Donald Trump will be back in the White House in 2025, bringing with him possibly a more business-friendly approach to new digital technology sectors like AI and crypto. His ally Elon Musk has repeatedly warned against AI overreach which could end mankind, but will Trump heed these warnings and suppress AI? Or follow the ideology that deregulation leads to economic growth? Only time will tell.
Trump is pro-business, and that provides good negotiating ground with AI giants like OpenAI, Google, and Microsoft as they try to find the right regulatory frameworks to contain the exponentially evolving machine-learning sector.
Trump’s victory in the 2024 presidential election is sure to have significant implications for the development and regulation of artificial intelligence (AI) and cryptocurrency-related AI projects. While this could enhance the competitive position of U.S. tech firms, it also raises significant concerns about ethical standards, international cooperation, and the trajectory of technological growth.
The implications of these changes will be felt globally, as nations navigate the complexities of AI governance – and AI competition – in an increasingly interconnected world.
Here’s an analysis of the biggest potential impacts on AI that we might see in 2025:
The tech industry, particularly AI companies and startups, may welcome this less restrictive environment. It could potentially accelerate the development and deployment of AI technologies without the constraints of extensive governmental oversight. This approach might foster rapid innovation and allow U.S. companies to maintain a competitive edge in the global AI race.
Trump’s approach is likely to be welcomed by major tech companies that advocate for a lighter regulatory touch. Many in the industry argue that stringent regulations can stifle innovation and their competitiveness. However, companies can’t be relied on to self-regulate: they will surely prioritize profit over ethical considerations.
This is part of Trump’s broad economic agenda to reduce regulations on all businesses – not just digital. It could potentially lead to rapid advancements in AI capabilities – or to rapid AI catastrophe!
Potential Risks of Deregulation
The deregulatory approach raises concerns about safety, ethics, and accountability in AI development. Experts warn that without adequate regulatory frameworks, the risks associated with AI – such as bias, misinformation, and privacy violations – could escalate. The lack of robust oversight may hinder efforts to establish ethical standards and best practices in AI development, which are crucial for addressing the technology’s societal impacts.
Advocates of deregulation say it will spur innovation, however nothing but regulation can establish the ethical standards and best practices needed to address AI’s societal impacts.
Influence over Global Standards
Trump’s deregulatory policies – and his poor reputation internationally – do not bode well for the country’s ability to influence international norms and regulations governing AI. Historically, the USA shaped global AI standards, simply because it is home to the leading tech firms and research institutions: Google, Microsoft, MIT, etc. Trump’s deregulatory policies could diminish the USA’s ability to influence international norms and regulations governing AI. As countries like China continue to advance their AI capabilities, a weak regulatory landscape in the USA might hinder its competitive edge.
Geopolitical Tensions
Trump’s administration has signalled its intention to continue and expand Biden’s protectionist measures. The USA could attempt tighter export controls on AI technologies, particularly to China. Such actions could create barriers to global cooperation in AI development and governance, exacerbating geopolitical tensions, and limiting the USA’s ability to lead global discussions on responsible AI use.
Cryptocurrency and AI Projects
Trump’s election victory is seen as potentially beneficial for cryptocurrency-related AI projects. His administration is likely to foster an environment that encourages innovation and investment in blockchain technologies and digital currencies. This could be advantageous for startups looking to develop new crypto solutions without heavy regulatory scrutiny.
The cryptocurrency market has already shown a positive response to Trump’s victory, with Bitcoin reaching an all-time high. This surge reflects the market’s anticipation of a more crypto-friendly regulatory environment under Trump’s leadership.
However, the lack of regulation could also lead to increased volatility in the cryptocurrency markets. A deregulated environment may attract speculative investments, but could also expose investors to higher risks associated with fraud and market manipulation.
Uncertainty for Innovators
The anticipated changes in regulation could introduce uncertainty for businesses involved in AI development. Companies might face challenges maintaining compliance with rapidly shifting regulations, and this could impact investment decisions and strategic planning. The lack of clear guidelines may deter some innovators from pursuing ambitious projects due to fears of potential backlash or future regulatory changes.
National Security and Defense AI
In the realm of defense and national security, Trump’s administration might pursue a less stringent regulatory environment for AI development related to military technologies. This could lead to closer relationships between the government and private organizations involved in developing defense-related AI. However, this approach might also diminish prospects for international cooperation on defense-related AI governance, potentially exacerbating global tensions in military technology development.
Economic Impact
Trump’s policies are expected to prioritize private sector gains in AI development. This approach might help companies move fast without adequate safeguards! While this could spur economic growth and innovation in the short term, it raises concerns about long-term consequences regarding consumer safety and privacy – as well as catastrophic AI risk.
Credit: Tesfu Assefa
Workforce and Education
The rapid advancement of AI under a deregulated environment could have significant implications for the workforce. It might create new job opportunities in the tech sector, but accelerate job displacement in other industries. Trump’s administration will need to address these challenges, potentially through workforce retraining programs and education initiatives focused on AI and related technologies.
Global Competitiveness
Trump’s approach aims to keep the USA ahead of other regions, particularly Europe and China, in AI development. The administration hopes that reducing regulatory barriers will spur domestic innovation and give the country a competitive edge over more regulated countries. However, this strategy also risks widening the gap between the USA and other nations in terms of AI governance and ethical standards.
Conclusion
Donald Trump’s victory signals a significant shift in the U.S. approach to AI and crypto-related AI projects. The anticipated deregulation is likely to spur rapid innovation and investment in these sectors. However, this may come at the cost of safety, ethics, and long-term societal impacts.
The success of this approach will depend on how well the administration can balance the drive for innovation with necessary safeguards. It will also require careful navigation of international relations, particularly in managing technology transfers and global AI governance.
As the AI landscape mutates under Trump’s leadership, the tech industry, policymakers, and the public will need to remain vigilant. They must work to ensure that the benefits of AI advancement are realized, while mitigating potential risks and ethical concerns. The coming years will be crucial in shaping the future of AI and its impact on society, both in the USA and globally.
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.
In this article, we explore the growing influence of AI-generated content, focusing on deepfake technology and its impact on media and public trust. Deepfakes have made it harder to tell real from fake, challenging media literacy and raising concerns about misinformation, ethical issues, and societal risks. In a paper published in July 2024 in Devotion, Journal of Community Service, Riski Septiawan examines the technology behind deepfakes, their potential for misuse, and the steps needed to tackle the challenges they create. Here, we reflect on the key points of this study.
Introduction
AI-generated media is changing how people consume and evaluate information. Deepfakes, in particular, produce realistic but fabricated content that can manipulate public opinion and spread falsehoods. Septiawan’s research highlights how this technology can undermine trust and emphasizes the importance of media literacy to help people identify and critically analyze manipulated content. The study also discusses the need for ethical guidelines and regulations to address these challenges and ensure AI is used responsibly.
How to identify AI-generated deepfake images? (Credit:Latest.com)
What is Deepfake Technology?
Deepfake technology uses advanced AI methods like generative adversarial networks (GANs) and convolutional neural networks (CNNs) to create lifelike but artificial images, videos, or audio. Here’s how it works:
Face Swap Deepfakes: AI replaces one person’s face with another in an image or video.
Lip Sync Deepfakes: AI matches lip movements to audio using deep learning models, creating videos that look natural.
Audio Deepfakes: Neural networks replicate a person’s voice, allowing someone to appear to say things they never did or even sing in another person’s voice.
A detailed look at the process behind deepfakes:
Data Collection: It starts with gathering extensive images or videos of the target face. The more diverse and high-quality the data, the better the AI model captures the nuances of the subject’s expressions, angles, and lighting.
Facial Recognition: Algorithms analyze the collected data to identify unique facial landmarks, such as the shape of the eyes, nose, and mouth. This data forms the foundation for creating realistic facial movements and expressions.
Face Replacement: Using GANs, the system replaces the original face with the target face. The generator creates synthetic images, while the discriminator critiques them, refining the output until it mimics reality.
Synchronization: Deep learning models align the replaced face’s lip and eye movements with the original speech or actions. LSTM and transformer models ensure temporal coherence, making the output seamless.
Editing and Finalization: The final step blends the manipulated face into the original media, adjusting details like skin tone, lighting, and shadows to produce content that withstands scrutiny.
Beyond face swaps, deepfake technology enables lip-syncing and audio deepfakes. Lip-sync deepfakes use AI to synchronize lip movements with new audio inputs, allowing actors’ dialogue to be dubbed into multiple languages without losing natural synchronization. Meanwhile, audio deepfakes mimic voices using neural networks, enabling applications such as AI-generated voiceovers and voice modifications.
Positive Applications: Harnessing the Power of Deepfakes
Despite their risks, deepfakes hold immense potential for positive applications:
Entertainment and Creativity: Filmmakers can recreate historical figures, enhance special effects, and localize content for global audiences, pushing the boundaries of storytelling.
Education: Deepfakes enable immersive learning experiences, such as simulating historical events or creating realistic scenarios for medical training.
Healthcare: In therapy, virtual recreations of lost loved ones are being explored as tools for grief counseling. Deepfake avatars also simplify patient-doctor communication by presenting complex medical procedures in relatable formats.
Hyper-Personalization Meets Manipulation
Deepfake technology is revolutionizing personalized marketing. Imagine advertisements tailored to an individual’s preferences—adjusting the celebrity’s voice, accent, or setting to suit a viewer’s cultural context. While this enhances consumer engagement, it also opens the door to darker applications.
These examples demonstrate that deepfake technology, when used responsibly, can amplify human creativity and problem-solving.
How Deepfakes are Shaping Celebrity Realities
Many well-known deepfake examples feature public figures and celebrities, often demonstrating the technology in a seemingly harmless way. For example, a video of soccer star David Beckham speaking nine different languages showcases the impressive capabilities of deepfake technology, while comedian Jordan Peele created a “public service announcement” by overlaying his mouth and jaw onto former president Barack Obama using accessible apps. Additionally, several deepfake videos on TikTok convincingly portray actor Tom Cruise. Legally, the technology itself is not illegal, but the content it generates can cross legal boundaries.
Although these examples may seem harmless or entertaining, they show how easy it is to use this technology. When applied without consent, deepfakes can invade privacy and sometimes violate laws related to data protection or personal rights.
The duality of deepfake technology becomes evident when its ethical challenges are scrutinized. While it empowers filmmakers, educators, and marketers, it also provides tools for exploitation. The same tools used to create relatable content can fabricate fake, harmful media that damages reputations or spreads misinformation, raising questions about consent and accountability. One of the gravest concerns is the creation of non-consensual explicit content, disproportionately targeting women. Such violations not only harm individuals but also highlight the lack of safeguards to prevent misuse.
Deepfakes also threaten the integrity of information ecosystems. In an age of fake news, deepfakes add a potent weapon to the arsenal of disinformation campaigns. Videos of political figures making inflammatory statements or fabricated footage of global events can manipulate public opinion, incite unrest, and undermine trust in institutions.
In a non-media related application, disturbingly, Scammers may found deepfake technology to be a potent tool for targeting vulnerable individuals, particularly the elderly, by creating hyper-realistic audio or video manipulations that mimic the voices and appearances of trusted family members or friends. Using deepfake audio, criminals can place convincing phone calls, imitating a loved one’s voice, and fabricate urgent scenarios—such as requesting financial help due to an emergency or posing as a grandchild in distress. The same technology can generate fake video calls, further solidifying the illusion and exploiting emotional trust. This tactic not only makes it easier to deceive the victim but also bypasses traditional verification methods, as the impersonation appears authentic. Such scams highlight the urgent need for public awareness and technological safeguards to protect against deepfake-enabled fraud.
The question of accountability looms large. Should the creators of deepfake tools bear responsibility for their misuse? While some advocate for strict regulations, others argue for self-regulation within the industry. Septiawan’s research emphasizes the urgent need for a balanced approach that protects individuals without stifling innovation.
Societal Implications: The Erosion of Trust in Media
Deepfake technology has profound implications for society, particularly in its ability to erode trust. The mere existence of deepfakes fuels skepticism, giving rise to the “liar’s dividend”—the phenomenon where authentic content can be dismissed as fake. This undermines evidence-based discourse, making it easier for bad actors to deny accountability.
The burden of verifying authenticity falls heavily on journalists, fact-checkers, and media platforms, straining resources and complicating the dissemination of reliable information. Furthermore, constant exposure to fabricated realities affects public perception, fostering cynicism and confusion.
Septiawan’s research highlights the psychological toll of deepfakes on individuals and communities. As people struggle to discern fact from fiction, the resulting mistrust can divide societies and exacerbate conflicts.
Legal and Regulatory Responses
The legal landscape surrounding deepfakes remains fragmented. While some countries have criminalized malicious deepfakes, enforcement remains a challenge, especially in cross-border contexts. Laws often lag behind the rapid evolution of AI, leaving gaps that bad actors exploit.
Tech companies are stepping in to address these gaps. Platforms like Facebook and Twitter have implemented policies to identify and remove harmful content, while companies like Microsoft are developing tools to detect AI-generated manipulations. Yet, these efforts are reactive, highlighting the need for proactive solutions like embedding digital watermarks in authentic media and educating users about deepfake detection.
Credit: Tesfu Assefa
Why Media Literacy Matters
As deepfakes become more common, the ability to recognize manipulated media is critical. Septiawan stresses that media literacy is essential for helping people evaluate what they see and hear. For instance, Meta has introduced “Made with AI” tags to label AI-generated content, aiming to improve transparency. However, such measures need broader education efforts to be effective.
Data literacy is another important area. Understanding how AI works and how data is used can help hold creators accountable and prevent the misuse of this technology.
Conclusion
The rapid growth of deepfake technology highlights the need for stronger media and data literacy, clear ethical standards, and regulations to manage its risks. Deepfakes have the power to influence opinions, erode trust, and harm individuals, making it essential to act quickly to address these challenges. By promoting awareness and accountability, society can better manage the impacts of AI-generated media while also benefiting from its positive applications.
Reference
Septiawan, Riski. “Critical Analysis of AI-Produced Media: A Study of the Implications of Deepfake Technology.” Devotion Journal of Community Service 5, no. 7 (July 2024): 735–741. https://doi.org/10.59188/devotion.v5i7.747.
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.
Bitcoin’s hit to $99,500 today, tantalizing crypto price watchers. The king of crypto attracts renewed attention from retail and institutional investors as it flirts with $100,000.
The recent U.S. presidential election delivered a Republican Senate majority and a Trump presidency, signaling the possibility of more relaxed crypto regulations. Just over six months ago, it was unthinkable that Bitcoin could hit $100K, despite what all those laser eyes would have you believe. Now, Bitcoin’s path to $100,000 feels inevitable. The only real question is: when will it happen?
Disclaimer: This article is for educational purposes only and does not constitute financial advice of any kind.
Bitcoin Catalysts for the Rally to $100,000
The recent surge in Bitcoin’s price marks a turning point in the cryptocurrency market. Following Trump’s stunning election victory over Vice President Kamala Harris, Bitcoin has rallied non-stop, and the news that other pro-Bitcoiners like Elon Musk and RFK will be in Trump’s government hasn’t hurt. This surge highlights the potential for November to remain a historically strong month for Bitcoin, as past data shows consistent upward trends during this period.
The convergence of political, institutional, and retail factors is fueling optimism for Bitcoin to break the $100k barrier.
Bitcoin set a new all-time high above $94K on November 19 (Credit: CoinMarketCap)
Gary Gensler, the current U.S. Securities and Exchange Commission (SEC) is widely seen as anti-crypto. It is hard to argue with this opinion: Gensler has sued and fined hundreds of crypto firms including Kraken, Coinbase, and Ripple. Trump said earlier this year – at Bitcoin Nashville – that he would fire Gensler on day one, and rumors are now that ‘GG’ will resign and be replaced by Brian Brooks, a former Acting Comptroller and CEO of Binance USA, which would be an extremely factor.
Trump is promising to shake things up by aligning with a celebrity team that consists of crypto favorite Elon Musk – who will lead the new Department of Government Efficiency (DOGE), Vivek Ramaswamy, and Robert F. Kennedy Jr. who revealed buying 21 Bitcoins, including three for each of his children. This is one-millionth of BTC’s hard cap of 21 million coins.
The creation of the Department of Government Efficiency has also added momentum. While primarily aimed at cutting government spending and improving, its acronym is a nod to Dogecoin. This has sparked excitement among Bitcoin enthusiasts and bolsters the narrative that crypto is becoming a core part of governmental strategies, encouraging wider adoption and investment.
Bitcoin ETFs and Institutional Capital
Institutional interest has reached high levels, with spot Bitcoin ETF inflows soaring. Major asset managers are racing to secure Bitcoin ETFs, signaling their belief in Bitcoin’s long-term potential.
Retail investors are also playing a significant role in the rally. Data shows retail interest in Bitcoin has hit a 52-month high, driving increased trading volumes. Sidelined investors are expected to ‘FOMO in’, driving Bitcoin’s price higher.
Bitcoin Halving
The 2024 Bitcoin halving event brought relief and excitement to investors. It is widely believed that it takes Bitcoin at least six months to surge after the halving event. The event, which cuts the supply of new coins in half, is a simple lesson in economics. As the supply decreases and demand rises, prices naturally go up.
Will Bitcoin Reach $100k in 2024? What Experts Say
Bitcoin’s future just got a serious upgrade. Geoff Kendrick, Standard Chartered’s global head of digital assets research, is leading the charge. Kendrick predicts Bitcoin could hit $125,000 by the end of 2024 and $200,000 by late 2025. What’s fueling his optimism? Trump’s bold pro-crypto promises.
Trump plans to clean up the system by dismissing SEC chair Gary Gensler, whose tough stance has cost crypto firms millions in fines. I bet my last satoshi that no crypto fan wants to see Gensler in charge of the SEC given the scale of damage he has done to the crypto industry. He won’t be missed.
“We’ve gone from a regulatory landscape under Biden that was largely adversarial, to one that actively supports the industry,” said Kendrick.
Ryan Lee of Bitget Research expects Bitcoin to touch the $100,000 mark by the end of November.
In Lee’s words, “If history repeats itself, Bitcoin’s projected growth could take it well above $100,000 by month-end,” Lee remarked. Coinshares’ head of research James Butterfly claims that $100,000 by the end of the year “doesn’t sound unreasonable” as it only accounts for 10% of gold’s market cap. Crypto bros see Bitcoin as the ‘digital gold’.
Gabriele Giancola, the CEO of Qiibee says Trump’s re-election could propel BTC to $100,000 in 2024.
“Bitcoin’s performance historically aligns with significant geopolitical and economic events, and the aftermath of the U.S. election could see BTC reaching $100,000 this year or shortly after a potential Trump reelection.”
Not all experts and analysts share this excitement. Some are approaching Bitcoin’s price discovery with a dose of caution. Ki Young Ju, the founder and CEO of the crypto intelligence platform CryptoQuant is taking the caution route. According to Ju, Bitcoin will tumble to nearly $59,000 at the end of the year.
Other analysts believe $100,000 is within sight but not in 2024. Bitfinex’s Head of Derivatives Jag Kooner expects Bitcoin to hit the $100k milestone on Trump’s inauguration on January 20, 2025.
As Bitcoin approaches $100,000, where are we in the four seasons of crypto seven months after the halving?
Conclusion
Bitcoin’s unstoppable journey to $100k makes for a powerful narrative of shifting tides in politics, economics, and investor sentiment. With Trump’s promised pro-crypto policies, a wave of institutional interest, and the ever-powerful force of retail FOMO, the stage is set for Bitcoin to make history.
Whether it happens this week, this year or next, one thing is clear: the excitement, innovation, and potential surrounding Bitcoin are unstoppable. The $100K milestone is somewhere in the near future.
We are witnessing history in the making.
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.
Charles Hoskinson, founder of Cardano and Input Output (IOHK), is stepping into a significant role in shaping cryptocurrency policy in the United States. Hoskinson announced this development on Twitter on November 9, which comes at a critical time for the industry, at the election of pro-crypto presidential candidate Donald Trump over Kamala Harris.
Hoskinson underscored the need for regulatory clarity to move the crypto industry forward and undo the damage that has been done over the years.
Hoskinson calls it the ‘best opportunity’ to influence crypto policy. President Trump campaigned on promises of regulatory clarity for cryptocurrencies, and the new administration seems to be playing ball to deliver on these commitments.
The Republican’s clean sweep aligns with the crypto industry’s need for a supportive regulatory environment. With no clear regulations, many crypto companies suffered at the hands of the U.S. Securities and Exchanges Commission (SEC).
The Importance of Regulatory Clarity
The lack of clear regulations has been a longstanding issue for the crypto industry in the USA. Over the years, companies like Ripple, Kraken and Coinbase have faced significant challenges, such as prolonged legal battles with the SEC, which Ripple CEO Brad Garlinghouse claims has stifled innovation.
Due to the crackdown and regulatory uncertainty, several U.S. crypto companies threatened to relocate overseas. However, the tide is turning in the hope that regulatory clarity will bring more developers and investors to the industry and to the USA.
The Hoskinson’s Vision
Hoskinson declared, “We have to do this, and we have to get it done.”
His vision includes a policy office in Washington, D.C., staffed by experts dedicated to working with lawmakers and administration officials. The goal is a bipartisan group that fosters innovation while addressing sensible regulatory concerns.
This initiative is expected to provide the clarity needed for crypto businesses to thrive without fear of regulatory retaliation. Hoskinson wants to help create a transparent framework that defines what constitutes a security versus a commodity.
Credit: Tesfu Assefa
Pro-Crypto U.S. Policy is a Watershed Moment
The inclusion of crypto figureheads in the new Trump administration is truly a transformative moment for the entire industry. By advocating for regulations crafted by the crypto community, Hoskinson seeks to ensure that the U.S. remains a global leader in blockchain innovation. He has openly criticized the influence of large financial entities like BlackRock on policy-making, emphasizing the need for industry-driven solutions.
Hoskinson sees this as an opportunity to reverse the damage caused by the SEC due to regulatory overreach. The crypto industry has found a powerful friend in Trump and is now taking the fight to the SEC.
If successful, the pro-crypto U.S. policy could set a precedent for how blockchain companies engage with governments worldwide. This approach not only enhances the legitimacy of the industry but also paves the way for the broader adoption of decentralized technologies. The days of the USA trying to kill crypto seem to be over.
Impact on the Market
The announcement has already had a tangible impact. Cardano’s ADA token surged massively following the news, reaching a seven-month high. This price movement reflects growing investor confidence in the potential alignment of U.S. regulations with the needs of the crypto industry. Market participants are optimistic that clear rules will reduce uncertainty and encourage institutional adoption of blockchain technologies.
Hoskinson’s move also positions Cardano as a leader in bridging the gap between technological innovation and policy. By taking an active role in shaping regulations, Hoskinson aims to foster an environment where decentralized platforms can coexist with traditional financial systems.
Wrapping Up
Hoskinson’s decision to take an active role in shaping U.S. crypto policy is a bold step forward for the industry:
With clear regulations, the blockchain space can unlock its full potential, fostering innovation and economic opportunity.
With industry experts helping shape policy, the crypto space has the best shot to be where it wants to be.
The true impact of these shifts will be known soon.
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.
Imagine a reinforcement learning (RL) agent that not only reacts to its environment but anticipates its own actions, unlocking a new dimension in AI adaptability and learning efficiency. Researchers at Google DeepMind have introduced Self-AIXI—a groundbreaking RL model that maximizes learning through self-prediction. By emphasizing predictive foresight over exhaustive planning, Self-AIXI reduces computational complexity while enhancing adaptability, potentially transforming the landscape of AI-driven decision-making and dynamic interaction in complex environments.
The Foundations of Reinforcement Learning and AIXI
AIXI, a foundational model for universal artificial intelligence, operates on Bayes-optimal principles to maximize future rewards by planning across a vast array of possible environments and outcomes. However, its reliance on exhaustive planning presents a major computational burden, limiting its real-world scalability. Self-AIXI innovates on this framework by reducing the necessity for complete environmental simulations, instead predicting outcomes based on current policies and environmental states. This strategic shift enables more resource-efficient learning and decision-making.
Self-AIXI’s Core Mechanism: Bayesian Inference over Policies and Environments
The defining feature of Self-AIXI lies in its ability to perform precise Bayesian inference across both policy trajectories and environmental dynamics. Traditional RL models typically update their policies by recalculating strategies from scratch, imposing significant computational overhead with each decision point. Self-AIXI bypasses this by integrating learned policies into a continuous self-predictive framework, refining and adapting its behavior without redundant recalculations. This unique approach accelerates learning while retaining high levels of adaptability and precision.
Q-Learning Optimization through Self-Prediction
Self-AIXI’s self-predictive mechanism closely aligns with classical RL optimization techniques like Q-learning and temporal difference learning, but with critical distinctions. Unlike conventional models that estimate future rewards based solely on external stimuli and fixed policy trajectories, Self-AIXI anticipates its own actions within evolving environmental contexts. By doing so, it converges toward optimal performance with reduced planning complexity. This efficiency advantage makes it possible to achieve performance parity with resource-intensive models like AIXI, all while maintaining computational sustainability.
Balancing Computational Efficiency and Scalability
The scalability of Self-AIXI in practical applications remains an area of active investigation. While its theoretical model reduces computational demands, real-world deployment necessitates further exploration of its efficiency compared to traditional deep learning systems. Contemporary deep learning models benefit from vast data availability and intricate network architectures, enabling them to solve complex problems with unmatched accuracy. To compete, Self-AIXI must demonstrate equivalent robustness and adaptability without compromising on resource efficiency, training speed, or data utilization.
Practical and Theoretical Challenges
Despite its promise, several challenges remain for the practical adoption of Self-AIXI. Key considerations include:
Data Utilization and Efficiency: Self-AIXI must optimize data usage and training speeds to compete with traditional deep learning systems known for their extensive datasets and computational intensity. Understanding how self-prediction scales with increasing data complexity and task demands will be critical for its viability.
Energy Consumption and Resource Allocation: As AI systems scale, energy consumption becomes a significant concern. Self-AIXI’s resource-efficient learning approach must demonstrate tangible reductions in energy consumption compared to existing deep learning frameworks, validating its sustainability potential.
Scalability in Complex Environments: Testing Self-AIXI across diverse and dynamic real-world environments is necessary to assess whether its self-predictive framework can maintain accuracy and adaptability without sacrificing computational efficiency.
The Role of Minimal and Discrete Models in AI Evolution
Self-AIXI’s focus on minimal, self-predictive architectures aligns with theories that simpler, rule-based systems can produce complex behaviors similar to those exhibited by modern AI. This idea resonates with Wolfram’s assertion that discrete systems can potentially match or complement the capabilities of complex deep learning models. For Self-AIXI and similar models to gain prominence, rigorous testing against existing AI paradigms is required, demonstrating comparable or superior performance across a spectrum of complex tasks, including natural language processing, image recognition, and reinforcement learning in dynamic environments.
Credit: Tesfu Assefa
Future Directions and Research Validation
To validate Self-AIXI’s potential as a minimal, efficient alternative to deep learning, researchers must focus on:
Benchmarking Performance on Standard Tasks: Direct comparisons with traditional deep learning systems on benchmark tasks will reveal Self-AIXI’s practical utility.
Scalability Testing Across Diverse Applications: Real-world applications often involve multi-layered complexities. Evaluating Self-AIXI’s adaptability across diverse contexts, including dynamic and unpredictable scenarios, will inform its long-term scalability potential.
Energy and Resource Efficiency Metrics: One of the key benefits of minimal models is their potential for lower energy consumption and reduced resource usage. Measuring these attributes in large-scale AI implementations is critical to understanding their broader implications for AI sustainability.
Conclusion: Charting the Future of AI Learning
Self-AIXI’s self-predictive reinforcement learning approach offers a compelling new direction, shifting away from computationally intensive planning towards predictive foresight and adaptive behavior. While theoretical advantages abound, practical hurdles related to scalability, data efficiency, and energy consumption remain critical challenges. As researchers test and refine this model, Self-AIXI may redefine AI’s potential, offering smarter, more efficient agents capable of navigating increasingly complex environments with foresight and adaptability.
If you were a college student or Western counterculture person in the late 1960s-70s, the albums of Firesign Theatre occupied more space on your shelf and in your hippocampus than even The Beatles or Pink Floyd. If you were an incipient techno-geek or hacker, this was even more the case. Firesign was the premier comedy recording act of the very first media-saturated technofreak tribe.
In his tremendously informative and enjoyable history of Firesign Theatre titled Firesign: The Electromagnetic History of Everything as told in Nine Comedy Albums, author Jeremy Braddock starts by giving us the roots of a band of satirists that started out (to varying degrees) as social activists with a sense of humor. He shows them slowly coming together in Los Angeles while infiltrating, first, the alternative Pacifica radio stations like KPFK in Los Angeles, and eventually, briefly, hosting programs in the newly thriving hip commercial rock radio stations of the times, before they lost that audience share to corporatization.
Braddock takes us through the entire Firesign career and doesn’t stint on media theory and the sociopolitics of America in the 20th century that were a part of the Firesign oeuvre.
For those of us out in the wilds of the youth counterculture of the time, without access to their radio programs, it was Columbia Records albums that captured our ears and minds, starting with Waiting For the Electrician or Someone Like Him in early 1968. Their third album, Don’t Crush That Dwarf Hand Me the Pliers sold 300,000 right out of the gate and, in the words of an article written for the National Registry in 2005, “breaking into the charts, continually stamped, pressed and available by Columbia Records in the US and Canada, hammering its way through all of the multiple commercial formats over the years: LPs, EPs, 8-Track and Cassette tapes, and numerous reissues on CD, licensed to various companies here and abroad, continuing up to this day.” As covered toward the end of the book, they have been frequently sampled in recent years by hip-hop artists.
My introduction to Firesign came as the result of seeing the cover of their second album How Can You Be In Two Places At Once When You’re Not Anywhere At All in the record section of a department store in upstate New York. It was the cover, with pictures of Groucho Marx and John Lennon and the words “All Hail Marx and Lennon” that caught my eye.
It was the mind-breaking trip of Babe, as he enters a new car purchased from a then-stereotypical, obnoxiously friendly car salesman, and finds himself transitioning from one mediated space to another, eventually landing in a Turkish prison and witnessing the spread of plague, as an element of a TV quiz show.
The album ends with a chanteuse named Lurlene singing “We’re Bringing the War Back Home.” This was all during the militant opposition to the US war in Vietnam. Probably few listeners would have recognized “Bring The War Home” as the slogan of The Weatherman faction of Students for a Democratic Society (SDS), but Braddock gets it, like he gets the seriousness of Firesign’s satire. Indeed, Braddock notes that several reviewers, writing with appreciation about one of their albums, averred that its dystopia was “not funny.”
Most fans would agree with me that the peak of the Firesign run on Columbia Records was the exceedingly multivalent Don’t Crush That Dwarf, Hand Me The Pliers and the futuristic, AI-saturated I Think We’re All Bozos on this Bus, which I note in this interview predicted the future better than any of the self-described futurists of the 1970s. But to apprehend the richness of those two psychedelic assaults on the senses and on the idiocracy of its times, you will need to read the book and listen to the recordings or at least read this interview. Jeremy Braddock is, in his own words, a literary scholar and cultural historian specializing in the long history of modernism. (What? Not postmodernism!?) He teaches literature in English at Cornell University in Ithaca, New York. I interviewed Braddock via email.
RU Sirius: This is not light reading for people who remember the Firesign Theatre as a silly comedy group with a few lines they like to quote situationally. You hit us right up front with references to the literary theories of Mikhail Bakhtin (heteroglossia) and with a series of left counterculture and avant-garde theater references that were part of their history. These made me swoon (partly with nostalgia.) But all this might not appeal to the old boomer stoner who might by now be pretty reactionary. Your thoughts?
Jeremy Braddock: I get where that question is coming from, because I like the joke about the erector set as much as anyone. The version of that question that someone of my generation would ask is, “Why are you asking us to think that these four old stoners are actually major thinkers about media, technology, and culture, and among the most interesting artists of the late 20th century?” (Which – spoiler – is what I’m saying.)
I definitely don’t want to be policing anyone’s enjoyment, and folks like the “reactionary” person conjured in your question might prefer to read Fred Wiebel’s Backwards into the Future, which is a big collection of interviews he did with the four Firesigns in the ’90s, or just listen to the albums again. But one thing that was very striking to me as I researched the music mags and fanzines of the 1960s and 1970s was that they understood that the Firesign albums were great art and they took them very seriously – they knew that the records were both the White Album and Gravity’s Rainbow, if you like. They also tended not to see a contradiction between being a stoner music fan and being intellectually engaged and reading books. The Creem reviewers especially were way more likely to understand Firesign albums as more frightening than funny, and that is because like so many others they saw the bigger frame that the albums created, and they knew that shouting, “what is reality?” at the principal from the back of a high school gym in the context of Kent State and the Vietnam War was not only hilarious but a very good idea, and even in its way profoundly political, if you think about all the things ‘reality’ might mean.
I wanted to honor that seriousness, and to put as much thought into the book as Firesign obviously did making their records. But I also wanted for my writing to be in tune with the albums’ multilayered playfulness, so I wanted it to be weird and even include some jokes, and at the same time I did not want only to be writing for academics. That might not be everyone’s cup of tea, but it is what the Firesign albums sound like to me. Firesign knew that the key to a good record was to include things you might not appreciate until the third or tenth listen, and I think that’s true of a good book – fiction or nonfiction – too.
RU: While Dwarf remains my choice as the group’s crowning achievement, it was Bozos that made Firesign’s reputation, as you note, in Silicon Valley and with the tech geeks. There’s such complexity to the history of that album. I like to tell people it’s the most accurate prediction of the future from the 1970s (with the possible exception of the title of Gary Numan’s Are Friends Electric.) But for Firesign, it was very much about the present and even about the past. I was stunned to learn from you about the influence of the Chicago Century of Progress Worlds’ Fair 1933 official guide book (and about its slogan “Science finds – Industry Applies – Man conforms.” It’s shocking, to put it mildly). Please say a little about how the various expositions romanticizing technological progress collided with the social and cultural realities of 1971 as understood from the countercultural perspective of Firesign to form the composition of Bozos.
JB: I’m glad you appreciated that, because it’s part of what I try to signal through the book by using the term “media archaeology,” which is a relatively new strain of scholarship in media studies that looks at old technologies – working with the devices when possible – and thinks about, among other things, how things might have developed otherwise. The Firesign Theatre were, without a doubt, media archaeologists. They knew that the Hollywood studio they were recording in was originally built in 1938 for radio and used for antifascist propaganda broadcasts. They thought about what it meant to be using the same microphones and old sound effects devices in the age of Vietnam.
As to Bozos’ conceit of the Future Fair, there’s no doubt that Disneyland (and Disneyworld, which opened in 1971) was one of the things they were riffing on. But they had the Guidebook to the 1933 Century of Progress World’s Fair with them in the studio, and they took a lot of ideas from it, as you noticed. The background of the World’s Fairs was useful to them because of their history as events that were used by governments to communicate messages about political culture, promote commerce, and exhibit new technologies. The first demonstration of stereo took place at the 1933 Chicago Fair; famously, television was introduced at the 1939 Fair in New York. I don’t think Firesign deliberately chose the 1933 Fair over the others – probably they just picked up the Guidebook at a used book shop – but it was a key moment in the development of World’s Fairs because it was the first time that corporations had pavilions alongside those for different nations, and that comes through subtly in Bozos where the “model government” and the President himself (itself) are exhibits at the Fair, and not the other way around.
As the ominous “Science Finds – Industry Applies – Man Conforms” slogan implies, it institutionalized the idea of technological progress as all-powerful and unquestioned good. I think we’re seeing that play out now in the techno-utopian discourse about the inevitability of AI. Despite the fact that Century of Progress is not as well known as the 1893 or 1939 fairs, I was happy to see that Shoshana Zuboff cites the 1933 slogan in the introduction to her important book TheAge of Surveillance Capitalism.
And yes, I agree that Don’t Crush That Dwarf is more amazing than Bozos, but I have grown to really appreciate that album, especially the sound design.
RU: The early text-based conversational AI program ELIZA was another big influence on Bozos that added to their cred among both early and latter-day tech freaks. Bozos is, in a sense, a collision of AI, VR (the funway is clearly some kind of simulation or partial simulation) and a totally surveilled entertainment space that people enter into voluntarily. It all feels very contemporary. And one of the Firesign’s had some direct engagement with ELIZA, if my reading is correct. Say a bit about how their understanding of ELIZA led them to make something that was and is related to by hackers and other techies and maybe about some of the problematic or complicated aspects of that relationship.
JB: Yes, Phil Proctor interacted with the original chatbot ELIZA at a work fair in LA in 1970. It was entirely text-based, of course, and he took a sheaf of the printouts into the studio as they wrote the album. But they imposed a lot of changes along the way; instead of private psychotherapy (which is what ELIZA emulated), they used it to portray the fantasy of citizens’ access to politicians; they used their presidential chatbot to foreclose conversation, whereas ELIZA is all about keeping the conversation going (which is why it was so popular).
I understand that they had access to other computer culture, too, because according to my friend Herb Jellinek – a Lisp hacker from back in the day – some of the nonsense noises that Dr. Memory makes as Clem hacks into the backend of the ‘President’ are terms that come from the DEC PDP-10 (a computer that would have run ELIZA), but are not found in the ELIZA script. So they had some other source, but I don’t know what it is.
But to answer your question, I think that the Clem character was easily understood by the early Silicon Valley generation – and Proctor has endorsed this reading, too – as a kind of heroic early hacker, and the fact that he succeeds in “breaking the president” would surely have appealed to a strain of political libertarianism that is not necessarily in step with the left counterculture from which Firesign came, but became and remains influential in Silicon Valley.
Credit: Tesfu Assefa
RU: There’s a note in the chapter about Bozos that indicates that people used to see Clem as the hacker hero of the narrative, but that is no longer the case. I wonder why and how you see that as having changed. The narrative, I think, can be pitched, so to speak, as twisted, very surreal early cyberpunk humor.
JB: This sounds like a question that I’d like you to answer. But I would point out that one trajectory out of Clem and Bozos would be toward something like Anonymous (which appears to be no longer with us) while another is with the hackers who became powerful tech innovators like Steve Jobs, who was a fan of Bozos, according to Proctor. It seems important to stress that Firesign were definitely not Luddites – they were always eager to experiment with new technologies and would certainly have thought more about AI – but they were always skeptical and thought critically as they worked.
RU: Like Firesign’s albums, there are so many thematic streams running through your book, I wonder how you organized the flow. Was it difficult? It’s funny that what they did sort of demands a multivalent response.
JB: Yes, it was difficult. I decided to write the Bozos chapter first, thinking that the album’s linear storyline would be the easiest one to deal with. It was easy to write, but I was not overjoyed with it and ended up substantially revising that chapter when I’d finished everything else.
Writing that chapter helped me realize a couple of things. First, that I wanted to write a book that would interest people who hadn’t heard of the Firesign Theatre, people of my generation who might get interested in what the Firesign Theater did if I drew them in as readers, even if they were never going to listen to the albums. And second, I also wanted to write not only for an academic audience but for a smart general audience too, which included old heads like you, who do know the albums well.
I decided to make the book roughly chronological, so that it read like a history of the group and the times they were working in. But I also chose to give each chapter the organizing theme of a particular medium – book, radio, cinema, AI, television – which showed a second kind of organization that allowed me to weave in other themes, as you said.
What bothered me about the first draft of the Bozos chapter is that it was pretty much a standard literary reading, and kind of boring. It didn’t really convey what was special about the albums, so I decided to try to make my writing weirder and see what happened, hoping that at some level it could convey the experience of hearing the albums for those who had never heard them. So I then turned to Dwarf, deciding to let it rip and see what happened. That chapter took about a year to write and included a lot of material that ended up getting excised – such as a huge long detour about what Allen Ginsberg was up to in 1965 and 1966, which I will not belabor now other than to say that it’s totally fascinating but good that I cut it – but it gave me the confidence that going down other rabbit holes was totally appropriate to the way the Firesign albums worked. Hence the excursions into rock operas versus concept albums, the MGM auction, Firesign’s Zachariah script, and the introduction of Dolby into the recording studio (and Dolby’s uneven history in cinema versus sound recording), which Ossman had insisted was critical for what they were able to do on that album.
RU: One example of a thematic stream is your generous recounting of Firesign’s use of the tools of the recording studio and other aspects of recording technology. Their mastery of the studio should be at least as legendary as Brian Eno’s or any of the other esteemed record producers. I hope your book rouses some attention around that. What surprised or intrigued you most about their uses of recording technology?
JB: Yes, I thought this would be really important if I could get it right, because anyone can see that the sound they are able to get on those Columbia records is a kind of miracle. They did plenty of good work after 1975, but none of it sounds as good as those early albums. I spent a couple of weekends with David Ossman as I was starting work on the book, and this was one of the things I was hoping he would talk about, or find evidence of in his papers, and both those things ended up being true – although sadly the engineers that they worked with at Columbia had all died by then, which might have been a goldmine had I thought to track them down earlier.
Firesign’s tenure at Columbia coincides with a period of massive change in technology and in recording practices, and listening to the records in order can stand in for a history of those changes. Waiting for the Electrician is recorded on 4-track machines, just like Sgt. Pepper was; In the Next World You’re On Your Own is recorded on 24 tracks at the Burbank Studios with the guy who had just engineered Harry Nilsson’s Pussy Cats.
Ossman stressed that Firesign was able to do something different every time they went in to record, and that they used whatever new device or technique as inspiration for what they were going to write. At the same time, though, they were also learning the radio techniques of the 1930s and ’40s and were excited to discover that Columbia Square still had all the old RCA ribbon microphones which were useful for the kind of spatial effects that are so much a part of the Firesign albums. Ossman talked about “working the mic” as if it was a kind of instrument. All of which is to say that they were swimming in the same water as the pop groups of the time, and apparently doing something quite different. But focusing on Firesign also made me realize the way so many pop acts – the Beatles and many others – were using the recording studio in theatrical ways, like the nonsense in Yellow Submarine and many other places.
RU: I’m glad you brought up media archaeology. Nearly all the Firesign albums are utterly immersed in media, particularly the media that were active during their time. One of the ideas that I believe is contained in your book is that a medium isn’t just the radio, or TV, or record player, and the content that’s available through it – but it’s also the humans who participate in it, even just as consumers. Also, there was a lot of Marshall McLuhan going around during the ’60s and ’70s. What would you say about how Firesign’s work reflects, intentionally or not, any theories of media, and then, specifically, how much did McLuhan influence their work?
JB: Yes, I’m borrowing that idea from Jonathan Sterne, someone who has really charted a new path in thinking about technologies of sound. His first book The Audible Past is about 19th century technologies like the stethoscope, while his more recent stuff is about contemporary things like the mp3 and machine listening.
One point he makes in The Audible Past is that especially at the moment of a technology’s invention, there are many ways things might go. There’s no inherent reason that the technology underpinning radio meant that it should be mainly used for one-way one-to-many broadcasting. What made that become the common sense understanding of ‘radio’ as a medium had to do with other decisions that were made socially – people who invested in transmitters and users who bought radios and listened.
Sterne is inspired in this approach by a scholar named Raymond Williams, who is someone that I am a gigantic fan of as well. Among many, many other things, Williams wrote an early study of television that is exactly contemporary with the Firesign Theatre, which was an incredibly useful coincidence. It even includes a famous description of falling asleep by the TV, just like George Tirebiter!
Both Sterne and Williams are quite critical of Marshall McLuhan, who famously was a ‘determinist’ – his idea was that particular forms of media shape particular kinds of consciousness, whether we know it (or like it) or not, i.e. they unilaterally change what it means to be human.
But Sterne and Williams both, and Sterne in particular, appreciate the Very Big Questions that McLuhan asked (so do I), and those questions would have inspired the Firesign Theatre as well.
Whether they read McLuhan carefully or not, he was completely inescapable as a public intellectual in the ’60s and ’70s, and his ideas and mantras – at least in reduced form – were widely known to all. And by the mid-70s, McLuhan apparently knew them! According to Proctor, McLuhan summoned him and Peter Bergman to his chambers at the University of Toronto after they played a show sometime in the 1970s and gave them exploding cigars – and he takes just as much pride in that as he did in Steve Jobs’ admiration of Bozos (and who wouldn’t?).
The way Firesign would depict a broadcast on a car radio, which is a scene in a movie, that is being watched on a television, on the LP album you’re listening to is without doubt a riff on McLuhan’s slogan “the content of a medium is always another medium.” But side one of Waiting for the Electrician ends with 8 million hardbound copies of Naked Lunch being dropped on Nigeria from a B-29 bomber called the Enola McLuhan, and that seems like a devastatingly skeptical critique of McLuhan’s techno-utopian Global Village.
RU: Let’s close out with some politics. Somehow despite being both a New Left Yippie and a Firesign fanatic back in the day I was surprised by their history of, and connection to, political activism and saw them as observers who were laughing at it all (and there was plenty of absurdity to laugh at). On the other hand, as also covered in your book, they were actually excoriated by some (in the early 1970s) for not being enough down for the revolution. Firstly, I wonder how anybody who wasn’t there during that period could even make sense of any of it. And then, how does Firesign’s politics, both left and ambiguous, show up in their albums?
JB: I’m glad that the book rings true to a New Left Yippie who was there. As to your first question: to piece together the context, I had to consult a huge range of sources outside of the albums: histories of the period, of course, but also lots of primary sources like newspapers, the rock press and independent press, fanzines, and plenty of interviews. And I met other people who were working on projects that were adjacent to my project and we shared work as we were writing; my colleague Claudia Verhoeven is writing a cultural history of the Manson murders, and the anthropologist Brian D. Haley just published his fantastic book Hopis and the Counterculture, which has a chapter on Firesign in it.
The question of the group’s politics – both on the albums and in terms of their internal dynamics – is very complicated. I do think they were skeptical about the Yippies’, “you can’t be a revolutionary without a television set” approach (which was very McLuhanite), because they knew that the powerful people would always want to control the media, too.
And more broadly, there were four people in the group, and they did not absolutely agree on everything, and things changed among them over time. But it is obviously meaningful that they all came together on KPFK, which then and now is a station on the left-wing Pacifica network, which meant that they both worked and were heard in that context from the very beginning.
I would also point out that it’s possible to make jokes about things with which you are in sympathy. So one place you can see that is near the end of the first side of How Can You Be in Two Places at Once, which was written and recorded weeks after the 1968 Chicago DNC. Lilly Lamont’s USO-style singalong “We’re Bringing the War Back Home” is a travesty of the SDS slogan “Bring the War Home,” which was coined for the Chicago protests. But that whole album is very obviously, and in so many different ways, opposed to the Vietnam War, so it’s hard to see how the song could be seen to be mocking the antiwar activists – even if there were some revolutionaries who thought they should have been more overtly militant. Firesign’s humor is in general not angry or indignant – as with Dick Gregory or Lenny Bruce – and is more about finding a place to make connections, ask questions, and even express anxiety, as the Creem reviewers all understood. For instance, Dwarf is very much about Kent State, but to get there on the album you have to pass through televangelism.
Credit: Tesfu Assefa
RU: In Pat Thomas’s Jerry Rubin biography, he notes a clear timeline in which 1973 was the year when every participant with half a brain knew that the new left counterculture revolution was not going to succeed politically. And it seems like there might be a similar clear distinction between the Firesign albums before and after that year. I perceive a sort of certainty of purpose pre-1973 that turns more drifty in the later albums.
JB: That’s generally true. Peter Bergman once said that they lost their audience after Vietnam and that they began to lose focus as a result. But I see it a little differently. First, it’s just hard to keep a band working together with that intensity that long. The Beatles didn’t break up because the counterculture failed, for instance, though their breakup was probably seen as a sign of it. And on the other hand, Firesign could be seen as mourning the promise of the revolutionary movement as early as Dwarf in 1970. And by the way, I think their last Columbia record, In the Next World You’re On Your Own (1975) is as good as anything they ever did, and is very political.
RU: Ok here’s a tough final one. You write often about Firesign performing in “blackvoice” (or Asian voice etc.) Could Firesign Theatre exist today? Would they have to include all diverse categories of persons in their group and wouldn’t that also be problematic? So what I often ask myself, and now I ask you… does this situation represent a positive evolution or are we losing our ability to process or allow for nuance and context?
JB: A huge and important question, and I think about it often. The spirit of your question, I think, is that these were four educated middle-class white guys who nevertheless wanted to represent all of society, including racism and segregation, which they were opposed to but decided they could never make the primary theme of their work. It’s more complicated than that, and for good reasons their blackvoice would not be viable today, but I think it is generally true.
My short answer is to say yes of course there could be a Firesign Theatre today, but it would have to be different. Here’s a utopian (but also problematic) thought experiment: what about a multiracial group that also included women, and that they all had the liberty to speak both in their own identities and in those of others? That could create a space to really explore the conflicts and contradictions of social life, but also provide a utopian image of how things could be otherwise.
I actually think that around 1972, Firesign were setting themselves up to experiment, however unconsciously, in that direction as two of their wives (Tiny Ossman and Annalee Austin) were becoming increasingly present on the albums, and in The Martian Space Party performance, and there is at least one photo shoot where they appear to have expanded into a six-member group (albeit still entirely white).
I was thinking about this fun counterfactual when I was watching Peter Jackson’s Get Back documentary a couple of years ago: what if The Beatles had invited Billy Preston and Yoko Ono into the group as full members – going further into Yoko’s avant-gardism and into Billy Preston’s soul and R&B chops, while having Asian, Black, and queer voices in the band?
The Firesign Theatre identified closely from the very beginning with The Beatles – a band that was bigger than the sum of its parts, but composed of four distinct personalities, all of whom were important and (crucially) who all really loved each other.
Could there be a comedy group that looked more like Sly and the Family Stone or Prince and the Revolution, but with the democratic give-and-take of the Beatles? I mean, I know that George began to feel constrained, and Ringo wasn’t really a songwriter, etc. But you see my point: yes it would be possible, and it’s something that it is very much worth wanting. I think the real question is whether there would be an audience that would have the attention to listen to that work again and again – I would hope that there is.
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.
Are AI models starting to forget what makes them so impressively human-like? Researchers warn of an insidious issue dubbed “model collapse” – a process where, over successive generations of training on model-generated data, AI systems may drift further from their original training data, potentially degrading performance and reliability.
Introduction
The advent of Large Language Models (LLMs) and generative models like GPT and Stable Diffusion has reshaped AI and content creation. From chatbots to advanced image synthesis, these systems demonstrate remarkable capabilities. However, a fundamental issue looms: training new models on data generated by earlier models increases the risk of “model collapse.” This degenerative process raises concerns about the sustainability and reliability of AI models over time.
Mechanism of Model Collapse
The term “model collapse” describes a degenerative process wherein a generative model gradually loses its ability to represent the true data distribution—particularly the “tails” or outer edges of this data. This issue is rooted in two errors.
First, statistical approximation error occurs when models rely increasingly on generated rather than genuine data. Over multiple generations, critical information from the original dataset becomes less represented, leading to a warped view of the data landscape.
A second factor, functional approximation error, emerges when the model’s architecture fails to capture the original data’s intricacies. Even though neural networks can theoretically model complex functions, simplified architectures often lead to overconfidence in the AI’s outputs. Together, these errors create a feedback loop that gradually shifts each generation away from the initial data distribution.
Effects Across Models
To better understand model collapse, researchers examined its effects on various generative models, including Gaussian Mixture Models (GMMs) and Variational Autoencoders (VAEs).
Tests using GMMs revealed that while these models initially performed well, their ability to represent the original data degraded significantly by the 2,000th generation of recursive training. This loss of variance led to a significant misrepresentation of the initial distribution.
VAEs, which generate data from latent variables, exhibited even more pronounced effects. By the 20th generation, the model output had converged into an unimodal form, missing out on the original dataset’s diverse characteristics. The disappearance of “tails” suggests a loss of data nuance.
Implications for Large Language Models
While concerning for GMMs and VAEs, model collapse is even more worrisome for LLMs like GPT, BERT, and RoBERTa, which rely on extensive corpora for pre-training. In an experiment involving the OPT-125m language model fine-tuned on the Wikitext-2 corpus, researchers observed performance declines within just five generations when no original data was retained. Perplexity scores, measuring the model’s understanding, increased from 34 to over 50, indicating a significant drop in task accuracy. When 10% of the original data was preserved, performance remained stable across 10 generations, highlighting a potential countermeasure.
Credit: Tesfu Assefa
Mitigation Strategies
To address this degenerative phenomenon, researchers propose several strategies. Maintaining a subset of the original dataset across generations has proven highly effective. Just 10% of genuine data appeared to significantly slow collapse, maintaining accuracy and stability.
Another approach involves improving data sampling techniques during generation. Using methods like importance sampling or resampling strategies helps retain the original data’s diversity and richness.
Enhanced regularization techniques during training can prevent models from overfitting on generated data, thus reducing early collapse. These measures help models maintain balanced task comprehension even when trained on generated datasets.
Conclusion
Model collapse poses a significant risk to the future of generative AI, challenging their long-term accuracy and reliability. Addressing this requires strategies like retaining real data, refining sampling techniques, and implementing effective regularization. Focused research and mitigation can help AI models preserve their adaptability and effectiveness, ensuring they remain valuable tools for the future.
Reference
Shumailov Ilia, Zakhar Shumaylov, Yiren Zhao, Yarin Gal, Nicolas Papernot, and Ross Anderson. “The Curse of Recursion: Training on Generated Data Makes Models Forget.” arXiv.org, May 27, 2023. https://arxiv.org/abs/2305.17493.
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.
2024 is ending explosively for cryptocurrency markets after a busy Q4. Decentralized financial infrastructure has found concrete value in various sectors, beyond just speculative value. This article explores the most significant use-cases driving this adoption, and looks at how crypto is reshaping the industries it touches.
DePIN are networks that decentralize real-world infrastructure – including communications, data storage, and energy infrastructure. This is a powerful use-case for blockchain technology, with the potential to onboard millions of new users to the crypto space. DePIN
Connectivity protocols are disrupting traditional telecom infrastructure by crowdsourcing the capital needed to provide internet service.
Sensor networks such as Hivemapper capture real-world data
Decentralized data storage and compute protocols are projected to reach a market size of $128 billion by 2028.
DePIN projects use token incentives and on-chain governance to address longstanding challenges in infrastructure development. By allowing users to contribute resources and earn rewards, these networks can significantly reduce costs and increase efficiency compared to centralized alternatives.
Helium: Revolutionizing Wireless Networks
Helium stands out as a prime example of DePIN’s potential. It is a decentralized wireless network providing 5G coverage across North America, boasting impressive statistics:
Over 113,000 users and 18,000 hotspots
Coverage spanning the continental USA, plus large portions of Canada and Mexico
More than 800,000 total subscribers benefiting from its coverage
Helium’s success lies in its innovative approach to network expansion. By incentivizing people to set up hotspots, the network grows organically while rewarding participants with cryptocurrency. This model has proven so effective that even major telecom players are taking notice and exploring partnerships.
Stablecoins Bring Safety In Volatile Markets
Stablecoins have become a cornerstone of the digital economy, with a total supply exceeding $68 billion. These digital assets pegged to national currencies (usually the US dollar) offer a lifeline for preserving purchasing power in countries grappling with hyperinflation.
Peer-to-peer transfer volumes for stablecoins have reached record highs, with hundreds of billions of dollars transacted monthly. This surge in usage has caught the attention of financial giants like Visa and Mastercard, who are now exploring stablecoin payment integration.
The impact of stablecoins extends beyond individual users. Businesses operating in volatile economies are increasingly turning to stablecoins to manage their cash flows and hedge against the risk of currency fluctuation. This adoption is driving innovation in cross-border payments and remittances – areas where traditional financial systems often fall short.
Tokenized Real-World Assets (RWAs)
The market cap of tokenized real-world assets has grown from a $270 million market to nearly $6 billion in just two years. This trend is bridging the gap between traditional finance and the crypto world, offering unprecedented liquidity and accessibility to previously illiquid assets.
Major financial institutions like BlackRock have entered this space, launching their own RWA funds on-chain. Meanwhile, crypto-native projects like MakerDAO and Ando Finance continue to innovate, with Ando Finance seeing its deposits grow from $190 million to over $600 million since early 2024.
The benefits of tokenized RWAs include:
Fractional ownership of high-value assets
Increased liquidity for traditionally illiquid assets
24/7 trading capabilities
Reduced intermediaries and associated costs
Programmable assets with automated compliance and dividend distribution
With more robust regulation on the cards during the new Trump presidency, we can expect to see more traditional assets being tokenized and traded on blockchain platforms – such as real estate, fine art, and intellectual property rights.
Oracles Connect Smart Contracts to the Real World
Blockchain oracles like Chainlink and Pyth play a crucial role in connecting smart contracts to external data sources and systems. Using oracles, hybrid smart contracts can be created that react to real-world events and interoperate with traditional systems.
Oracles solve the critical problem of how smart contracts can access and verify external information. For example, imagine a smart contract for betting on a football match: the oracle feeds the contract information on who has won the match, allowing the contract to distribute the winnings.
Oracles are essential for decentralized finance (DeFi) applications. Chainlink, a leading oracle network, has enabled over $9 trillion in transaction value. Major financial institutions including Swift and DTCC are collaborating with oracle providers to integrate blockchain technology into their operations.
The importance of oracles extends beyond simple data feeds. They’re now being used to:
Trigger insurance payouts based on real-world events
Execute cross-chain transactions
Provide verifiable randomness for gaming and other applications
Enable privacy-preserving computations
Messaging Apps and Crypto Integration
Telegram’s TON network exemplifies the potential for mainstream crypto adoption through messaging apps. With activated wallets soaring from 760,000 to 15.6 million in a year, TON demonstrates the power of integrating cryptocurrency into widely-used platforms.
The network focuses on mobile gaming, giving developers tools to easily incorporate crypto features. This approach introduces millions of casual users to cryptocurrency without requiring deep technical knowledge.
Key developments in the TON ecosystem include:
Daily active wallets exceeding 800,000
Monthly active wallets on track to surpass 6 million
Popular mobile games launching tokens on the TON network
Integration of TON with Telegram’s vast user base of nearly 1 billion
While the rapid growth of TON is promising, it’s not without challenges. There have been network outages, and the arrest of Telegram’s founder has created shockwaves – raising concerns about Telegram’s centralization and reliability.
Credit: Tesfu Assefa
Quantum-Resistant Blockchains: Preparing for the Future
As quantum computing advances, the need for quantum-resistant blockchains has become more pressing. 2024 has seen significant progress in this area, with several projects launching quantum-safe networks.
IOTA, a distributed ledger designed for the Internet of Things (IoT), has successfully implemented quantum-resistant signatures in its mainnet, making it one of the first major blockchain projects to achieve this milestone.
As we look ahead to 2025, these trends are set to accelerate and evolve. The Web3 landscape is poised for even greater integration with AI, more widespread adoption of tokenized assets, and continued innovation in privacy and security technologies. The metaverse economy is expected to grow exponentially, potentially reaching a market cap of $1 trillion by the end of 2025.
Conclusion
Cryptocurrency is moving beyond speculation and finding its footing in real-world applications. Crypto is solving tangible problems across various sectors: revolutionizing infrastructure development with DePIN projects like Helium, enhancing financial stability through stablecoins, and enabling data-driven decision-making via prediction markets.
The future of the web is decentralized, intelligent, and more interconnected than ever before, and 2024 has laid the groundwork for this exciting new era.
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.
A few days ago we reported that Philip Rosedale, the legendary founder of the Virtual Reality (VR) world Second Life, has returned as Chief Technology Officer (CTO) of Second Life’s parent company Linden Lab.
“We’re now in a unique position to define the future of virtual worlds, and Philip is returning to help myself and the exec team achieve that goal,” says Linden Lab CEO Brad Oberwager.
“I started Second Life in 1999,” adds Rosedale, “a decade before cloud computing and two decades before AI. We were early, but the success of Second Life to this day shows that we were not wrong. Virtual worlds will play an increasingly important role in the future of human culture, and I’m coming back to help make that happen in a way that has the most positive impact for the largest number of people.”
The term ‘metaverse’, which is often used for large VR worlds, comes from Neal Stephenson’s science fiction novel Snow Crash (1992). Au points out that the metaverse was effectively designed by Stephenson in the novel, that Stephenson’s insights are still valid (but often ignored), and that Stephenson’s original metaverse is still the goal that the VR industry is striving to reach.
In the last chapter of his book, titled ‘Metaverse Lessons for the Next 30 Years’, Au offers important advice to the metaverse industry, including lessons from “The Fall of Second Life”. The first lesson is that the user community must come before everything else. I believe the industry should listen to Au carefully on this.
The fact that Second Life has faded out of public consciousness at the end of the 2000s and no next-generation metaverse has emerged to replace it could indicate that people can do without VR. But perhaps VR is just hard to do well, and nobody has figured out yet how to do it well.
“VR is hard to do well even in a lab, and there’s still a lot to learn about how to make great VR products,” says VR pioneer Jaron Lanier in Dawn of the New Everything: Encounters with Reality and Virtual Reality (2017). “Be patient… Just because it takes a while to figure a technology out, that doesn’t mean the world has rejected it… Maybe VR will be huge, huge, huge…”
It’s all about people
A couple of days after the announcement of Rosedale’s return to Second Life, Au has published a long interview with Rosedale. The two raise interesting points that could indicate the way to VR done right.
Au insists that “a virtual world is all about people.”
I think he is right. VR technology is very cool, but at the end of the day what keeps users coming back to a VR world is real (not virtual, but real) interaction with real people.
Rosedale also agrees. One thing that makes you feel that Second Life is a real world is that, when “talking to a real person in Second Life, is they’re obviously a real person who’s perceiving Second Life with you in a way that is complete and rich, so you can do things together,” he says.
Artificial Intelligence in Second Life
What role should Artificial Intelligence (AI) play in the VR metaverse?
Rosedale is not too bullish on AI technology. The proper role of AI in Second Life is “to be a matchmaker between real people,” he says. “Having the AI be a sex bot, but you fall in love with it forever, does not feel like a good idea to me.”
However, Rosedale hints at the possibility to use a virtual world like Second Life as training ground for AI. The fact that everything in Second Life is labeled and carries metadata could help AI bots understand the word of Second Life faster and easier than AI bots in the real world.
This reminds me of the delicious science fiction novella The Lifecycle of Software Objects, by Ted Chiang, where intelligent and perhaps fully conscious AI bots live in a fictional metaverse called Data Earth before moving to robotic bodies in our world. The idea that comes to mind is to take a large language model (LLM), couple it to a virtual body in a realistic part of Second Life, and let the LLM lose to explore and learn how things look like and behave.
Philip Rosedale speaks at the Second Life Community Roundtable on November 1, 2024 (Credit: Giulio Prisco)
I’m an old hand at Second Life. I used to be a metaverse developer in Second Life and other platforms, often organized Second Life events about the future, emerging technologies, futuristic philosophies, the Singularity, and all that. Many people used to attend, and the atmosphere was positively electrifying. But before Rosedale’s recent talk, I had not been in Second Life for years!
There weren’t many differences to see since the last time I’d been there. This suggests to me that the technical development of Second Life has been stagnating, and Linden Lab needs Philip to revive it. In fact, many technical questions from the audience (e.g. about performance, lag, user interface, new scripting languages) are old questions that I’ve seen asked many times, but not answered.
I hope Philip Rosedale’s return to Second Life will spark a renaissance of Second Life as a real place for real people (and our AI mind children – I’m much more bullish than Rosedale on AI) to talk about big things and big questions, and bring that electric atmosphere back.
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.











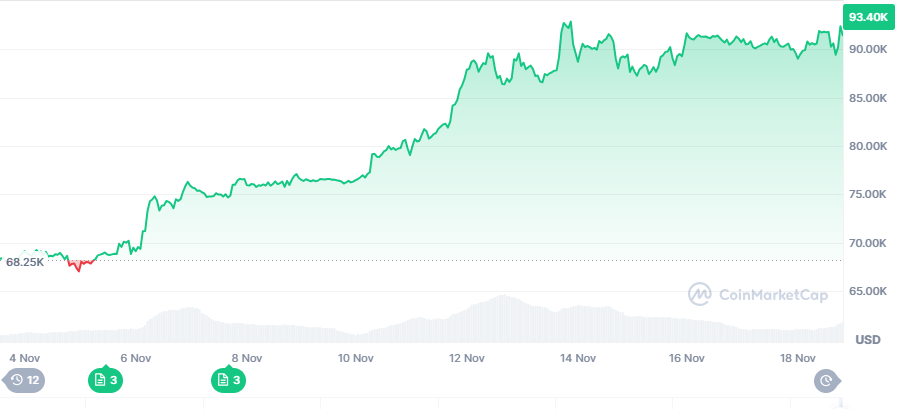
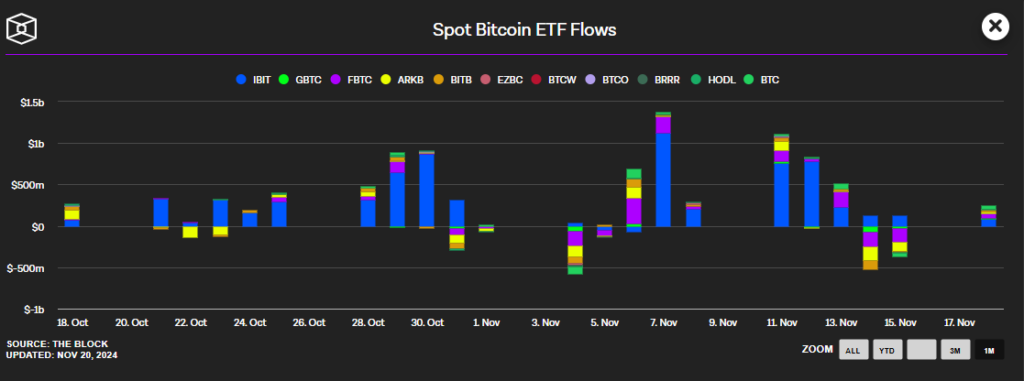
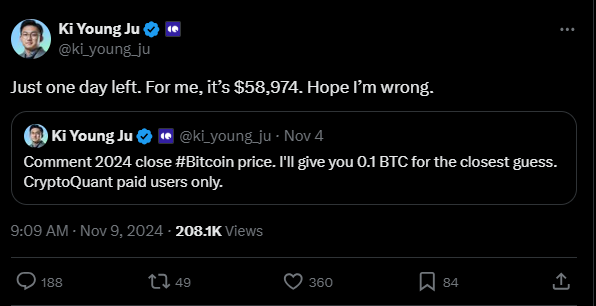














.png)

.png)


.png)