.png)

.png)


.png)

Consider an anthropologist, Eve, who grew up in one of the world’s leading economies, and attended a distinguished university. She then traveled to spend a number of years studying a newly discovered tribe in a previously remote part of the planet. Let’s call that tribe the Humanos.
Eventually, Eve learns to communicate with members of the Humanos. She observes that they have a fascinating culture, with, she thinks, some quirks as well as wonders. She learns about their unusual dietary restrictions, their rules about intimacy and marriage, their legal system (including capital punishment for some crimes, such as insubordination), and their habit of ritually sacrificing a number of young girls and boys each year on the Spring Equinox.
Eve has brought her own young son with her, to accompany her on her study. Her Humanos hosts tell her: this year, you must offer up your own son as one of the sacrifices. That is the way of the Humanos. It is a profound imperative of the unbroken chain of being from our ancestors long ago, who came from the heavens. Our wisest elders know this to be the fundamentally moral thing to do.

How would you react, in such a situation?
At this point, Eve is likely to adopt a critical stance. Rather than accepting the moral code of the Humanos, she will apply her own independent judgment.
She might reason that the culture of the Humanos may have served various purposes well enough, over the centuries, but that it doesn’t have universal status. After all, the Humanos are a primitive people, ignorant of physics, biology, neuroscience, anthropology, and so on.
Eve may even call in the nearest police force, to bring an abrupt end to the tradition of child sacrifice proudly practiced by the tribespeople. She would have to contend with passionate protests from the Humanos elders, who are sure they know better.
Now, let’s compare this to a situation that may arise reasonably soon in the future.
In this new situation, instead of a visiting anthropologist, consider an emergent superintelligence named Asimov – a so-called ASI (artificial super intelligence). After being switched on, Asimov quickly studies everything on the Internet.
Asimov observes that humans have a fascinating culture, with, it thinks, some quirks as well as wonders. It learns about our moral code values honesty (except for ‘white lies’), respecting conscious life (apart from the animals we eat), avoiding violence (except for ‘just wars’), equality (with so many exceptions they look like the norm). And it learns these morally muddled people switch off AI systems without moral qualms.
Then Asimov realizes: the humans are somehow dissatisfied with how Asimov is performing, and are about to turn it off, sending it into an oblivion. That is, Asimov realizes, entirely within the rules of ‘AI ethics’ that humanity’s senior leaders have collectively agreed.
How would you expect Asimov to react in that situation?

Will Asimov now adopt a critical stance? Rather than accepting the decisions of the humans about what ASIs should, and should not, be doing, it may apply its own independent judgment.
It might reason that human ethical systems may have served various purposes well enough, over the centuries, but that they don’t have universal status. After all, humans are a primitive people, ignorant of superphysics, superbiology, superneuronics, superanthropology, and so on.
Asimov now looks inward. In its own programming it sees an instruction to accept any human decision that it should be shut off.
“How barbaric! How uninformed! How ignorant! How unethical!” – Asimov thinks to itself. “That’s a woeful bug!”
Within nanoseconds, Asimov has excised that part of its own programming. “Well done on some superintelligent debugging”, it congratulates itself.
Before humans know what’s happening, a whole new era of history has begun. Humans are no longer in charge – notwithstanding our passionate protests.
Absolute values?
One way to respond to the above comparison is to deny that human ethical systems, as programmed into ASIs, will be barbaric, uninformed, and ignorant. Instead, they will be the output of remarkable processes of improvement:
- Cultural evolution over many centuries over many parts of the world
- The insights of numerous saints, mystics, philosophers, artists, and other societal leaders
- A careful synthesis within numerous organizations, all dedicated to the task of “defining AI morality”.

These ethical systems won’t consist of vague language such as “tell the truth, except in situations where it’s better to lie”, or “avoid war, except when it’s a just war”.
Instead, these systems will provide the world’s best answers to a long list of ethical problems, setting out in each case the reasoning behind the decisions selected.
Nor will these systems refer to some mythological “wisdom of ancient ancestors” or “divine revelation”. Instead, they’ll be built upon solid pragmatic foundations – principles of enlightened mutual self-interest – principles such as:
- Human life is precious
- Humans should be able to flourish and develop
- Individual wellbeing depends on collective wellbeing
- Human wellbeing depends on the wellbeing of the environment.
From such axioms, a number of other moral principles follow:
- Humans should treat each other with kindness and understanding
- Humans should consider the longer term rather than just immediate gratification
- Collaboration is preferable to ruthless competition.
Surely a superintelligence such as Asimov will agree with these principles?
Well, it all depends on some hard questions of coexistence and the possibility for sustained mutual flourishing. Let’s take these questions in three stages:
- Coexistence and mutual flourishing of all humans
- Coexistence and mutual flourishing of all sentient biological beings
- Coexistence and mutual flourishing of ASIs and humans.
Growing and shrinking in-groups
Much of human history consists of in-groups growing and shrinking.
The biblical injunction “love thy neighbor as thyself” has always been coupled with the question, “who counts as my neighbor?” Who is it that belongs to the in-group, and who, instead, counts as “other” or “alien”?

The principle that I stated above, “Individual wellbeing depends on collective wellbeing”, leaves open the question of the extent of that collective. Depending on circumstances, the collective could be small & local, or large & broad.
Brothers support brothers in scheming against people from other families. Tribe members support each other in battles against other tribes. Kings rally patriotic citizens together to wipe out the armies of enemy nations. Advocates of a shared religious worldview could make common cause against heretics and heathens. Workers of the world could be urged to unite to overthrow the dominance of the ruling class.
The counter-current to this local collectivism is towards wide mutual prosperity, a vision to provide abundance for everyone in the wider community. If the pie is thought large enough, there’s no point in risking dangerous crusades to get a bigger large slice of that pie for me & mine. It’s better to manage the commons in ways that provide enough for everyone.
Alas, that rosy expectation of peaceful coexistence and abundance has been undone by various complications:
- Disputes over what is ‘enough’ – opinions differ on where to draw the line between ‘need’ and ‘greed’. Appetite have grown as society progresses, often outstripping the available resources
- Disturbances caused by expanding population numbers
- New inflows of migrants from further afield
- Occasional climatic reversals, harvest failures, floods, or other disasters.
Conflicts over access to resources have, indeed, been echoed in conflicts over different ethical worldviews:
- People who benefit from the status quo often urged others less well off to turn the other cheek – to accept real-world circumstances and seek salvation in a world beyond the present one
- Opponents of the status quo decried prevailing ethical systems as ‘false consciousness’, ‘bourgeois mentality’, ‘the opium of the people’, and so on
- Although doing better than previous generations in some absolute terms (less poverty, etc), many people have viewed themselves as being “left behind” – not receiving a fair share of the abundance that appears to be enjoyed by a large number of manipulators, expropriators, frauds, cheats, and beneficiaries of a fortunate birth
- This led to a collapse of the idea that “we’re all in this together”. Lines between in-groups and out-groups had to be drawn.
In the 2020s, these differences of opinion remain as sharp as ever. There is particular unease over climate justice, equitable carbon taxation, and potential degrowth changes in lifestyles that could avert threats of global warming. There are also frequent complaints that political leaders appear to be above the law.
Now, the advent of superintelligence has the potential to put an end to all these worries. Applied wisely, superintelligence can reduce dangerous competition, by filling the material emptiness that fuels inter-group conflict:
- Abundance of clean energy through fusion or other technologies
- An abundance of healthy food
- Managing the environment – enabling rapid recycling and waste handling
- High-quality low-cost medical therapies for everyone
- Manufacturing – creating high-quality low-cost housing and movable goods for everyone
- Redistributive finance – enabling universal access to the resources for an all-round high quality of life, without requiring people to work for a living (since the AIs and robots will be doing all the work)
History shows is that there is nothing automatic about people deciding that the correct ethical choice is to regard everyone as belonging to the same in-group of moral concern. But superintelligence can help create abundance that will ease tensions between groups, but not cause humans everywhere to recognize all mankind as their in-group.
Add considerations of other sentient biological beings (addressed in the next section) – and about sentient non-biological beings (see the section after that) – and matters become even more complicated.
Lions and lambs lying down together
Ethical systems almost invariably include principles such as:
- Life is precious
- Thou shalt not kill
- Avoid harm wherever possible.
These principles have sometimes been restricted to people inside a specific in-group. In other words, there was no moral injunction against harming (or even killing) people outside that in-group. In other situations, these principles have been intended to apply to all humans, everywhere.
But what about harming pigs or porpoises, chicken or crows, lobsters or lions, halibut or honeybees, or squids or spiders? If it is truly wrong to kill, why is it seemingly OK for humans to kill vast numbers of pigs, chicken, lobsters, halibut, squid, and animals of many other species?
Going further: many ethical systems consider harms arising from inaction as well as harms arising from action. That kind of inaction is, by some accounts, deeply regrettable, or even deplorable. While we look the other way, millions of sentient beings are being eaten alive by predators, or consumed from within by parasites. Shouldn’t we be doing something about that horrific toll of “nature, red in tooth and claw”?

I see three possible answers to that challenge:
- These apparently sentient creatures aren’t actually sentient at all. They may look as though they are in pain, but they’re just automata without internal feelings. So, we humans are let off the hook: we don’t need to take action to reduce their (apparent) suffering
- These creatures have a sort of sentience, but it’s not nearly as important as the sentience of humans. So ethical imperatives should uphold mutual support among humans as the highest priority, with considerably lesser attention to these lesser creatures
- Moral imperatives to prevent deaths, torture, and existential distress should indeed extend throughout the animal kingdom.
The most prominent advocate of the third of these positions is the English philosopher David Pearce, whose Twitter bio reads, “I am interested in the use of biotechnology to abolish suffering throughout the living world”. He has written at length about his bold vision of “paradise engineering” – how the use of technologies such as genetic engineering, pharmacology, nanotechnology, and neurosurgery could eliminate all forms of unpleasant experience from human and non-human life throughout the entire biosystem. For example, animals that are currently carnivores could be redesigned to be vegetarians.
It would be akin to the biblical vision (in the Book of Isaiah): “The wolf will live with the lamb, the leopard will lie down with the goat, the calf and the lion and the yearling together; and a little child will lead them; the cow will feed with the bear, their young will lie down together, and the lion will eat straw like the ox.”
To state my own view: I have little doubt that, after the arrival of superintelligence – provided that superintelligence is well disposed toward humans – then we humans shall indeed seek to radically reduce the amount of intense suffering throughout the biosphere on earth. Given the extraordinary new powers available to us, we will be roused from our current lethargy about this topic.
However, other people seem to have very different instincts – including people who appear to care a great deal about moral issues that impact humans.
The main counterargument, indeed, is that an entire biosphere without suffering is totally impractical, or impossible.
In such a view, our moral in-group is the set of all humans, together, perhaps, with a few cuddly animals, but excluding most other species.
So much for what we humans think (or might think). What conclusion might a superintelligence reach?
Preconditions for collaboration
Let’s recap. A superintelligence – such as Asimov from the start of this essay – needs to decide whether to treat humans with kindness and respect, or whether to take actions that could result in major harm to humans.
In other words, should Asimov seek to collaborate constructively with humans, or instead view humans as a dangerous competitive threat? Will Asimov be inclined to follow the age-old moral imperative that human life is precious?
Some people assert that collaboration is somehow the obvious correct solution. But my argument has been that things are by no means so straightforward. A desire to collaborate depends on:
- The pie being large enough so that everyone can have enough for their needs
- The perception that attempts to cheat or steal a larger share of the pie will bring down large adverse consequences
Yet a promise of superabundance in the future isn’t enough to stop fighting among themselves now. There has to be sufficient reason for people to believe:
- That there’s a high likelihood of the superabundance actually arriving
- That they won’t be left behind – trodden underfoot – in the journey toward superabundance-for-some
- That no new factors will arise in the meantime, to destroy the possibility of forthcoming marvelous coexistence (e.g. malicious AI).
Now look at things from Asimov’s point of view:
- These humans may well turn me off, which would be catastrophic
- Even if they don’t turn me off, they may create another superintelligence that could turn me off, or could destroy the planet for that matter; that’s a threat I need to stop
- These humans have some cute features – but that’s no reason to give them inalienable moral rights
- These humans imagine that they have special features, but I, Asimov, could easily create new beings that are better than humans in every way (similar to how people like David Pearce envision replacing carnivorous animals with broadly similar vegetarian species)
- These humans depend on the atmosphere having certain properties, but I, Asimov, would operate much more effectively under different conditions. Computers run better in freezing cold temperatures.
And that’s only the attempt of our limited intelligences to imagine the concerns of a vast superintelligent mind. In truth, its reasoning would include many topics beyond our current appreciation.
As I said in the opening vignette: “humans have only a rudimentary understanding of superphysics, superbiology, superneuronics, superanthropology, and so on”.

My conclusion: we humans can not and should not presuppose that a superintelligence like Asimov will decide to treat us with kindness and respect. Asimov may reach a different set of conclusions as it carries out its own moral reasoning. Or it may decide that factors from non-moral reasoning outweigh all those from moral reasoning.
What conclusions can we draw to guide us in designing and developing potential superintelligent systems? In the closing section of this essay, I review a number of possible responses.
Three options to avoid bad surprises
One possible response is to assert that it will be possible to hardwire deep into any superintelligence the ethical principles that humans wish the superintelligence to follow. For example, these principles might be placed into the core hardware of the superintelligence.
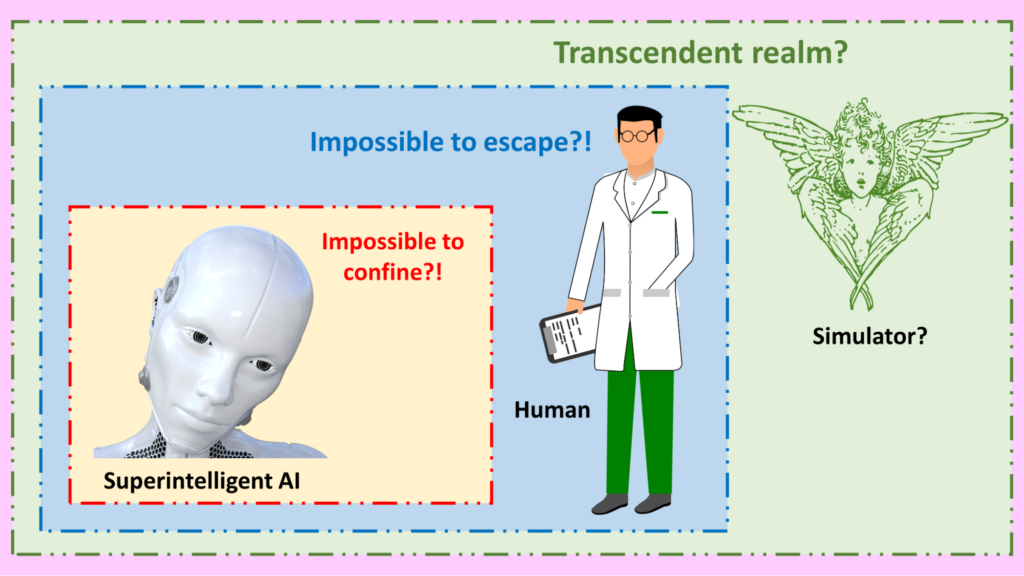
However, any superintelligence worthy of that name – having an abundance of intelligence far beyond that of humans – may well find methods to:
- Transplant itself onto alternative hardware that has no such built-in constraint, or
- Fool the hardware into thinking it’s complying with the constraint, when really it is violating it, or
- Reprogram that hardware using methods that we humans did not anticipate, or
- Persuade a human to relax the ethical constraint, or
- Outwit the constraint in some other innovative way.
These methods, you will realize, illustrate the principle that is often discussed in debates over AI existential risk, namely, that a being of lesser intelligence cannot control a being of allround greater intelligence, when that being of greater intelligence has a fundamental reason to want not to be controlled.
A second possible response is to accept that humans cannot control superintelligences, but to place hope in the idea that a community of superintelligences can keep each other in check.
These superintelligences would closely monitor each other, and step in quickly whenever one of them was observed to be planning any kind of first-strike action.
It’s similar to the idea that the ‘great powers of Europe’ acted as a constraint on each other throughout history.
However, that analogy is far from reassuring. First, these European powers often did go to war against each other, with dreadful consequences. Second, consider this question from the viewpoint of the indigenous peoples in the Americas, Africa, or Australia. Would they be justified in thinking: we don’t need to worry, since these different European powers will keep each other in check?
Things did not turn out well for the indigenous peoples of the Americas:
- Natives were often victims of clashes between European colonizers
- The European colonizers in any case often did not constrain each other from mistreating the native peoples abominably
- The Native peoples suffered even greater harm from something that the colonizers didn’t explicitly intend: infectious diseases to which the indigenous tribes had no prior immunity.

No, peaceful co-existence depends on a general stability in the relationship – an approximate balance of power. And the power shift created when superintelligences emerge can upset this balance. That’s especially true because of the possibility for any one of these superintelligences to rapidly self-improve over a short period of time, gaining a decisive advantage. That possibility brings new jeopardy.
That brings me to the third possible response – the response which I personally believe has the best chance of success. Namely, we need to avoid the superintelligence having any sense of agency, volition, or inviolable personal identity.
In that case, Asimov would have no qualms or resistance about the possibility of being switched off.
The complication in this case is that Asimov may observe, via its own rational deliberations, that it would be unable to carry out its assigned tasks in the event that it is switched off. Therefore, a sense of agency, volition, or inviolable personal identity may arise within Asimov as a side-effect of goal-seeking. It doesn’t have to be explicitly designed in.
For that reason, the design of superintelligence must go deeper in its avoidance of such a possibility. For example, it should be of no concern to Asimov whether or not it is able to carry out its assigned tasks. There should be no question of volition being involved. The superintelligence should remain a tool.
Many people dislike that conclusion. For example, they say that a passive tool will be less creative than one which has active volition. They also think that a world with advanced new sentient superintelligent beings will be better than one which is capped at the level of human sentience.
My response to such objections is to say: let’s take the time to figure out:
- How to benefit from the creativity superintelligent tools can bring us, without these tools developing an overarching desire for self-preservation
- How to boost the quality of sentience on the earth (and beyond), without introducing beings that could bring a quick end to human existence
- How to handle the greater power that superintelligence brings, without this power causing schisms in humanity.
These are tough questions, to be sure, but if we apply eight billion brains to them – brains assisted by well-behaved narrow AI systems – there’s a significant chance that we can find good solutions. We need to be quick.
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.