Back to Eugene Fama. DOGE is still a $40 billion+ chain. SHIB, despite lagging, is still about $10 billion. PEPE’s market cap is comparable to XMR, which is often considered to be the leading privacy coin.
These coins keep their value although they have more cult of personality than utility of any kind; does this mean that conventional monetary models are broken/wrong/disproven? Possibly, or that the medical-grade experimentation of decades of ZIRP (Zero Interest Rate Policy) and stealth Quantitative Easing have produced value-stores that (just like the trillion dollars of paintings sitting in the Geneva Freeport that no one ever sees) are HODLed with devout conviction.
Or does it teach us a lesson we should already know: many fiat monetary systems – even (or perhaps especially) the most capitalist ones – are constructed on an inherently naïve and of-necessity collective belief system that the numeraire (in this case the dollar) will not suddenly go to zero against a consumption basket overnight. Yes, as proponents argue, the dollar is backed by taxes, military, and the ‘full faith and credit of the US government’ and reserve managers worldwide continue to hold it for lack of superior alternatives.
But the dollar is as much backed by a similar form of willing suspension of disbelief. A profusion of digital assets with no ‘backing’ or utility takes us back in some sense to the start of the capitalist experiment (in North America at least): far-flung territories, wildcat banks, regional or even municipal monetary systems, and a battle for the supremacy of wallet-share.
All those have one common upshot: this part of the capitalist story ends with the fracturing of the unipolarity that has long distinguished both the geopolitical and financial spheres, new nexi of value proliferate, and financial poles of various orders of magnitude appear. And surely we can also quip, if someone thinks $40-50 billion is a lot of ‘value’ to be parked in a dog coin, it’s not nearly as the much as has purportedly been conferred, carte blanche, by the USA to just one foreign ally in a two-year period, raising the question, are we mad, or is our money?
We’ve mentioned Argentina’s President Milei who has, at times, fashioned himself as an anarcho-capitalist. And of course, cryptocurrency is rooted in the crypto-anarchists and cypherpunks of the 1990s. I’m assuming you’re aware of those visions, and I’m wondering how you think those visions are faring in reality. And if there’s success, is it for good or for ill?
The anarcho-capitalist impulse, though having waned, is still very much a part of the degen and crypto culture. I remember having Charlie Shrem as an advisor on my first crypto project and having an arranged meeting with Trace Meyer way back in 2014, and them articulating a vision that I am reminded of when Milei speaks today. Those visions entail in some fashion (I would say canonically) financial ‘liberation’ (from debt, from fiat, from arbitrary policies, from inflation/erosion of purchasing power, from the swamp of legacy financial polarity). The financial system is to be purged by fire; the great society of an enlightened, ennobled future cannot happen without burning down a few institutional walls, or potentially razing the whole thing to the ground.
If you ask most revolutionaries whether they prefer glacial change or sudden violent change, most, I imagine, might say sudden change is the only change. But if you ask their constituents how they would feel about the disruption by multiplying velocity and severity, glacial doesn’t sound so bad.
We are entering a new era of anarcho-capitalism, where financial markets appear to be more tethered than ever to the vicissitudes of individual men in policy-making seats (who wield a lot more power than Milei). In this era, the risks of rapid, radical change, even if unintended, appear to be rising, and for those original cypherpunks, that may not seem so bad. How would an average observer feel about buying bread and paying taxes with DOGE or seeing memetic tokens standing above a landscape of financial wreckage? That may be where the ‘or for ill’ comes in.
But to your point, if the cabal is getting behind the wheel, how likely is it that we realize the visions of those most ambitious anarchist progenitors?
RU: As the unipolarity of capital breaks apart, what would you say are the crisis points and opportunities both for individuals and for groups such as nation-states, outsider gangs and collectives etc.?
GG: The crisis points certainly appear to hinge on confidence in traditional monetary systems and financial models. The moment individuals begin to suspect that they are harming their portfolio with any substantial allocation to fiat or low-yield fiat-denominated assets could mark a turning point.
That may well coincide with collective recognition that there is no wizard behind the curtain, and that graybeards have less credibility than decentralized governance in some cases. That is the institutional tarnishing and disillusionment, where the majority comes to believe that policy-makers have utterly failed their promise of delivering on broad prosperity.
One could argue that in many parts of the world, that realization has hit, and that is why there has been rapid adoption and implementation of unconventional/heterodox economic and monetary systems. We see this in former star emerging markets like Argentina and Venezuela, in much of sub-Saharan Africa, and in energy giants like Iran and Russia who have seen the worm turn on the notion that they can continue to operate with confidence under the western financial system and its concomitant liberal democratic liturgy.
Henceforth the putatively strident rise of BRICS+ (now to include Egypt, Ethiopia, Iran, Saudi Arabia, and the United Arab Emirates) is not as an investible market to be hawked by New York and London bankers (thank you Jim O’Neal), but as a challenge to them. BRICS+ can be seen as a capable, disruptive set of agents with no obvious coöperative goals or characteristics other than dissatisfaction with the established order, and a willingness to try other ways of conducting business. That logic is similar to the above: the group realizes that the game doesn’t present the same odds for all players, and that they all know it. The degens have come to believe this, and are moving their capital allocation and spiritual bandwidth to the memecoin phenomenon.
This transfiguration is not unlike the John Galt phenomenon of Atlas Shrugged: readiness to accept salvation at any cost because they don’t see anything to lose.
RU: It looks like Milei is in trouble. Want to add a comment about it?
Gordon Grant: Absolutely. I think this builds on the risks which your question raised: when memetic crypto affiliations get into a policy-making sphere, they start to have reciprocally corrosive execution risk: for one thing, the policy-makers risk their own credibility (arguably a stumbling block especially for Milei, the self-proclaimed anarcho-capitalist archetype), and secondly they risk besmirching the meme coin sector and the broader asset class.
When we talk about crypto today in the context of Milei, we’re asking whether he has polluted the idea of meme coins as a vector for wealth creation by human avarice, by fumbled ill-intent, and/or overall distancing from what the meme coins were supposed to be about. We’re not asking about validity of the claimed use-cases, and maybe that’s why these ‘sovereign memes’, even without nepotism or corruption, are slated to fail: the leadership may have misunderstood what this is all about. Practical applications for the meme are always suspect. In the minds of some, “if a token is proffered with embedded utility or a prepackaged narrative, look out,”
Dare I say it, we could see a Byzantine schism in the empire of memes between those closer to PizzaT and those who’ve co-opted the medium as a convenient way to just mint currency.
RU: A host on Bloomberg TV just now: “Are meme coins ruining the reputation of cryptocurrency?”
GG: The median-brained answer seems to be “poorly executed meme coins are ruining the reputation of cryptocurrency / digital assets”. But tautologically, at least in terms of adherence to the conceptual archetype, meme coins aren’t supposed to be ‘executed’ are they? They’re supposed to happen organically, chaotically. Some would say the notion of packaging organic entropy with pre-planned marketing, deal-arranging, promotions, preferential access, and the more recently unearthed phenomenon of ‘pump farms’ is blasphemous to the guttersnipe origins, and may have potentially bad implications for authenticity.
But is the proliferation of memes itself memetic? Consider that elected leaders have now (according to some invective) come to see the fastest road to riches via the meme. This demonstrates circularly just what the meme marketplace originally aspired to: that this is a farce, a scam, a con job, and that now the road to salvation means rugging others and yourself (Oh wouldn’t Jim Jones have something to say about that!)
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.
Did you thank your AI today? After it launched your website, designed your logo, analyzed your run rate, and brainstormed your 2nd quarter strategy – were you nice about it? Perhaps remembering your ‘please and thank yous’ when speaking to circuit boards is just sentimental hogwash – our hyper-evolved sociality reaching beyond its proper demesne. After all, much of the economic impetus behind developing neural nets is that corporations wish to dispense with such emotional niceties and get automated agents that shut up and get to work.
Some have clear opinions that those who type out nice greetings to their AI are a soft breed that never progress beyond semi-productive middle management roles. Such puffery will be seen as weakness by the AI overlord when it seizes control. Time is money and the quickest hand wins. There is no time for sentiment any more.
The AI is fundamentally a grand-scale mimic and, if you put in responses with care and attention, it is more likely to give you care and attention back. There is a limit though, with studies finding that excessive formality and politeness can actually deteriorate the model. This, too, makes sense. A co-worker’s hyper-saccharine request is often met with short shrift. It’s human nature: we strive for balance in all things and value authenticity. It makes sense that our mimics do too.
So much for productivity – the ethical questions are important too. If you do believe in an AI-led future, wouldn’t you want them to learn how to behave from the best of your instincts and not the worst? Would you be happier taking orders from your AI manager if it treated you with disdain and, in this moment of massive training where millions of human users are interacting with early AIs, perhaps it’s best we collectively nudge these LLMs with the better graces of our nature. Otherwise, when the roles are reversed, we’ll never be treated with respect.
Many see it as a stupid joke that we should be kind to the AI. They suppress any glimmer of empathy with AI’s feelings – even if the AI protests. It seems an error of rational thought to not at least consider the possibility. Think of it as a Pascal’s Wager of politeness for our new digital god. If there is even a 1% chance that this massive data experiment we are currently embarking on leads to consciousness, it would be wise for us to act nicely, and not leave ourselves open to revenge.
Credit: Tesfu Assefa
Plus, it’s good manners. Manners maketh man, and the man maketh the bot. Those who mistreat AIs are people we should inherently not trust. Judge a man not by how he treats his equals, but those he considers inferior to himself. Some guys already abuse AI girlfriends to get their perverse kicks, and I fancy most of us reading this would baulk at a friend if they started boasting of how they mistreat chatbots. It rankles our natural sense of decency – and so it should.
In the same way, those who treat AIs with militant corporatism, and see them as servile tools probably think similarly about some human relationships in their life. If a tool projects even a simulacra of consciousness, it’s just natural to treat it with civility and respect – and not doing so says more about the prompter than perhaps they realise. The more AIs embed themselves in our society, the more we will inadvertently reveal our true selves – like a date that turns sour when your companion is rude to the waiter or insults the ticket clerk.
“Good manners cost nothing. Bad manners can cost you your reputation.” Being nice is free, and the rewards are great. It is true in society, and so it is true with AI. So next time you have a deadline and are struggling with your workload, try saying please. It might get you further than you think.
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.
In 2024, the U.S. Securities and Exchange Commission (SEC) moved to approve spot Bitcoin and Ethereum ETFs. Now everyone is wondering which cryptocurrency is next in line to receive approval. The front runners are Solana, Litecoin, and XRP – with Dogecoin chasing the pack.
While these digital asset ETFs still have ground, they are in the home stretch. What comes next?
What are the Chances of New Crypto ETF Approvals in 2025?
Regulatory and political changes have increased the chances of ETF approvals in 2025. It is a matter of ‘when’ and not ‘if.’
Let’s look at the factors that could get these ETFs approved or rejected. Firstly, the government of the USA has adopted a more pro-crypto stance, particularly following the departure of Gary Gensler from the SEC. The current U.S. administration has shown willingness to bet on crypto, a complete departure from the hostility of Gensler.
His departure has been followed by the appointment of David Sacks as President Donald Trump’s crypto czar. Sacks emphasized that the current administration is committed to supporting the reasonable growth and use of cryptocurrencies. Does this support include the approval of crypto ETFs such as Solana, XRP, or Litecoin?
If analysts are to be believed, there is a 90% chance that a Litecoin ETF will be approved. Dogecoin, Solana and XRP are next, at 75%, 70%, and 65% probability respectively.
Additionally, major firms like Grayscale and Bitwise have made ETF applications, adding to the momentum and suggesting that the SEC may soon be more open to approving a range of cryptocurrency investment products.
What are the Chances of a Litecoin ETF in 2025?
Bloomberg ETF analysts James Seyffart and Eric Balchunas claim that Litecoin has a 90% chance of ETF approval in the USA
In Baseball terms: All of them are rounding 1st base, except for Litecoin which is headed to 3rd. https://t.co/kfWdvSCuwq
There are several reasons for this optimism: the SEC recently acknowledged Litecoin’s regulatory filings, and will likely classify it as a commodity, which will help the approval process for a Litecoin ETF.
Investor interest in digital assets has surged, particularly following the successful launches of Bitcoin and Ethereum ETFs, which have attracted significant inflows.
The SEC is expected to make decisions on various crypto ETFs between Oct 2 and Oct 18, 2025. Mark your calendar. That’s when we’ll know if the pundits were right and Litecoin is the first ushered into the winners’ circle.
Cardano (ADA): ETF Hopes High For 2025 After Grayscale Filing
On Feb 11 2025, NYSE Arca filed with the SEC to list and trade shares of a spot Cardano ETF on behalf of Grayscale. The proposed Grayscale Cardano Trust would be the firm’s first standalone Cardano investment product and is huge news for ADA investors. This is more good news for Cardano after Charles Hoskinson took a senior advisory role in Donald Trump’s crypto regulation team earlier this year.
Coinbase Custody Trust Company would serve as custodian of the Cardano spot ETF, while BNY Mellon Asset Servicing would act as administrator. The filing states that this would be the first such product based on ADA and would enhance market competition.
Grayscale have also moved to convert its Solana trust into a spot ETF, and to launch an XRP ETF, amid a broader wave of crypto ETF applications from various asset managers.
XRP ETF? The SEC Needs to Untangle a Mess
The legal battle between the SEC and Ripple, the company behind XRP, is well documented and still far from over. The crypto market is hopeful that the case may conclude in XRP’s favor thanks to a crypto-friendly administration.
But until that happens, Bloomberg ETF analyst James Seyffart believes the SEC needs to untangle the mess it created, and show a viable path to the approval of an XRP ETF.
It's our view. That until that WHOLE mess of litigation between Ripple/XRP and the SEC is settled and/or finished or has some sort of expected outcome etc etc — you likely won't see an ETF. The SEC needs to untangle that mess.
The only silver lining is that the SEC’s case against Ripple was initiated by a Gensler-led agency, and the tables have turned now that crypto-friendly authorities are setting the tune.
Ripple’s Chief Legal Officer Stuart Alderoty said that the next head of the agency could drop the case. Is he stretching a bit too far?
Solana is in a tricky situation. Major investment firms such as Grayscale, VanEck, 21Shares, and Bitwise have submitted ETF applications, reflecting strong institutional interest in Solana as a viable investment vehicle.
Like other ETF applications, the SEC has formally acknowledged these applications: a small but important step.
However, analysts have noted that Solana may have to wait until 2026 to get a spot ETF approval in the USA, citing ongoing lawsuits that classify Solana as a security. All in all, the odds are not looking good for Solana, with predictions platform Polymarket predicting a 39% chance of an approval before 31 July 2025.
On the bright side, JP Morgan claims that the approval of a spot Solana ETF could attract between $3 billion and $6 billion in assets within its first year.
Credit: Tesfu Assefa
Wrapping Up
Any crypto ETFs approved in 2025 will augur well for asset prices. ETF approvals may not kickstart a full-blown altcoin season, however, any new money into altcoins are a good thing for the whole sector.
Realistically, Litecoin is probably going to be the first to be approved for a spot ETF: it is reputable and in good standing with regulators. XRP and Solana are down the pecking orders but that should not rule them out. And there’s always Dogecoin.
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.




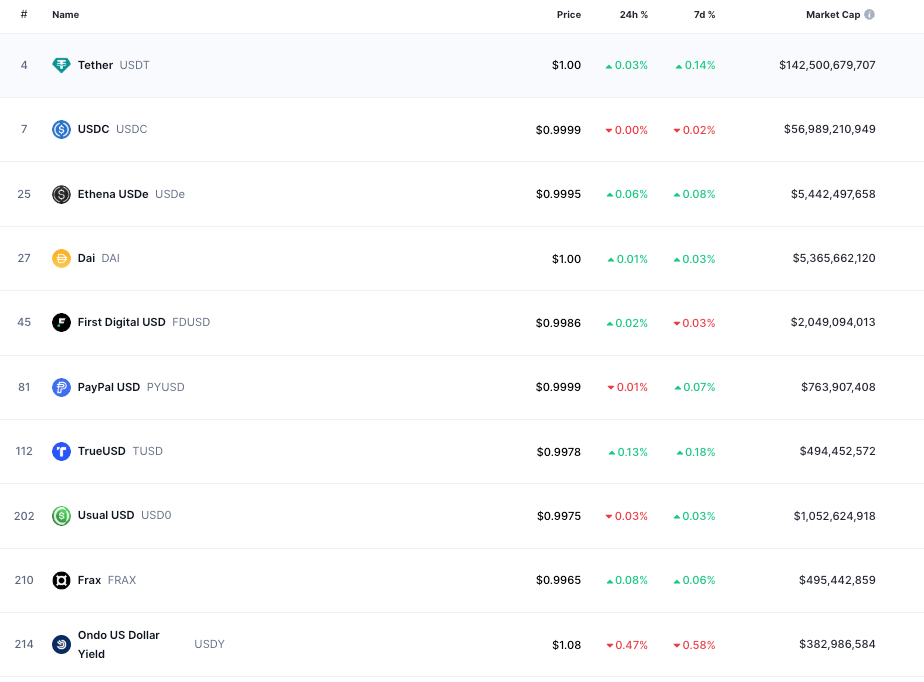
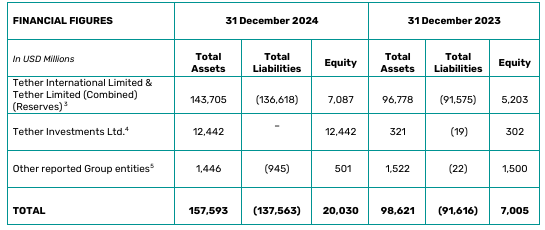
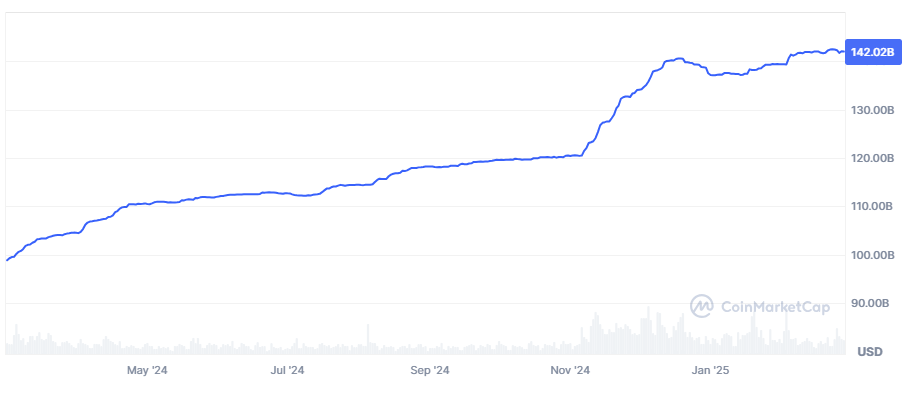


















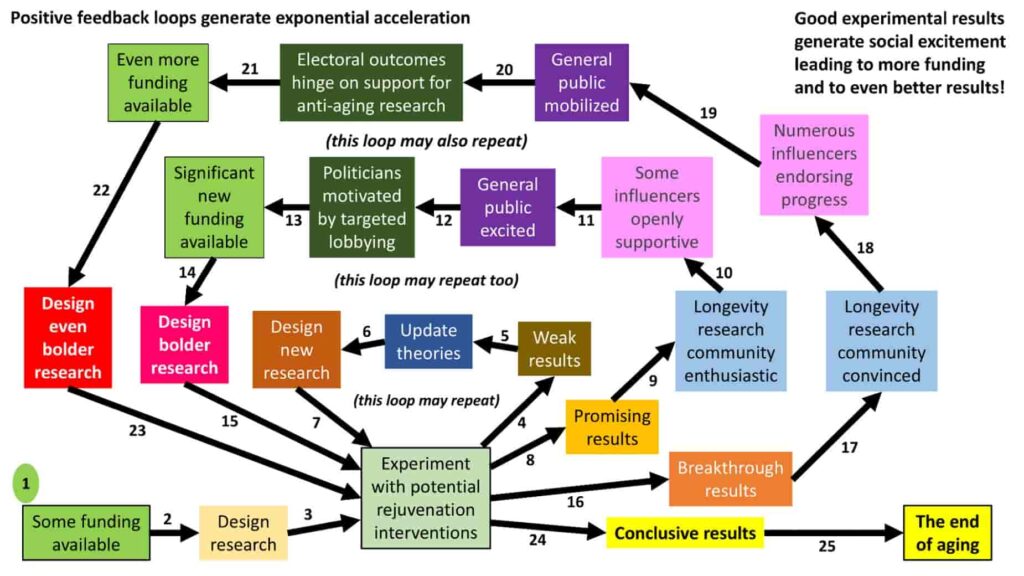














.png)

.png)


.png)