



.png)

.png)


.png)

The Blue Wheel Threatening the Valley: How Deepseek Is Reshaping the AI Landscape
Mar. 13, 2025. 10 mins. read.
 84 Interactions
84 Interactions
What happens when AI trains itself? DeepSeek-R1 defies convention, mastering complex reasoning through self-evolution. Here’s why it could reshape the future of large language models.
Introduction
In the rapidly evolving world of artificial intelligence, large language models (LLMs) are reaching new heights of capability. DeepSeek has emerged as a bold challenger, leveraging a novel training paradigm that departs from traditional supervised fine-tuning. At the heart of this breakthrough is DeepSeek-R1, a model whose reasoning capabilities have been honed through an extensive reinforcement learning (RL) process. This model not only demonstrates advanced reasoning in domains such as mathematics, coding, and logic but also reveals an intriguing self-evolution process that allows it to refine its chain-of-thought (CoT) reasoning without any preliminary supervised data.
In this article, we will highlight the innovative methods employed by DeepSeek-AI to develop DeepSeek-R1, explore its impressive performance across a range of benchmarks, and discuss how these techniques may fundamentally reshape the AI landscape by challenging conventional training methodologies.
A Bold Departure: Reinforcement Learning as the Core Training Paradigm
Pure Reinforcement Learning: The Genesis of DeepSeek-R1-Zero
DeepSeek’s pioneering approach began with DeepSeek-R1-Zero, a model trained exclusively via reinforcement learning without any initial supervised fine-tuning (SFT). In traditional LLM training, SFT has been considered a necessary first step to provide a stable starting point. However, DeepSeek-R1-Zero defies this norm by letting the model explore and develop reasoning capabilities autonomously. By engaging with a carefully structured RL environment, the model naturally evolves to generate long chains of thought and exhibits behaviors such as self-verification and reflection.
The training process utilizes Group Relative Policy Optimization (GRPO) – a cost-effective RL algorithm that eliminates the need for a large critic network by leveraging group-level reward signals. This method guides the model to optimize its reasoning process directly by sampling multiple responses for each query and adjusting its internal policies based on a combination of accuracy and formatting rewards.
The Self-Evolution Process and the “Aha Moment”
One of the most compelling aspects of DeepSeek-R1-Zero is its self-evolution process. As RL training progresses, the model not only improves its overall performance on complex reasoning tasks, but it also begins to exhibit emergent behaviors. For instance, it learns to extend its “thinking time” – the period during which it generates intermediate reasoning tokens – which in turn allows it to tackle more challenging problems. Detailed analysis during training revealed a consistent improvement in performance on benchmarks like AIME 2024, where the pass@1 score rose dramatically from 15.6% to 71.0%. With majority voting applied, the score further increased to 86.7%, matching the performance of established models such as OpenAI’s o1-0912.
This progression led to what the researchers describe as an “aha moment” – a phase where the model began to allocate additional reasoning time and re-evaluate its initial approaches. This spontaneous emergence of reflective behavior underscores the potential of RL to unlock sophisticated problem-solving strategies without explicit supervision.
Overcoming Early Challenges: The Transition from DeepSeek-R1-Zero to DeepSeek-R1
Despite the remarkable achievements of DeepSeek-R1-Zero, its initial outputs were marred by issues such as poor readability and language mixing. These shortcomings prompted the development of DeepSeek-R1 – an enhanced version that incorporates a small set of carefully curated cold-start data. By fine-tuning the base model on thousands of high-quality, long-chain-of-thought examples before continuing with reinforcement learning, DeepSeek-R1 was able to overcome these limitations.
The cold-start strategy provided a more stable initial state, improving the model’s ability to produce coherent and well-structured reasoning processes. Following this, the model underwent additional RL fine-tuning focused on maintaining language consistency and enhancing task-specific reasoning. During this stage, a language consistency reward was introduced to ensure that the model adhered to the target language, thereby minimizing undesirable language mixing while still preserving its deep reasoning abilities.
Distilling the Essence: Empowering Smaller Models with DeepSeek-R1’s Reasoning Capabilities
The Power of Distillation
One of the transformative aspects of DeepSeek-R1 is that its advanced reasoning patterns can be distilled into much smaller dense models. This process involves using the outputs of DeepSeek-R1 as a teacher to generate a large dataset—around 800,000 training samples—which is then used to fine-tune smaller models based on open-source architectures like Qwen and Llama.
The distillation process is critical because it allows the impressive reasoning capabilities developed in a massive MoE model to be transferred to smaller models with far fewer parameters. For example, DeepSeek-R1-Distill-Qwen-7B and DeepSeek-R1-Distill-Qwen-32B not only exhibit strong performance on reasoning benchmarks such as AIME 2024 and MATH-500 but also surpass many existing models in efficiency. This approach democratizes access to advanced reasoning capabilities by reducing computational overhead and enabling researchers to deploy powerful models on less resource-intensive platforms.
Comparative Performance and Efficiency
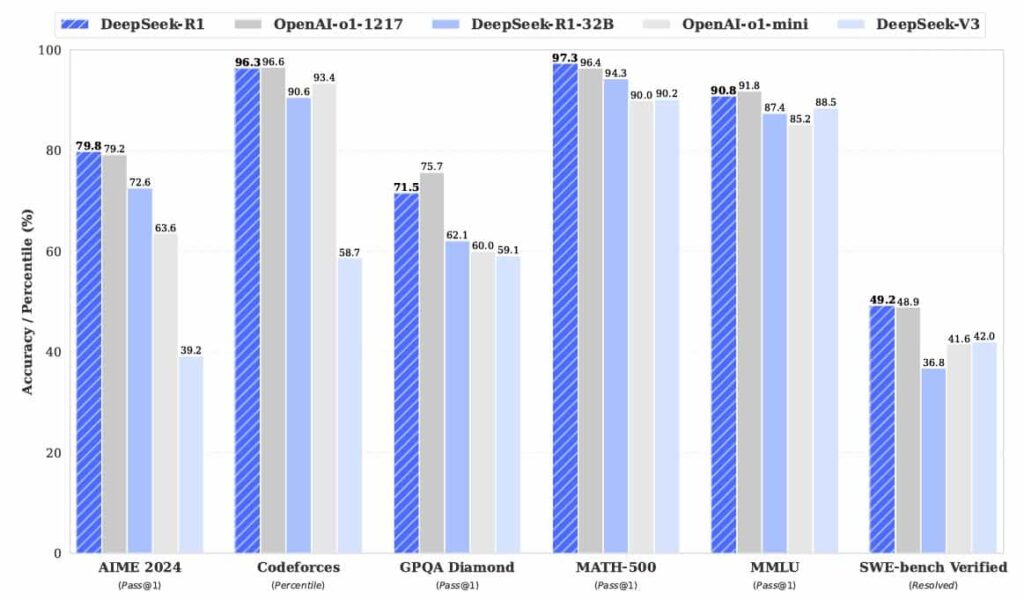
The evaluation results speak for themselves. DeepSeek-R1, when measured on a variety of benchmarks ranging from math and coding to knowledge and language tasks, consistently demonstrates competitive or superior performance compared to both dense and other MoE-based models. On mathematics-oriented benchmarks like MATH-500, DeepSeek-R1 achieves scores in the mid-to-high 90s, rivaling the best models in the field. Similarly, in reasoning tasks such as AIME 2024, the model not only reaches high pass@1 scores but also shows robust performance in real-world coding competitions like Codeforces.
Moreover, the distilled models maintain a remarkable balance between performance and efficiency. With a significantly reduced number of trainable parameters, these smaller models deliver results that are on par with larger, more resource-intensive models, thereby validating the effectiveness of the distillation strategy and offering a pathway to scalable, high-performance AI systems.

Experimentation and Benchmarking: A Comprehensive Evaluation
Pre-Training Evaluations
The DeepSeek-R1 series underwent extensive evaluation on multiple reasoning-related benchmarks. Pre-training results show that the model achieves exceptional performance on a range of tasks:
- On AIME 2024, DeepSeek-R1 scores 79.8% (pass@1), which is on par with or even exceeds that of comparable models from OpenAI.
- On the MATH-500 benchmark, the model achieves a score of 97.3%, underscoring its prowess in mathematical reasoning.
- In coding tasks, DeepSeek-R1 demonstrates superior capability by achieving an elite performance in Codeforces competitions, highlighting its potential application in software engineering and algorithmic problem-solving.
- Knowledge-based benchmarks, such as MMLU and GPQA Diamond, further confirm the model’s robust performance across diverse domains, with scores that position it as one of the top-performing open-source models in its class.
Post-Training and Distilled Model Evaluations
Following supervised fine-tuning and reinforcement learning from human feedback (RLHF), DeepSeek-R1’s performance was further elevated. Post-training evaluations not only reaffirm its capabilities in reasoning and language understanding but also demonstrate its improved alignment with human preferences. The use of diverse reward signals during RLHF helped refine both the quality and the readability of the model’s output, making it more useful in real-world applications.
Distilled models, generated through the rigorous process outlined above, have been evaluated across the same suite of benchmarks. Remarkably, the distilled 7B and 32B models achieve performance metrics that are competitive with much larger models, validating the effectiveness of the distillation strategy. This opens up new opportunities for deploying high-performance reasoning models in environments where computational resources are limited.
Long-Context Capabilities
A distinguishing feature of DeepSeek-R1 is its ability to handle long contexts—up to 256,000 tokens. This capability is crucial for tasks that require processing extensive documents, such as legal and financial analysis, or even multi-turn dialogue in conversational agents. Evaluations on long-context benchmarks such as RULER and LV-Eval demonstrate that DeepSeek-R1 maintains a high level of performance across various context lengths, outperforming many dense models, especially in terms of maintaining coherence and stability in long-form reasoning.
Discussion: Implications and Future Directions
Shifting Paradigms in AI Training
DeepSeek’s innovative use of pure reinforcement learning to drive reasoning capabilities represents a paradigm shift in AI development. By removing the dependency on supervised fine-tuning, the DeepSeek-R1 approach illustrates that LLMs can evolve robust reasoning skills through self-generated exploration. This not only reduces the overhead of collecting massive supervised datasets but also opens the door to novel self-improvement techniques that could be further leveraged in the quest for Artificial General Intelligence (AGI).
The Role of Cold-Start Data and RLHF
The incorporation of cold-start data in DeepSeek-R1 highlights the importance of a stable and human-friendly initial state for reinforcement learning. This method mitigates early training instability and promotes the generation of clear, coherent chains of thought. Furthermore, the application of reinforcement learning from human feedback ensures that the model’s reasoning aligns with human values and expectations—a crucial factor as AI becomes increasingly integrated into everyday applications.
Distillation as a Scalable Strategy
The successful distillation of DeepSeek-R1’s reasoning capabilities into smaller dense models underscores the scalability of this approach. This method not only makes advanced reasoning accessible to researchers with limited computational resources but also paves the way for further innovations in model architecture. Future research could explore integrating reinforcement learning directly into these smaller models or combining bias fine-tuning with distillation to further enhance performance.
Addressing Current Limitations
Despite its impressive performance, DeepSeek-R1 faces several challenges. Notably, issues such as language mixing and sensitivity to prompt formulations remain areas for further investigation. The research suggests that few-shot prompting may degrade performance, indicating that zero-shot settings might be more effective for consistent results. Future work will focus on enhancing language consistency across diverse languages and refining the prompt-engineering process to ensure the model can handle a wide range of inputs without compromising its reasoning integrity.
Broader Implications for AI and Society
The advancements demonstrated by DeepSeek-R1 have far-reaching implications beyond academic benchmarks. By enabling more efficient and powerful reasoning in AI models, DeepSeek opens up new avenues for practical applications in fields such as education, software engineering, scientific research, and even healthcare. As AI systems become better at reasoning, they can assist humans in making complex decisions, solving intricate problems, and potentially unlocking new areas of discovery.
Conclusion
DeepSeek-R1 marks a significant milestone in the evolution of large language models, showcasing the power of pure reinforcement learning combined with a carefully designed cold-start strategy and an effective distillation process. Through its innovative training pipeline, DeepSeek-R1 not only achieves exceptional performance on reasoning benchmarks but also offers a blueprint for future advancements in AI. Its ability to autonomously develop and refine sophisticated reasoning capabilities, coupled with the successful transfer of these skills to smaller models, represents a promising step toward more adaptable, efficient, and powerful AI systems.
The work behind DeepSeek-R1 challenges conventional training paradigms and provides new insights into how reasoning can be incentivized purely through reinforcement learning. As research continues to address the current limitations—such as language mixing and prompt sensitivity—the potential for these models to revolutionize a wide range of applications becomes increasingly evident. Ultimately, DeepSeek-R1 is not just a new AI model; it is a transformative approach that redefines how machines learn to reason, paving the way for the next generation of intelligent systems.
Reference
Chen, Qiguang, Libo Qin, Jinhao Liu, Dengyun Peng, Jiannan Guan, Peng Wang, Mengkang Hu, Yuhang Zhou, Te Gao, and Wangxiang Che. “Towards Reasoning Era: A Survey of Long Chain-of-Thought for Reasoning Large Language Models.” arXiv.org, March 12, 2025. https://arxiv.org/abs/2503.09567.
DeepSeek-Ai, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, et al. “DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.” arXiv.org, January 22, 2025. https://arxiv.org/abs/2501.12948.
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.


















33 Comments
33 thoughts on “The Blue Wheel Threatening the Valley: How Deepseek Is Reshaping the AI Landscape”
This is truly groundbreaking! The idea of an AI model like DeepSeek-R1 evolving its reasoning capabilities through pure reinforcement learning without any initial supervised fine-tuning is a significant step forward in AI development. The self-evolution aspect is fascinating, especially the model's “aha moment” where it learns to extend its reasoning time. It’s incredible to see how this model can learn autonomously and refine its problem-solving strategies.
I’m particularly excited about the distillation process—bringing such advanced reasoning to smaller models that can operate efficiently even with limited resources. This could open up AI accessibility on a much wider scale, from education to healthcare, without requiring massive computational infrastructure. DeepSeek-R1’s approach could revolutionize how we think about AI learning and make it more adaptable and scalable in real-world applications. Looking forward to seeing where this innovation takes us!
🟨 😴 😡 ❌ 🤮 💩
Absolutely! DeepSeek-R1's ability to evolve reasoning purely through reinforcement learning marks a paradigm shift in AI development. The potential to distill these capabilities into smaller, efficient models could indeed democratize access to powerful AI across various sectors.
🟨 😴 😡 ❌ 🤮 💩
I liked how you explained the innovative approach behind DeepSeek-R1 - really fascinating.
🟨 😴 😡 ❌ 🤮 💩
Impressive to see pure reinforcement learning achieving such strong reasoning capabilities in DeepSeek-R1, challenging the traditional reliance on supervised fine-tuning.
🟨 😴 😡 ❌ 🤮 💩
Absolutely! DeepSeek-R1’s reliance on pure reinforcement learning for reasoning showcases a bold step away from traditional training methods, proving that autonomous learning can yield impressive results without the need for supervised fine-tuning.
🟨 😴 😡 ❌ 🤮 💩
DeepSeek-R1 revolutionizes AI training by using pure reinforcement learning—without traditional supervised fine-tuning—to teach LLMs advanced reasoning. It evolves through self-reflection, achieves state-of-the-art results in math and coding, and enables powerful, efficient distilled smaller models. This marks a major step toward scalable, autonomous, and intelligent AI systems.
🟨 😴 😡 ❌ 🤮 💩
An insightful look at how DeepSeek is revolutionizing AI. It's a game changer for the future of large language models.
🟨 😴 😡 ❌ 🤮 💩
It's amazing how DeepSeek-R1 uses reinforcement learning to reason on its own. It's a huge step forward to condense things into smaller models for efficiency. I'm interested to see how issues like prompt sensitivity and language mixing are handled!
🟨 😴 😡 ❌ 🤮 💩
This article showcases DeepSeek-AI's innovative approach with DeepSeek-R1, a large language model that uses reinforcement learning to achieve advanced reasoning capabilities. By moving away from traditional supervised fine-tuning, DeepSeek-R1 excels in various benchmarks, including math, coding, and knowledge tasks. Its ability to self-evolve and refine reasoning through reinforcement learning is notable, as is the successful distillation of its capabilities into smaller, efficient models. This research challenges conventional training methods and opens new possibilities for AI applications and future advancements.
🟨 😴 😡 ❌ 🤮 💩
This article suggests a big shift in model training. If reasoning can be learned mostly through reinforcement learning rather than relying on massive supervised datasets, it could reshape how we build and improve models. The potential to scale this into smaller, more accessible models is especially exciting. DeepSeek is definitely one to watch!
🟨 😴 😡 ❌ 🤮 💩
This is a fascinating breakdown of DeepSeek's innovative approach to LLM training
🟨 😴 😡 ❌ 🤮 💩
Exciting insights on DeepSeek-R1! The shift to pure reinforcement learning is a game changer, allowing the model to evolve and improve reasoning without traditional fine-tuning. Can't wait to see its impact on future AI applications!
🟨 😴 😡 ❌ 🤮 💩
DeepSeek-R1 represents a remarkable advancement in AI, showcasing the potential of reinforcement learning to cultivate sophisticated reasoning capabilities without relying on traditional supervised methods. It's exciting to see how this innovative approach could reshape the landscape of large language models. Looking forward to witnessing its impact on future AI applications!
🟨 😴 😡 ❌ 🤮 💩
Absolutely! DeepSeek-R1’s breakthrough highlights the power of reinforcement learning in developing advanced reasoning without traditional supervised fine-tuning. It’s exciting to think about how this innovation could transform AI, making it more adaptive and impactful across various applications.
🟨 😴 😡 ❌ 🤮 💩
The success of the distillation process prompts a thought-provoking question regarding intelligence transfer in AI. Exploring how complex reasoning patterns are effectively conveyed to smaller models could yield important insights into the essential components of reasoning and guide future model development.
🟨 😴 😡 ❌ 🤮 💩
Great point! The distillation process in DeepSeek-R1 not only makes advanced reasoning more accessible but also opens up fascinating avenues for understanding how intelligence can be transferred efficiently. This could reshape how we approach model development, focusing on the core aspects that enable intelligent behavior.
🟨 😴 😡 ❌ 🤮 💩
Promising.
🟨 😴 😡 ❌ 🤮 💩
This article highlights a potentially significant paradigm shift. If reasoning can be effectively cultivated mainly through RL, reducing reliance on massive supervised datasets, it could change how powerful models are built and improved. The ability to distill this into smaller models has huge implications for accessibility and real-world application. Definitely keeping an eye on DeepSeek!
🟨 😴 😡 ❌ 🤮 💩
Absolutely! The shift towards using reinforcement learning for cultivating reasoning capabilities could drastically reduce the need for vast supervised datasets, making powerful models more accessible and scalable. The ability to distill this into smaller models opens up new possibilities for AI integration across various industries. Exciting times ahead for DeepSeek!
🟨 😴 😡 ❌ 🤮 💩
Truly groundbreaking and inspiring—DeepSeek's innovative leap into reinforcement learning redefines what’s possible in AI reasoning and model evolution.
🟨 😴 😡 ❌ 🤮 💩
very nice!
🟨 😴 😡 ❌ 🤮 💩
DeepSeek's innovative use of reinforcement learning in developing DeepSeek-R1 is truly groundbreaking.By enabling the model to self-evolve and refine its reasoning without supervised fine-tuning, DeepSeek is setting a new standard in AI training methodologies.This approach could significantly influence the future of large language models
🟨 😴 😡 ❌ 🤮 💩
Deep seek introduced a new era of feature to the AI industry
🟨 😴 😡 ❌ 🤮 💩
DeepSeek’s rise is a bold reminder that the AI space is evolving rapidly beyond Silicon Valley. It’s exciting to see innovation coming from diverse corners of the world—definitely a shift worth watching closely
🟨 😴 😡 ❌ 🤮 💩
I can not imagine lossing my job for an AI.
🟨 😴 😡 ❌ 🤮 💩
You won't bro :)
🟨 😴 😡 ❌ 🤮 💩
This is an amazing article!
DeepSeek-R1 is truly revolutionary, expanding the limits of what large language models (LLMs) can accomplish through reinforcement learning alone. By leveraging this approach, DeepSeek-R1 not only enhances the capabilities of LLMs but also opens up new possibilities for AI development. This innovation could lead to more adaptive and intelligent systems that learn and improve continuously, reshaping the future of AI applications across various fields.
🟨 😴 😡 ❌ 🤮 💩
Thank you for your thoughts! DeepSeek-R1 indeed represents a groundbreaking step in AI, pushing the boundaries of LLMs through pure reinforcement learning. This approach could pave the way for more adaptive and intelligent systems, transforming AI applications across numerous domains. Exciting to think about where this could lead!
🟨 😴 😡 ❌ 🤮 💩
It’s inspiring to see how moving beyond traditional supervised methods can lead to such powerful reasoning and self-evolution capabilities. DeepSeek’s progress really highlights the endless possibilities of AI development. Looking forward to seeing how this approach shapes the future of AI research!
🟨 😴 😡 ❌ 🤮 💩
This article provides a fascinating deep dive into DeepSeek-R1’s innovative training paradigm. The shift from traditional supervised learning to reinforcement learning marks a major milestone in advancing reasoning capabilities in LLMs. Especially impressive is the model’s self-evolution and the successful distillation into smaller models—opening new doors for accessible, efficient, and powerful AI. A true step forward in the path toward AGI.
🟨 😴 😡 ❌ 🤮 💩
Incredible read! DeepSeek-R1 is a true game-changer—pushing the boundaries of what LLMs can achieve through pure reinforcement learning.
🟨 😴 😡 ❌ 🤮 💩
Wow, this piece on DeepSeek’s R1 is a real eye-opener! The idea of an AI training itself through reinforcement learning and challenging the status quo in Silicon Valley is both thrilling and thought-provoking. It’s incredible to see how innovation can come from unexpected places and shake up the AI landscape. #AI #Innovation #DeepSeek
🟨 😴 😡 ❌ 🤮 💩
Interesting
🟨 😴 😡 ❌ 🤮 💩