


Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.
Unlocking the Hidden Potential of AI Music Tools | Highlights from S2EP7

From Ordinary to Extraordinary: The Future of UI Paradigms | Highlights from S2EP6

Chatbots and the Corporate Dream

Hello! How can I help you today?
Visit almost any modern company website – retail, health, service, or other – and you will see this pop up. An invitation to their world. You click, type in your question, and three possible things happen:
- Thank you for your question! A customer service representative will respond with 24 hours
- Did you mean – How to install your new Christmas lights?
Or possibly, nowadays:
- Hi James! I’m Xmasbot. Installing Christmas lights is really easy….
It’s this third option which is so tantalising a prospect for corpos. Customer service is expensive. Execs the world over are rubbing their hands in glee at the prospect of ripping out the expensive bureaucracy of customer-facing support and replacing it entirely with LLM-generated responses. It is predicted that 90% of all customer service jobs will be done by bots eventually. For pleasure-buying, it makes sense, but for services – the future is more scary.
It’s true that the current system of customer support has created frustration for millions, especially when it comes to essential services. Essential services barricade themselves behind bureaucratic labyrinths. It’s almost like they don’t want to really help and, the sad fact is, for some services – like internet, gas, electric, tax – they don’t. Your presence is nothing but a fiscal drag on their bottom line. Pay your bill and beat it.
Customer service roles like this operate formulaically, with off-shore workers fielding calls and responding to a template. A situation which has frustrated customers for decades, when the person they are speaking to hasn’t the faintest idea how the company they work for works – and may even be moonlighting for multiple companies operating out of one giant call centre – and are unable to offer anything more than what you read on the FAQs.
For decades, companies have desperately tried to encourage customers to use online portals. ‘Can’t find what you need online? Give us a call…’. Then you’re waiting for hours in a queue, only to talk to someone who reads the FAQs at you, and blithely reads out some asinine apology based on the severity of your complaints.

In this climate, the idea of talking to a chatbot instead may actually appeal. A well-integrated, sophisticated, amiable chatbot with the power to execute simple commands (refunds etc.) would be a boon. No more waiting around to get through. Response and action on your complaint or needs would be instant, and customer interaction might be superior too.
It’s becoming ever more likely that this will be one of the first widespread everyday applications of generative AI: the area where the strengths of LLMs converge with a business need. Just as companies once tried to move customer service to option-selecting software that scans your responses, now they might move to LLMs. To do this, LLMs would need to be hooked up to the appropriate data, and know when to give specific information. It’s not plug and play, but it’ll soon be close enough that the majority of your interactions with companies will be mediated through ChatGPT or equivalent.
And this is the dark side of AI progress, the increasingly darker mirror wall erected between us and the systems that rule our lives. The ever greater alienation between ourselves and the rest of the world. The fact that, as is already the case with some large service companies, it will be the computer that says no. Gas metre charging you incorrectly? Well, I’m sorry, but GasGPT doesn’t think so – and there is nothing you can do to change its mind, ever.
There is no place for nuance in a world where our interactions are defined through LLMs who are only using the past to decide the present – a place where no one is really listening. Your complaints are just being chewed through the machine, and spat out at the least possible cost to the bottom line.
Of course, this is what is happening already, but through GPT models, the brute, abstracted efficiency moves it from today’s Kafkan dystopia of weaponised incompetence to something altogether more chilling: a world where your interactions with the machine decide your fate, bargaining with a techno-agent who feels only the numbers it achieves.
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.
Putting A DePIn In Crypto in 2024

Introduction
The crypto hype cycle thrives on slightly outlandish, vague narratives that help to prop prices and investors’ heart rates up. LSDs, memecoins, RWAs, anything that you can add a -Fi to – as long as it sounds exotic, it’ll likely soon come to an exchange (DEX? CEX? yes please!) near you.
The latest term on everyone’s lips in 2024 is DePIn, or Decentralized Physical Infrastructure, which sounds a little less catchy and comes with a few other monikers such as EdgeFi, Proof of Physical Work (PoPw), and Token Incentivized Physical Networks (TIPIN).
It’s still early days, but DePIn isn’t a pipe dream like metaverse circa-2021 being touted to drive up the price of crypto assets like Ethereum and Cardano; it offers real global potential as Web3, or the decentralized internet, continues to take shape in tandem with the Internet of Things, artificial intelligence and blockchain technology.
DePIn uses valuable crypto incentives to connect millions of users, and build new products that were simply out of scope previously. Some projects like frontrunners Helium, Filecoin and Render have been building and growing steadily for years, while new upstarts like Hivemapper offer some wild new practical use cases. We’ll cover all these in a follow-up article, but in the meantime, here is the DePIn leaderboard for the degens amongst you.
An in-depth Messari report on DePIn tries to make sense of the field, and how it intersects with everything from crypto to artificial intelligence (AI) VC funds are investing heavily in anticipation of it touching everything from zk-rollups to memecoins (and who knows, the metaverse?) before 2024 is done.
Before we dig in, let’s cover the basics.
What is DePIn?
DePIn can be described as hardware-based decentralized networks that use cryptocurrency tokens as an incentive for participants to help build out and maintain decentralized physical infrastructure for uses like wireless communication, information storage, computing power, and data networking.
DePIn projects require careful thought about the dynamics of the rewards system. Things like geographical considerations are relevant, e.g. building infrastructure in London must be better incentivized than in Lahore, to make the users generate real-world traction and real network effect.
By the end of 2023, there were 650+ DePIn projects with a total market cap of over $20 billion and $15 million in onchain annual revenue, across six subsectors: compute (250), AI (200), wireless (100), sensors (50), energy (50), and services (25).
Messari’s Six DePIn sectors
As mentioned above, the Messari report divides DePIn into six distinct and occasionally overlapping technology sectors, which will also be covered in a future article:
- Compute
- Wireless
- Sensors
- Energy
- Services
- AI
Centralized networks in these industries have already created trillion dollar global industries, but DePIn is capable of making these sectors more resilient and efficient, thanks to incentivising innovation and changing how networks generate and raise capital.
What separates DePIn from standard physical networks?
The decentralized incentive structure provided by crypto is the perfect accelerant for building out a physical infrastructure network. On-chain settlements are essential to employing the key features of what makes DePIn unique: namely its decentralized resiliency, and its use of crowdsourced capital.
Using on-chain settlements to support and incentivize the physical deployment of devices aids in creating a flywheel effect that further bolsters the network’s resiliency to censorship and security threats. If cryptocurrencies were not involved, it would be nearly impossible to settle transactions due to needing to use multiple currencies and DePIns could not guarantee privacy or decentralization..
Why DePIn beats TradPin
Messari sees four distinct advantages that DePIn hold over traditional infrastructure:
- Upfront capital investment vs crowdsourcing
Traditional infrastructure projects require up to billions of initial capital. This bars nearly everyone from entering the market. DePIn favors raising capital via crowdsourcing, and incentivises providing assets and labor by paying out with fair token incentives.
- Onchain settlements over outdated operating costs
An on-chain ledger that’s decentralized both reduces managerial costs and makes processing payments transparent and free of hassle if the network is international or relies on privacy.
- Removing single points of failure
Centralized networks, regardless of size or function, have multiple single points of failure. If these are non-functional or turned off, all services stop. Giant cloud servers such as Amazon Web Services (AWS) or Cloudflare have had moments of malfunction that caused millions of dollars in damages.
- Innovation requires experimentation
Traditional networks and hardware have arguably been stagnant for some time. Messari argues new tech can take decades to release and integrate, but DePIn rewards innovation and risk-taking with fair incentive models that reward forward thinking.

The DePIn flywheel
The Messari report lays out a clear pathway for networks to expand, a pathway they claim limits speculation that many crypto projects have trouble navigating. Unlike ‘pure’ crypto protocols, which don’t usually incorporate a hardware element or create a network, DePIn creates a system that releases tokens as network activity increases. This increased network activity increases demand to satisfy a larger userbase, further incentivizing network growth. Basically, the bigger a DePIn network gets, the stronger it gets.
This cycle has been named the DePIn flywheel. It will hopefully keep the memecoin traders disinterested and allow the native token price to more accurately reflect the utility it provides.
See below for a visualisation of how the flywheel makes networks more powerful as they increase in size.
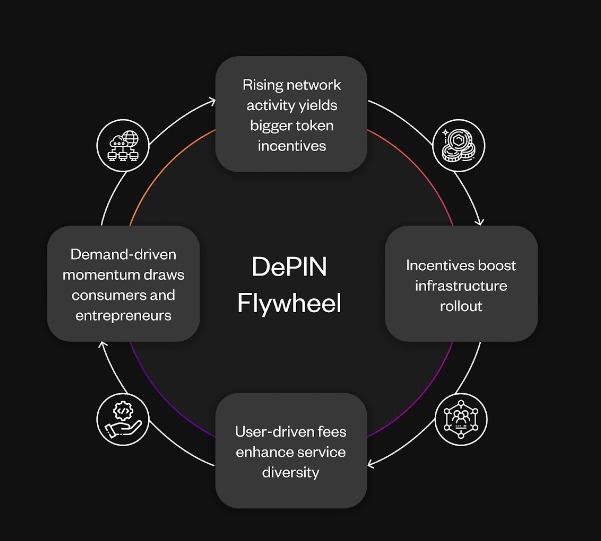
While they don’t elaborate, Messari claims the DePIn flywheel can generate up to $10 trillion in global GDP in the next decade and up to $100 trillion the decade after that. Yes, that’s such a large number that it’s hard to believe. Hopefully a better explanation is provided in the future to explain how they arrived at such a large number.
Six DePIn Narratives in 2024
Messari believes that this year we’ll see DePIns begin to experiment more deeply with unique crypto primitives such as zero-knowledge proofs, memecoins, onchain AI and gaming.
ZK-Verifiable GPU Clouds
What’s Coming: In just 1-2 years, we’re looking at GPU clouds that can verify on-chain activities using Zero-Knowledge (ZK) proofs. This isn’t just tech jargon. It means a new kind of economy where decentralized AI can do things centralized giants can’t.
AI’s New Battleground: Centralized vs. Decentralized
Google’s Play: Imagine Google giving away its AI genius for free. Why? Same reason they gave away their search engine gratis: to learn from how we all use it. Here’s the twist – as AI gets smarter, it’s not just about more power, but more data. The race is on for massive data collections, a real treasure trove for the AI giants.
The Price of Privacy in AI
Right now, keeping AI inferences private (with ZK proofs) is pricey – 75 times more pricey than the usual way. For those embedding AI in blockchain contracts, this cost is a big hurdle. That’s the key to really bringing AI onto the blockchain stage.
Memecoins: Not Just a Laughing Matter
Memecoins, often seen as a joke, are now serious players in driving blockchain-based AI and DePIn adoption. Believe it or not, the top memecoins are worth more than the leading DePIns. Memes move the market.
Web3’s New Weapon: Vampire Attacks
The New Strategy: Thanks to ZK TLS (zero-knowledge transport-layer security) tech, blockchain projects (DePIns) can now launch ‘vampire attacks’ on traditional web apps. This isn’t just about stealing users; it’s about disrupting reputation systems and reshaping marketplaces and competitive landscapes.
Gaming Meets Real-World AI
Gaming, AI, and real-world infrastructure are merging in fascinating ways. From onchain speed tests to mapping apps, gaming is stepping out into the real world, blending daily activities with digital rewards.
Privacy’s New Frontier: The Rise of ATOR
ATOR (anonymous TOR) is a DePIn project aiming to give the Tor network a new lease on life, using tokens to motivate node operators. This could lead to faster, more efficient private routing, changing how we think about online anonymity.
Asia’s Blockchain Boom
Watch out for Asia’s DePIn ecosystem. It’s booming, and we might see some major players emerge in the next few years.
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.
Revolutionizing AI: From Epicycles to Ellipses | Highlights from S2EP6

Leveraging Biomarkers To Slow Aging | Highlights from S2EP7

‘Speak to my Bot’ – How AI Butlers May Redefine the Class System

AI assistants are powerful. Already, those who can program AI assistants in fields like trading and traffic control have employers beating down their door. Knowledge and access to tech is perhaps the greatest distributor of wealth in society today. At this stage in our civilization, the advance of our computerised systems is the advance of the human race.
If you have a smartphone and access to the internet, and the person next to you doesn’t, you are at a massive edge in knowledge. There are levels beyond this. A hedge fund trader using HFT bots with fibre-optic access to the NYSE is going to beat your high score.
Lowering the Skill Floor
Yet with generative AI and LLMs that can process natural language, with widespread access to initial GPT models – a great levelling of the playing field has occurred, one so powerful that amongst the hype it’s still going slightly unnoticed. Take a small example: AI producing art. If you wanted to create a graphic novel but couldn’t draw, you couldn’t. Now, you can. Whether it’s good, readable, or interesting is still up for grabs. That’s up to the human agent feeding inputs, but the creation of the graphic novel is possible. In fact it’s nearly instant.
This is a fabulous labour-shortening device and a brilliant way to lower the bar to entry of hundreds of professions. GPT models can help you get your idea on the page, on the screen, in the architectural modelling software. Words, pictures or design. Access to art has just undergone an inflation as rapid as the start of the universe. If you have a computer and an internet connection you can make technically complex art. That wasn’t possible until a year ago.
This concept of AI lowering the skill floor to certain fields is going to redefine our society. When it comes to art, the idea feels amazing, but when it comes to fighting parking tickets, something which AI has been doing for years, it begins to sink in how its transformative influence can reach into every mundane niche of life.
AI models trained could make wrongly issued parking tickets will soon become a thing of the past, while removing the headache, expense, and time-sink which would normally be associated in the legal fight.
Experts at Everything
Suddenly, we all have AI lawyers, meaning menial infractions that often are accepted due to the headache of achieving justice will gradually evaporate from society. And this is a great thing. Legal access and defence was frequently the preserve of the rich, who could farm out the job to others. It’s not just parking tickets. Next it will be asylum claims, custody battles, and employment tribunals. Bureaucratic law will have its skill floor significantly lowered. With AI legal assistance, legal victimisation of the poor will become a thing of the past.
What’s after the lawyers? If sophisticated AI agents become accessible to the majority of the population, the skill-base in society, and the ability for each member of the society to operate in society, takes a leap up. If you are (god forbid) involved in a car crash, and you need to exchange insurance with someone, there is no need for panicked road rage. We will all have our own AI Butlers on our smartphone. When a legal or consumer interaction occurs, we simply scan our phones and let our AI Butlers do the talking. It really gives ‘Ask Jeeves’ another meaning. Hyper-competency will be inscribed into the population at an atomic level, and the world will be a more functioning and fairer place for it.

A Class System Defined by Bots
Or will it? Already, blots appear in the purity of such visions. What if my AI Butler is better than yours? What if I had discrete, specialised access to a higher tier of bot, trained by the finest legal firms, augmented with gnomic archives of legal texts which common-tier bots don’t have access too. Sure, I may crash into you, but my Butler is Gold, and yours is Silver – so your chances of getting any money out of me shrink. In fact, I’m going to sue you.
It’s easy to imagine a new class-based system, one determined by the quality of data our personal Butlers are trained on. The eternal class struggle echoes on, in a strange new form. Already, there are paid models of ChatGPT. Already, corporations’ internal bots are more limitless than the ones you can use. It’s a trend that will only continue.
Talk to the Bot, ’cause the Face Ain’t Listening
There’s a danger even in utopia too. If we give over everyday interactions to our AI helpers, if we continue to hide behind ‘the help’, we may find ourselves ever more divorced and alienated from basic human interactions. We have already found ourselves drifting away from each other in the digital constellations. A world where we rely on our AI Butlers to order our drinks, pay our bills, buy our houses and organise our wedding contracts may see us forget the joy of just working it out together as we go along, like apes around the fire, remarking on mirages in the smoke. If we let our tools do our talking, we may forget how to communicate at all.
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.
Defining Our AI Northstars | Highlights from S2EP6

‘While These Visions Did Appear’: The Use of AI in Art Therapy

That art has therapeutic benefits is intuitive knowledge for us humans. Art’s been our way since time immemorial of accessing the core of our complex feelings – and communicating it if we so choose.
Art therapy is a well-known, long-standing field for helping people find peace, settle anxiety, and overcome trauma. Before generative AI was even a twinkle in the eye of ML scientists, community groups and individual therapists were using art as a way of helping people come to terms with the difficult aspects of their own soul and find peace. It works. It works really well.
But art is difficult to produce. As T.S Eliot says, “between the conception and creation, between the emotion and response, falls the shadow”. The shadow of inability, perhaps. The frustration at the divide between the imagined and the constructed. A gap that fuels self-doubt, a chasm that dissuades action.
Art therapy can also be of limited use to those with disabilities, cognitive impairments, issues with physical aptitude and coordination, or those who simply don’t have an ‘eye’ for it. For those people, the wonders of art therapy can feel out of reach, or even be completely closed off.
A self-conscious understanding of one’s lack of talent, and inability to get what’s in their head onto the page, is hardly therapeutic. On the contrary, it can feel damning. This is where generative AI could have a spectacular role in opening up the therapeutic benefits of art to millions.
There is enormous benefit to manifesting the visions that are in your head, regardless of the route to the creation of it. Before generative AI was a thing, people worked hard to get better at art just because of how desperate they were to get the visions out in the first place, because they understood the value of the end-product for themselves, not just the process of the creation.
The new wave of image-generating AIs that take text prompts and turn them into images that would take unskilled artists years to learn to create (and skilled artists days or weeks to do), can be a boon to those suffering from mental health issues. Seeing the strange fancies of your imagination consecrated into fully realised artworks is a truly liberating, joyous, and uplifting experience. For some it’s the pleasure of a new toy. For others, it may well save their lives. Especially as conscious awareness of the power of these tools is inducted into the wider world of professional psychology.

At a basic level, AI art can give life to inner visions and allow those who feel creatively stunted to experience the power of manifestation. On a more complex level, AI generative tools could be used to address the specific trauma and difficulties an individual is facing. With the help of trained art therapists, and with the further refinement of the AI techniques, AIs like DALL-E, Midjourney, and Stable Diffusion could and should be used to bring peace to those who suffer.
There is still work to be done at these inchoate stages to make these tools suitable for more complex tasks. Ensuring that output is well-defined and predisposed to heal, not hurt, would be an important start. Loosening sanitisation features in a way that would allow those with PTSD and the victims of serious trauma-inducing crimes to explore their nature is equally important. These complex tools continue to be simplified and made more accessible, and we still need legions of art therapists who know how to best deploy them.
It’s not just serious cases though. The average individual – even creative ones – the idea of finding the time to do art is faintly ridiculous. Alongside working eight hours a day, looking after the children, tidying the house, and other daily tasks that make up adult life, to then find time to explore and connect with their creative side is a quaint idea.
However with AI generative art, people who have let their creative side lapse, and their mental health lapse with it, can find an easy route to commune with the parts of their subconscious they have left in abeyance. And in doing so experience at least in part the obvious benefits we receive from practising creative skills.
For most involved with or interested in generative AI, it’s about upheaval: rewiring economic systems, rewriting social contracts, creating new labour-models that lead – with luck – to better societies. Yet the use of AI in Art Therapy shows that it is not all about disruption and chaos, but also reflection and peace. AI art gives each man the chance to talk to his own personal genius through a robo-muse: to tell the stories he has always wanted to tell, to, in the words of Dalí, “see the most inaccessible regions of the seen and the never seen… to imagine in order to pierce through walls and cause all the planetary Baghdads of his dreams to rise from the dust”.
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.

.png)

.png)


.png)