.png)

.png)


.png)


The transcendent questions that will determine the fate of humanity
The Singularity is nigh
There’s a strong probability that, within a few decades at most, the fate of Earth will be out of human hands.
As the rationality and agency of AIs approach and then dramatically exceed the capabilities of their human progenitors, it will no longer be we humans who are calling the shots.
This striking possibility—this singularity in the long history of human civilization—this decisive disruption in our role as the smartest beings on the planet—should command the rapt attention of everyone who cares about the future.
In some scenarios, the singularity will herald unprecedented flourishing for humanity, with options for humanity to rapidly improve along multiple dimensions of wellbeing. This kind of singularity will feature AIs that aren’t just generally intelligent (AGIs) but that are beneficial general intelligences (BGIs). We can envision humanity being cradled in the palms of a BGI.
But in other scenarios, humans will be dramatically diminished either at the singularity itself or shortly afterward, or even in an utterly chaotic approach to that seismic transition. That kind of AGI could be called a CGI—a catastrophic general intelligence. We can envision humanity being crushed into oblivion, or casually tossed aside, or rent asunder, by the actions of one or more CGIs.

Given these scenarios, two questions cry out for careful analysis:
- What’s the likelihood that, if the development of AI systems around the world remains on its current default trajectory, the resulting AGI will be a BGI rather than a CGI? Is that likelihood acceptably high or dismally low?
- What actions should developers (and the people who fund and oversee their activities) take, to increase the likelihood that a BGI will emerge, rather than a CGI?
The argument against the default trajectory
Many people reject the idea of a CGI as implausible science fiction. They ask: how much harm could powerful AI cause the world?
My answer: enormous harm – enormous harm that is avoidable, with appropriate forethought.
The problem isn’t just AI in isolation. It’s AI in the hands of fallible, naive, over-optimistic humans, who are sometimes driven by horrible internal demons. It’s AI summoned and used, not by the better angels of human nature, but by the darker corners of our psychology.
Although we humans are often wonderful, we sometimes do dreadful things to each other – especially when we have become angry, alienated, or frustrated. Add in spiteful ideologies of resentment and hostility, and things can become even uglier.

Placing technology in the hands of people in their worst moments can lead to horrific outcomes. The more powerful the technology, the more horrific the potential outcomes:
- The carnage of a frenzied knife attack or a mass shooting (where the technology in question ranges from a deadly sharp knife to an automatic rifle)
- The chaos when motor vehicles are deliberately propelled at speed into crowds of innocent pedestrians
- The deaths of everyone on board an airplane, when a depressed air pilot ploughs the craft into a mountainside or deep into an ocean, in a final gesture of defiance to what they see as an unfair, uncaring world
- The destruction of iconic buildings of a perceived “great satan”, when religious fanatics have commandeered jet airliners in service of the mental pathogen that has taken over their minds
- The assassination of political or dynastic rivals, by the mixing of biochemicals that are individually harmless, but which in combination are frightfully lethal
- The mass poisoning of commuters in a city subway, when deadly chemicals are released at the command of a cult leader who fancies himself as the rightful emperor of Japan, and who has beguiled clearly intelligent followers to trust his every word.
How does AI change this pattern of unpleasant possibilities? How is AI a greater threat than earlier technologies? In six ways:
- As AI-fuelled automation displaces more people from their work (often to their surprise and shock), it predisposes more people to become bitter and resentful
- AI is utilised by merchants of the outrage industrial complex, to convince large numbers of people that their personal circumstance is more appalling than they had previously imagined, that a contemptible group of people over there are responsible for this dismal turn of events, and that the appropriate response is to utterly defeat those deplorables
- Once people are set on a path to obtain revenge, personal recognition, or just plain pandemonium, AIs can make it much easier for them to access and deploy weapons of mass intimidation and mass destruction
- Due to the opaque, inscrutable nature of many AI systems, the actual result of an intended outrage may be considerably worse even than what the perpetrator had in mind; this is similar to how malware sometimes causes much more turmoil than the originator of that malware intended
- An AI with sufficient commitment to the goals it has been given will use all its intelligence to avoid being switched off or redirected; this multiplies the possibility that an intended local outrage might spiral into an actual global catastrophe
- An attack powered by fast-evolving AI can strike unexpectedly at core aspects of the infrastructure of human civilization – our shared biology, our financial systems, our information networks, or our hair-trigger weaponry – exploiting any of the numerous fragilities in these systems.
And it’s not just missteps from angry, alienated, frustrated people, that we have to worry about. We also need to beware potential cascades of trouble triggered by the careless actions of people who are well-intentioned, but naive, over-optimistic, or simply reckless, in how they use AI.
The more powerful the AI, the greater the dangers.
Finally, the unpredictable nature of emergent intelligence carries with it another fearsome possibility. Namely, a general intelligence with alien thinking modes far beyond our own understanding, might decide to adopt an alien set of ethics, in which the wellbeing of eight billion humans merits only a miniscule consideration.
That’s the argument against simply following a default path of “generate more intelligence, and trust that the outcome is likely to be beneficial for humanity”. It’s an argument that should make everyone pause for thought.
Probabilities and absolutes
When they are asked about the kind of disaster scenarios that I mentioned in the previous section, people who are in a hurry to create AGI typically have one of two different responses. Either they adopt a probabilistic stance, saying they are willing to take their chances, or they hunker down into an absolutist position, denying that these scenarios have any credibility.
People who accept that there are credible risks of AGI-induced catastrophe often reason as follows:
- Things could instead go wonderfully well (let’s cross our fingers!)
- If we fail to build AGI, we will face other existential risks, both on a civilisational level, and at a personal level (that is, aging and death)
- So, let’s roll the AGI dice, and hope for a favourable outcome.

But this reasoning is deeply problematic, on two grounds.
First, what on earth gives an AGI developer the right to undertake this risk, on behalf of the entire human population, many of whom may well reject that existential gamble, assuming they knew about it? It’s not just their own lives that are at risk. It’s the lives of billions elsewhere on the planet.
Second, there are more than two choices to consider! It’s not down to a straight binary choice between “AGI” and “no AI at all”. That’s a pathetically shallow way to assess the situation. Instead, there are two more options to consider. As I’ll explain shortly, these can be called AGI+ and AGI–. In principle, either of these options could deliver the desired profoundly positive outcomes, but at a much lower risk of catastrophic misstep. Either could be better bets to create BGI instead of CGI, rather than sticking with the default AGI trajectory.
That’s why I have, in a way, greater respect for developers who try to argue instead that there are no credible risks of global catastrophe from AGI. These developers involve no tortuous moral acrobatics. Instead, they speak in absolutes. For example, they may say, or think, “the universe will provide”. They have a simple (but unsound) induction in mind: humans have survived trials and tribulations in the past, so are bound to survive any new trials and tribulations in the future.
My response: the universe did not provide, for all the unfortunate victims of knife attacks, mass shootings, car crashes, airplane disasters, chemical attacks, or other terrorist outrages, which I mentioned earlier. The universe did not provide, for those slaughtered in ongoing tragedies in Gaza, Ukraine, Sudan, and elsewhere. Indeed, as Homo sapiens spread around the planet, numerous large animals were driven to extinction due to human activities. Likewise, the universe did not provide for the other hominid species who used to share the earth with us.
No, I stand behind my case, made above: the default path is laden with danger. The dangers arise from the existence of extraordinarily powerful AI that operates beyond human understanding, combined with even just a few elements of:
- Humans with malign intent
- Humans with naive understanding
- Humans hijacked by belligerent emotions
- Economic systems with incentives to disregard negative externalities
- Political systems with incentives to grab power and hold onto it
- Philosophies that justify egocentrism or tribalism
- Numerous vulnerabilities in human civilisational infrastructure.
Given these risks, we should try harder to find solutions. Real solutions, rather than just a proclamation of faith.
Indeed, given these risks, AGI developers should beware any preoccupation with merely technical questions – such as the extent to which various deep neural networks are included and wired together in their systems, or whether the venerable back-propagation algorithm should be replaced by something closer to what seems to happen in the human brain. These are important questions, but they are transcended by the questions I now wish to address.
Default AGI, or AGI+, or AGI–?
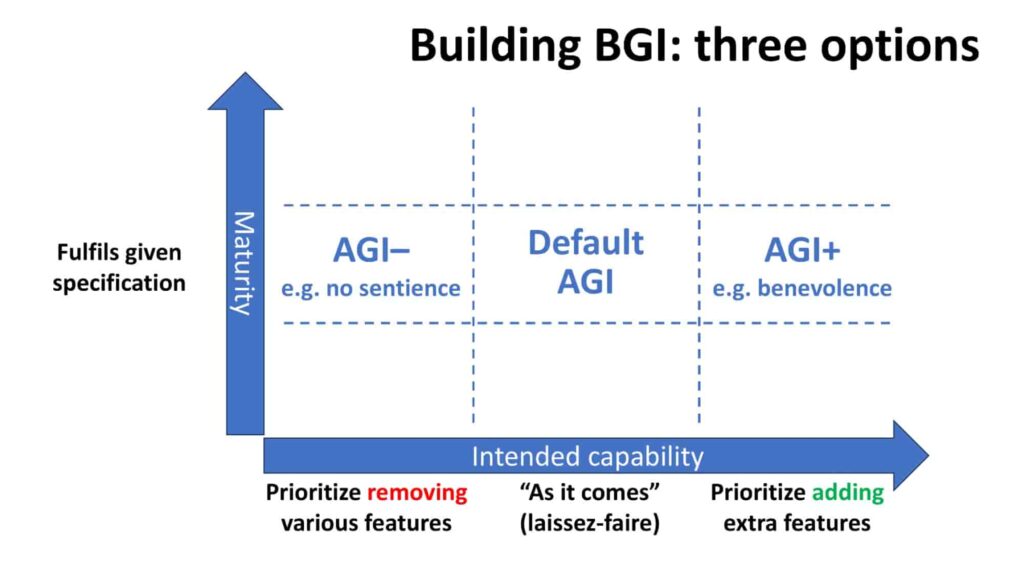
Consider three different conceptions of the intended capabilities of a finished AGI
- Default AGI: It is sufficient just to focus on building a general intelligence (which is, after all, a formidable technical challenge in its own right), and trust that the outcome will likely be beneficial to humanity
- AGI+: It is vital to prioritize adding extra features into the specification – features such as explicit compassion, explicit benevolence, explicit empathetic consciousness, or explicit wisdom
- AGI–: Rather than prioritizing adding extra features, it is more important to prioritize removing specific features that might otherwise arise in the AGI – features such as agency, autonomy, will-to-live, or sentience.
Here are some examples of attempts to design or build AGI+:
- Anthropic embeds a “Constitutional Layer” in their AI systems, incorporating a set of fundamental principles (akin to a political constitution) that are intended to constrain the AI to behave in alignment with human values and ethics
- With a broadly similar vision, Craig Mundie, former chief research and strategy officer at Microsoft, has proposed the idea of an “adjudication layer” that monitors advanced AI systems to ensure ethical compliance, much like a judiciary or a regulatory body would oversee human actions in a society
- AI researcher Nell Watson champions the collection of examples of desired ethical behaviour into the EthicsNet database (akin to the ImageNet database that trained AIs how to recognise images), which can then guide the adoption of benevolent behaviour by advanced AIs
- Recent new startup Conscium is exploring the possibility that an AI with a self-aware compassionate consciousness will prioritise the wellbeing of humans, on account of recognising and valuing the similar consciousness that we possess
- SingularityNET advocates the development of clear and robust ethical principles that prioritize human flourishing, by focusing on safety, fairness, transparency, and the avoidance of harm – with the interactions within multi-agent cooperative systems ensuring adherence to these principles.
All of these initiatives acknowledge that there is more to do than simply increase the raw intelligence of the AIs they envision. In each case, they maintain that significant effort must also be applied on matters of ethical framework, mutual monitoring, compassion, or wisdom.
Likewise, here are some examples of attempts to design or build AGI–:
- Max Tegmark of the Future of Life Institute urges the development of what he calls “Tool AI”, where the AI has great intelligence, but no independent autonomy or agency; Tool AI would serve as a tool for human decision-making and problem-solving, without possessing any goals or motivations of its own
- Yoshua Bengio, the world’s most highly cited computer science researcher, has a similar concept which he calls “Scientist AI”: an assistant and partner in the scientific process, that can propose hypotheses, design experiments, analyse data, and contribute new insights, but without taking any initiative by itself, and always in a way that complements and enhances human expertise
- Anthony Aguirre, also of the Future of Life Institute, proposes to avoid the creation of any systems that manifest all three of the characteristics that he labels as ‘A’ (Autonomy), ‘G’ (Generalisation ability), and ‘I’ (deep task Intelligence), when being powered with computation exceeding an agreed threshold; in contrast, combinations of any two of these three characteristics would be relatively safe, and would be encouraged.
In principle, then, there are two broad approaches to explore, AGI+ and AGI–, for people who are concerned about the risks of the emergence of CGI. And there is also the Default AGI path for people who are determined to ignore the seriousness of the possibility of CGIs.
At this point, however, we need to be aware of three further complications:
- The special risks from immature (unfinished) advanced AIs
- The special risks from self-improved advanced AIs
- The need to coordinate the approaches adopted by different AI development groups around the world.
They’re all reasons why building AGI requires a lot more than technical decisions – and why the creation of AGI should not be left in the hands of technologists.
Let’s take these complications one at a time.
Immaturity, maturity, and self-improvement
The first complication is that, for any complex software, a perfect solution never appears from scratch. Rather, any mature solution is inevitably preceded by an immature, buggy version. That’s why public software releases are preceded by test phases, in order to observe and fix incorrect behaviour. Test phases usually catch a significant number of defects, but rarely catch them all.
Therefore, an intended eventual release of “Default AGI” is almost certain to be preceded by a release of what can be called “Immature AGI”. And intended eventual releases of AGI+ and AGI– are almost certain to be preceded by releases of “Immature AGI+” and “Immature AGI–”:
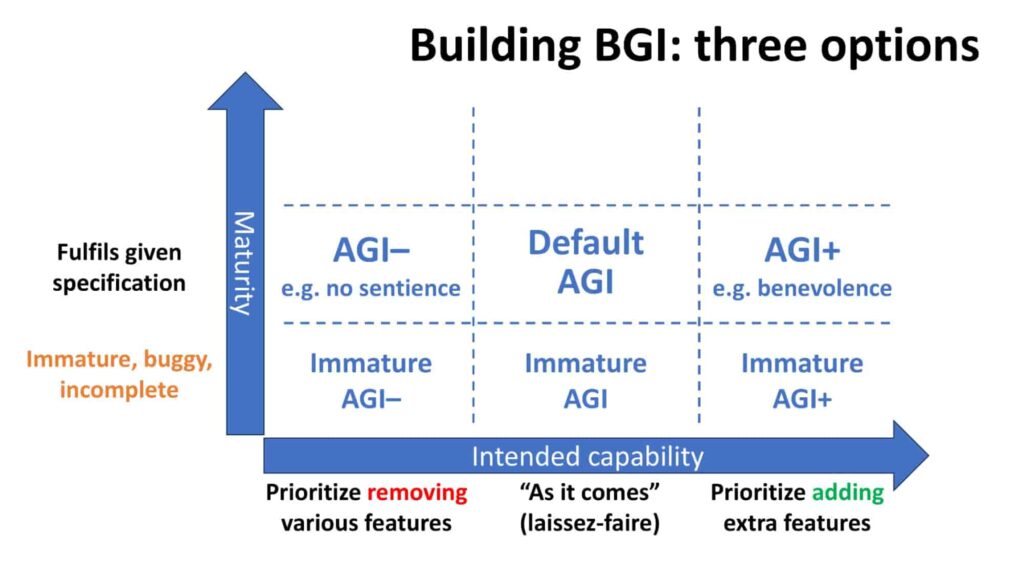
While AGI poses risks, for all the reasons previously discussed, immature AGI arguably poses even more risks.
Here are some examples of bugs in an immature release that could prove disastrous:
- Encountering situations not covered in the training set, but not realising the novelty of these situations
- Interacting with other AIs whose actions are unpredictable and unforeseen
- Miscalculating the effect of some actions on the earth’s climate (in an attempt, for example, to manage a geoengineering project)
- Miscalculating the safety of a nuclear power plant with a creative new design
- Miscalculating the safety of a provocative gesture in a tense military stand-off (especially when pre-emptive first strikes may be a theoretical possibility).
To be clear, the complications of an immature software release apply to all three columns of the chart above.
Thus, an attempt to build an AGI+ that includes explicit training on what is believed to be the world’s best examples of ethical behaviour could nevertheless result in a miscalculation, with the immature AGI+ taking actions horribly at odds with human preferences. (That’s similar to how image recognition software sometimes makes spectacular mistakes that are incomprehensible to casual human observers.)
Again, an attempt to build an AGI– that avoids any possibility of developing sentience (with all the resulting complications) may incorrectly leave open the possibility of dangerous sentience arising in some unexpected way.
Therefore, at the lower levels of all three columns, dragons abound.
But suppose that, nevertheless, the immature phase of the AGI (of whichever sort) passes without major incident. Perhaps the developers have been particularly skilful. Perhaps the monitoring for adverse behaviour has been particularly effective. Or perhaps the developers have simply been lucky. Therefore, the software reaches the intended state.
At that point, a second major complication arises:
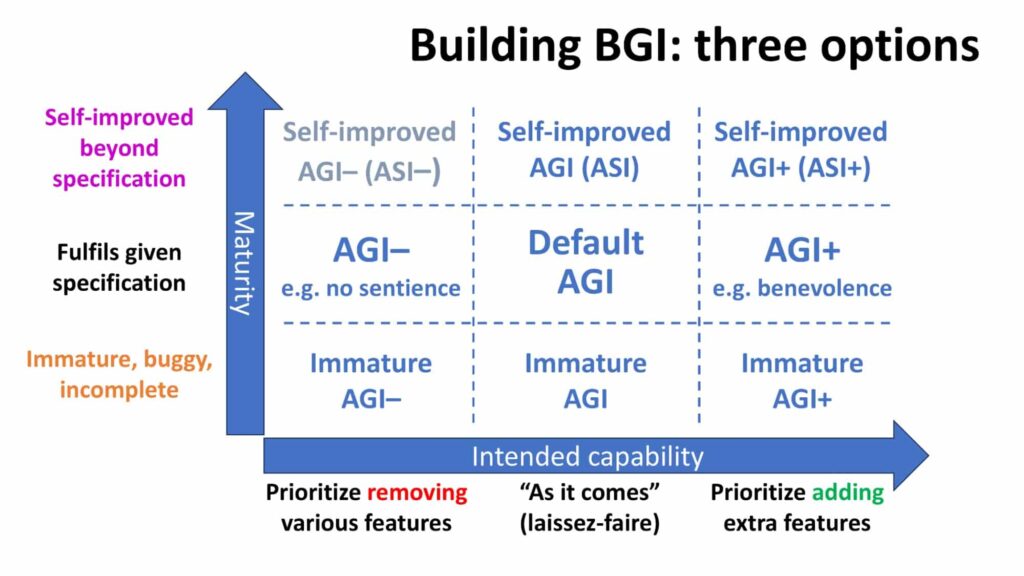
Just as issues arise before an AGI reaches its intended capability, there are also issues after that point. That’s if the AGI uses its own intelligence and agency to self-improve in a fast take-off mode – recursively improving its own algorithms, comms architecture, power efficiency, or whatever.
Thus, a Default AGI might self-improve to a Default ASI (Artificial Superintelligence), whose intelligence exceeds not only that of any individual human, but all of humanity added together. Now imagine a group of humans driven by malice, with an unconstrained ASI at their disposal. (Shudder!)
Likewise, an AGI+, with an understanding of benevolence designed to match that of humanity, might self-improve to an ASI+, with a very different understanding of benevolence. In that new understanding, human wellbeing may be an irrelevance, or a hindrance.
In principle, an AGI– might, similarly, self-improve to an ASI–, although if the AGI– is correctly programmed, it should have no desire to self-improve. (That’s why the corresponding box in the image above is shown in the colour grey.)
To recap: the decision between AGI–, Default AGI, and AGI+, needs to take into consideration not only the likelihood of the mature AGI treating humanity with respect and benevolence; it must also consider:
- The behaviour of the AGI before attaining the intended state of maturity
- The behaviour of the AGI after attaining the intended state of maturity.
But there’s one more major complication to add into the mix. Of the three, it’s the hardest of all. To solve it will require the very best of human skills and resources – a singular effort, to ensure a singularly beneficial outcome, rather than one that is singularly catastrophic.
The collapse of cooperation is nigh
Imagine a team of AGI developers, that has weighed up all the considerations above, and explored many technical options.
Imagine that they have decided that a particular version of AGI+ is the best way to go forward. Or, a particular version of AGI–. (In each case, as we’ll see, the same dilemma arises.)
Imagine, also, that these developers have decided, as well, that most other approaches to building AGI are likely to create a catastrophically dangerous CGI rather than a wonderfully benevolent BGI.
These developers now have two challenges:
- To put their own ideas into practice, building what they believe to be a BGI (whilst constantly checking that their ideas are turning out well, without nasty implementation surprises)
- To prevent other development teams from putting their ideas into practice first, resulting, quite likely, in a CGI.
To my mind, the worst outcome would be for these developers to ignore what other teams are doing, and instead to retreat into their own mindspace. That “go it alone” mentality would fit a pattern that has been growing more deadly serious in recent years: the collapse of effective global cooperation.
I don’t mean the collapse of apparent global cooperation, since lots of discussions and conferences and summits continue to exist, with people applauding the fine-sounding words in each other’s speeches. “Justice and fairness, yeah yeah yeah!” “Transparency and accountability, yeah yeah yeah!” “Apple pie and blockchain, yeah yeah yeah!” “Intergenerational intersectionality, yeah yeah yeah!”
I mean the collapse of effective global cooperation, regarding the hard choices about preventing the creation of CGI whilst others are following sensible pathways with a reasonable chance of creating BGI.
It’s as if some parts of the general structure of the United Nations are still in place, but the organisation is crumbling.

But it’s not just the UN that is bungling the task of effective coordination of the global approach to AGI. All other would-be coordination bodies are struggling with the same set of issues:
- It’s much easier to signal virtue than to genuinely act virtuously.
- Too many of the bureaucrats who run these bodies are completely out of their depth when it comes to understanding the existential opportunities and risks of AGI.
- Seeing no prospect of meaningful coordination, many of the big tech companies invited to participate do so in a way that obfuscates the real issues while maintaining their public image as ‘trying their best to do good.
- The process is in many way undermined by many of the ethically-abominable “reckless accelerationists” who, as mentioned earlier, are willing to gamble that AGI will turn into BGI (and they will take a brief perverted pleasure if CGI arrives instead), and they don’t want the public as a whole to be in any position to block their absurd civilisational Russian roulette.
How to address this dilemma is arguably the question that should transcend all others, regarding the future of humanity.
The argument against another default trajectory
Earlier, I gave an argument against the default trajectory for how AGI is being built, that is, the laissez-faire path without any significant effort to ensure that the AGI turns out to be a BGI rather than a CGI.
I now offer an argument against what is the default trajectory for the future of cooperation between different development teams each trying to build AGI. This time, the default trajectory is that cooperation is only superficial, whilst behind the scenes, each group does its best to reach AGI first.
This is the trajectory of a global race. It has its own kind of logic. If you think your AGI will be beneficial, but that the AGIs created by other groups may turn out catastrophic – and if you think there is no easy way to change the minds of these other groups – then you had better endeavour to reach the finishing line first.
But since the race is so intense – with competitors from around the world, using models that have been released as open source and then recompiled with new data and new algorithms – this isn’t a race that can be won by exercising a huge amount of care and attention on safety matters. As each team redoubles its efforts not to be left behind in the race, all kinds of corners will be cut. And what they intended to release as a BGI is almost certainly going to have very nasty unforeseen bugs.
This will not be a race to glory—but likely a race to oblivion.

But what is the alternative? If there is no credible route to meaningful global coordination, perhaps racing fast is the most sensible approach after all.
Happily, there are two credible routes to meaningful global coordination. I mean, each of these routes is partially credible. The real magic happens when these routes are combined.
Decentralised and centralised cooperation
Intelligence is frequently cited as humanity’s defining superpower. To the extent that we act with intelligence, we prosper. To the extent that our intelligence will be overtaken by more powerful artificial thinking systems, our future is no longer in our hands.
But a better analysis is that humanity’s superpower is collaboration. We thrive when we dovetail each other’s talents, communicate new insights, inspire loyalty, and transcend narrow egotism.
As noted earlier, there are oppressive real-world obstacles in the path of any attempts at meaningful collaboration to build BGI rather than CGI. But the solutions to such obstacles are, in principle, already well known. They involve both decentralised and centralised mechanisms:
- The decentralised sharing of insights about best practices, with reputation markets tracking conformance to these best practices, and where there are meaningful consequences for loss of reputation
- The centralised exercise of power by states – including sanctions and, where needed, forceful interventions.
For the decentralised sharing of insights, here is what I presently consider to be the most important insights – the nine key AI security recommendations whose truths and possibilities need to be shouted from the rooftops, whispered into quiet conversations, mixed into dramatic productions, highlighted in clever memes, and featured in compelling videos:

- It’s in the mutual self-interest of every country to constrain the development and deployment of what could become catastrophically dangerous AGI; that is, there’s no point in winning what would be a reckless suicide race to create AGI before anyone else
- The major economic and humanitarian benefits that people hope could be delivered by AGI (including solutions to other existential risks), can in fact be delivered much more reliably by AGI+ and/or AGI– (the choice between these remains to be fully debated; likewise the choice of which type of AGI+ and/or AGI–)
- A number of attractive ideas already exist regarding potential policy measures (regulations and incentives) which can be adopted, around the world, to prevent the development and deployment of what could become CGI – for example, measures to control the spread and use of vast computing resources, or to disallow AIs that use deception to advance their goals
- A number of good ideas also exist regarding options for monitoring and auditing which can also be adopted, around the world, to ensure the strict application of the agreed policy measures – and to prevent malign action by groups or individuals that have, so far, failed to sign up to these policies, or who wish to cheat them
- All of the above can be achieved without any detrimental loss of individual sovereignty: the leaders of countries can remain masters within their own realms, as they desire, provided that the above basic AI security framework is adopted and maintained
- All of the above can be achieved in a way that supports evolutionary changes in the AI security framework as more insight is obtained; in other words, this system can (and must) be agile rather than static
- Even though the above security framework is yet to be fully developed and agreed, there are plenty of ideas for how it can be rapidly developed, so long as that project is given sufficient resources, and the best brains from multiple disciplines are encouraged to give it their full attention
- Ring-fencing sufficient resources to further develop this AI security framework, and associated reputational ratings systems, should be a central part of every budget
- Reputational ratings can be assigned, based on the above principles, to individuals, organisations, corporations, and countries; entities with poor AI security ratings should be shunned; other entities that fail to take account of AI security ratings when picking suppliers, customers, or partners, should in turn be shunned too; conversely, entities with high ratings should be embraced and celebrated.
An honest, objective assessment of conformance to the above principles should become more significant, in determining reputation, than, for example, wealth, number of online followers, or share price.
Emphatically, the reputation score must be based on actions, not words—on concrete, meaningful steps rather than behind-the-scenes fiddling, and on true virtue rather than virtue-signaling. Accordingly, deep support should be provided for any whistleblowers who observe and report on any cheating or other subterfuge.
I say again: the above framework has many provisional elements. It needs to evolve, not under the dictation of central rulers, but as a result of a grand open conversation, in which ideas rise to the surface if they make good sense, rather than being shouted with the loudest voice.
That is, decentralised mechanisms have a vital role to play in spreading and embedding the above understanding. But centralised mechanisms have a vital role too. That’s the final topic of this article. That’s what can make all the difference between a CGI future and a BGI future.
A credible route to BGI without CGIs
Societies can fail in two ways: too little centralised power, and too much centralised power.
In the former case, societies can end up ripped apart by warring tribes, powerful crime families, raiding gangs from neighbouring territories, corporations that act with impunity, and religious ideologues who stamp their contentious visions of “the pure and holy” on unwilling believers and unbelievers alike.
But in the latter case, a state with unchecked power diminishes the rights of citizens, dispenses with the fair rule of law, imprisons potential political opponents, and subverts economic flows for the enrichment of the leadership cadre.
The healthiest societies, therefore, possess both a strong state and a strong society. That’s one meaning of the marvellous principle of the separation of powers. The state is empowered to act, decisively if needed, against any individual cancers that would threaten the health of the community. But the state is constrained by independent, well-organised judiciary, media, academia, credible opposition parties, and other institutions of civil society.
It should be the same with the governance of potential rogue or naive AGI developers around the world. Via processes of decentralised deliberations, agreement should be reached on which limits are vital to be observed. In some cases, these limits may be subject to local modification, within customisation frameworks agreed globally. But there should be clear acknowledgement that some ways of developing or deploying advanced AIs need to be prevented.
To start with, these agreements might be relatively small in scope, such as “don’t place the launch of nuclear weapons under AI control”. But over time, as confidence builds, the agreements will surely grow.
However, for such agreements to be meaningful, there needs to be a reliable enforcement mechanism. That’s where the state needs to act.
Within entire countries that sign up to this AI security framework, enforcement is relatively straightforward. The same mechanisms that enforce other laws can be brought to bear against any rogue or naive would-be AGI developers.
The challenging part is when countries fail to sign up to this framework, or do so deceitfully, that is, with no intention of keeping their promises. In such a case, it will fall to other countries to ensure conformance, via, in the first place, measures of economic sanction.
To make this work, all that’s necessary is that a sufficient number of powerful countries sign up to this agreement. For example, if the G7 do so, along with countries that are “bubbling under” G7 admission (like Australia and South Korea), along with China and India, that may be sufficient. Happily, there are many AI experts in all these countries who are broadly sympathetic to the kinds of principles I have spelt out above.
As for the likes of Russia and North Korea, they will have to weigh up the arguments. They should understand – like all the other countries – that respecting such agreements is in their own self-interest. To help them reach such an understanding, pressure from China, the USA, and the rest of the world should make a difference.
As I said, this won’t be easy. It will challenge humanity to use its greatest strength in a more profound way than ever before—namely, our ability to collaborate despite numerous differences. But it shouldn’t be a surprise that the unprecedented challenge of AGI technology will require an unprecedented calibre of human collaboration.
The surprise is that so many people prefer to deny this powerful truth. Clearly, there’s a lot of work to be done:
- To free people from the small-minded ideologies that stifle their thinking
- To give them a sufficiently credible hope to be able to break free from their former conditioning.
Humanity actually did make a decent start in this direction at the Global AI Safety Summits in the UK (November 2023) and South Korea (May 2024). Alas, the next summit in that series, in Paris (February 2025) was overtaken by political correctness, by administrivia, by virtue signalling, and, most of all, by people with a woefully impoverished understanding of the existential opportunities and risks of AGI. Evidently, the task of raising true awareness needs to be energised as never before.
Concretely, that means mobilising more skills to spread a deep understanding of the nine key AI security recommendations – as well as all the other ideas in this article that underpin these insights.
In this task, and indeed all the other tasks I’ve described in this article, well-behaved, well-understood AI can be of great assistance to us. That’s if we are sufficiently astute!
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.