Big money – smart, dumb, and everything in between – is coming to Web3. The increasingly likely prospect of a spot Bitcoin ETF is a milestone in crypto’s final acceptance by the mainstream. Adoption is coming: a word that fuels the dreams of bedroom miners who have for years waited for the wider world to catch on to crypto’s promise.
For many, adoption is something to be fervently wished for, the final ratification of crypto’s potential. For others, it spells the end of crypto’s status as an alternative asset class, a death knell for the underground financial resistance that crypto historically represented.
Bitcoin: Always an Alternative
Bitcoin’s creation was predicated on being an alternative to big money. The first block in the entire chain contains a cryptic jab at central banks: “The Times 03/Jan/2009 Chancellor on brink of second bailout for banks.” The most recent bull run, although powered by stimulus checks and everyone having too much time on their hands, was built on the belief that Bitcoin and cryptocurrencies can be a store of value – a trustless hedge against the rampant money printing of central banks with levers operated by shady politicos funded by corporations keen to see their share price rise. I’m not suggesting this narrative is true or false, but it certainly fed the meteoric rise in crypto asset prices in 2020 and 2021.
Fifteen years of 0% interest and quantitative easing have made everyone’s money mean less (and everyone’s ownership mean more). Crypto represented a resistance to this. Almost since its inception, crypto has been seen as a chance for the little guy to make it, for Millenials and Gen Z (who are far more likely to be invested in crypto) to overturn the Boomers’ hoarded wealth and have a chance at replicating the stable, successful accumulation of their forebears, for those operating outside the standard rails of society to hold, store, and gain wealth. To let les miserables get involved in playing the game.
What ETFs Will Do To Crypto
The Securities and Exchange Commission (SEC) former chair’s statement that a spot Bitcoin ETF is ‘inevitable’ is, to some, a cause for sadness as well as celebration. Make no mistake, a Bitcoin ETF will open the doors for institutional money to get into crypto. ETFs (exchange traded funds) are a gold standard for institutional investors. Let’s talk about the positives first.
An ETF is a regulated mutual fund, professionally managed, that pays out dividends to shareholders based on its basket of securities. Unlike mutual funds, ETFs can be listed on a stock exchange, and are freely fungible for other cash or stocks. Most crucially, ETFs are an investment instrument that would not break fiduciary responsibility for pension funds, hedge funds, public businesses, or any other large institution who wants to hold crypto on their balance sheet and be exposed to crypto’s upside.
Upsides could be enormous if, as expected upon ETF ratification, institutions begin piling into crypto, as a method of diversifying their massive portfolios. The ‘$15 Trillion earthquake’ has the potential to send crypto not just to the moon, but to Oort Cloud. What about this is sad at all? Won’t everyone benefit? Well, yes, those who hold crypto will financially benefit – a lot.
Credit: Tesfu Assefa
A Requiem For Web3
The sadness is perhaps more philosophical, less practical. They worry that on the grandest scale, the cat will be out of the bag. Old money – banks, institutions, pension funds, Wall Street – these will become the primary drivers of the crypto market once crypto ETFs go live. The fun underground culture of Discord announcement parties, acid-mediated 125× Binance longs, Pepe-meme punts on shitcoins, and community-led price action with groundswell social campaigning will be completely swamped by the ticker tape tapestry of Bloomberg-reading MBA suits pumping tsunamis of money around the market or letting an algorithm HFT for them. Crypto will no longer be an alternative asset class, but just an asset class: regulated, controlled, and milled by the ancient financial machine that plunders all our tomorrows.
A New Financial System For Everyone
The hope, of course, is that crypto actually presents the opportunity for a fundamental change to the old systems. Ethereum (itself the subject of an ETF application) has, through its programmable smart contracts, the potential to act as an alternative financial substrate – one that is decentralised, trustless, and censorship resistant. One that levels the playing field and lets everyone ‘play up, play up, and play the game.’ It won’t just be Old Money buying into these assets, but these assets will form a new foundation on which the financial world can thrive – one that is permissionless and (at least nominally) fair, governed by smart contracts and regulated by all. Old Money might be entering the new game, but at least this time everyone gets a chance to join in.
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.
Ethereum is drawing closer to another upgrade in Q4 of 2023 which will have a transformative effect on its whole ecosystem.
The Cancun-Deneb (Or Dencun) upgrade will feature the important EIP-4844 protocol, designed to boost Ethereum’s competitiveness and the performance of its slew of layer-2 scaling chains.
Also known as Proto-Danksharding, in honor of two of its researchers, Proto Lambda and Dankrad Feist, EIP-4844 is a part of the broader Ethereum Improvement Proposal protocol, which allows for the introduction of new features to its network.
It was conceived by Ethereum co-founder Vitalik Buterin (who recently shared his vision of three transitions needed to scale the network) along with a team of developers with the primary objective of lowering gas fees, particularly for layer-2 rollup solutions such as Optimism, Arbitrum, and zkSync Era, without compromising on the network’s decentralization.
But what exactly is EIP-4844, and why is it so crucial for the future of Ethereum and the development of Web3? Let’s take a closer look.
Sharding vs Danksharding vs Proto-danksharding
To fully grasp the impact of EIP-4844, it’s essential to understand what sharding and danksharding are.
Sharding is a long-time end goal for Ethereum that dates back all the way to the 2018 Casper roadmap. It involves partitioning a blockchain network into smaller units, known as ‘shards,’ to improve transaction throughput and reduce network congestion. To get there though, some preliminary steps are needed.
Danksharding is a new architectural approach that relies on data blobs to scale the Ethereum blockchain. It’s a complex process that will be implemented in phases, with EIP-4844 serving as the initial step.
In the words of Vitalik Buterin, proto-danksharding provides the “scaffolding” for future sharding upgrades. It implements most of the logic required for danksharding without actually initiating sharding.
What is EIP-4844?
In short, EIP-4844, or Ethereum Improvement Proposal 4844, aims to enhance scalability by exponentially lowering gas fees on layer-2 rollups through innovative blob-carrying transactions. Yes, you read that correctly.
Interestingly, EIP-4844 is a temporary fix – until sharding is fully supported on Ethereum and solves scaling. EIP-4844 introduces a new way to split transaction information, such as verification rules and transaction formats, without the need for full sharding.
What Are Shard Blob Transactions?
One of the most groundbreaking features of EIP-4844 is the introduction of a new transaction type known as “blob transactions”. These transactions allow for data blobs to be temporarily stored in the beacon node.
Blobs are essentially data packages around 125kB in size. Compared to regular transactions, blob transactions are cheaper to execute, but they are not accessible to the Ethereum Virtual Machine (EVM).
Scalability and Data Bandwidth
The data bandwidth for a slot in proto-danksharding is capped at 1 MB, a significant reduction from the previous 16 MB, which is a massive change aimed at alleviating Ethereum’s well-known scalability issues. The EIP-4844 update does not affect gas usage for standard Ethereum transactions.
Credit: Tesfu Assefa
Why is EIP-4844 A Game-Changer For Ethereum and L2s?
High gas fees have been a significant barrier to Ethereum’s mass adoption, as any DeFi user will tell you. People who tried to trade on Uniswap or flip NFTs during 2021s wild bull run (with its record-high ETH gas fees) can attest that some transactions cost hundreds of dollars in fees. Network fees on any blockchain can skyrocket when on-chain activity increases, making the network expensive and inaccessible for many users.
The advent of layer-2 side chains that use optimistic and zero-knowledge (ZK) rollup technology to compile transaction batches has done a lot to alleviate the pressure on Ethereum’s mainnet. The Optimism chain was presented in March 2022 by Proto Lambda with claims that it could potentially lower L2 transactions by up to 100x. But as things stand, when network usage and congestion soar, transactions still get unacceptably pricey.
EIP-4844 aims to be a game-changer by significantly reducing transaction fees and increasing throughput. Yet it’s only a stop-gap measure until the full implementation of data sharding, which would add around 16 MB per block of dedicated data space for rollups to use.
The Future of Ethereum and Rollups
With so much building happening on Ethereum due to its stable infrastructure and proven security, it’s no surprise that Buterin believes that the future of scaling the world’s first smart contract network will revolve around these rollup chains. Proto-danksharding is a pivotal stop on this roadmap.
Post-implementation, users can expect faster transactions and lower fees, which will enhance Ethereum’s competitiveness in the blockchain sector, and help it to stretch its massive lead over rival layer-1s such as “ETH killers” like Solana, Cardano, and EVM-compatible chains such as Avalanche and BNB Smart Chain. These chains have also all been plagued with their own development setbacks from time to time.
Conclusion
EIP-4844, or Proto-Danksharding, is more than just a not-so-catchy name; it’s a pivotal upgrade that promises to address some of Ethereum’s most pressing issues. From reducing layer-2 gas fees to paving the way for full sharding, this proposal is another worthy milestone on the road to Ethereum’s final state as the world’s computer.
The scheduled rollout in Q4 2023 should hopefully go through without any major surprises, if the network’s last few upgrades are anything to go by. Sailing was rarely smooth for any update prior to 2020’s Beacon Chain fork (2019’s Constantinople fracas comes to mind), but the ones after all breezed through with flying colors, giving ETH users and developers much-needed confidence. Let’s hope the Dencun update provides more of the same.
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.
I suppose the way to get Mindplexians interested in Antero Alli – author, theater producer, experiential workshop leader and film director – is through his ties to Timothy Leary and Robert Anton Wilson starting back in the 1980s, where that pair were advocating transhumanist slogans like Space Migration, Intelligence Increase, Life Extension.
But the reality is that Alli has carved his own path as a writer, a thinker and director. And as he slowly exits corporeality, it’s his film oeuvre that most fascinates me.
I recently spent a day watching several of his films and it struck me that I was looking at part of an entire body of work that has been largely neglected by those writing about and advocating for indie films. Alli’s films may be about to be discovered. They certainly deserve substantial notice. There are hours of enjoyment and intrigue awaiting viewers.
And while enough of his films enclose neo-tech tropes like VR and AI to cause one or two commentators to toss out the buzzword “cyberpunk,” these are all ultimately human stories leaning on depth psychology, Jungian symbolism, dreams and real experience.
In the preview for his latest film (and most likely his last) ‘Blue Fire’, Alli highlights the Singularity.
The central protagonist is an underground singularity-obsessed AI hacker. Scenes show male computer-freak social awkwardness, unrequited male obsession with a woman and a bad Salvia Divinorum trip (been there). Ultimately ‘Blue Fire’ is not a film about AI or the personalities of underground hacker archetypes. It’s a film about human connections — connections made but mostly connections missed.
I interviewed Antero Alli by email.
R.U. Sirius: Since Mindplex readers probably aren’t familiar with your work, what would you say is the theme or project or search that runs through all of your work that includes books, theater, experiential workshops and film, including the most recent one we’re discussing today?
Antero Alli: The silver thread running through most everything I’ve put out to the public since 1975 – my books, films, theatre works, Paratheatrical experiments – reflects my ongoing fascination with how our diurnal earth-based realities are impacted in meaningful ways by our nocturnal dreams and related astral or out-of-body events. I have felt compelled to share these visions through the Art of words, images, and human relations. All this obsession started back in 1975 when I endured a spontaneous out-of-body experience at the age of 23. I say endured since the experience itself was traumatic and a massive shock to my concept of identity. I was no longer able, in all honesty, to identify as a physical body after being shown more truth when seeing and knowing myself as a light body, an electric body, cased within the physical body. No drugs were involved. The only condition I can relate it to was exhaustion from an intense theatre rehearsal that evening. All my films are oneiric docufictions, where real life experiences are camouflaged and spun by my feral poetic imagination.
Credit: Antero Alli
RUS: We met when we were both working and playing with the ideas of Timothy Leary and Robert Anton Wilson. To the extent that their ideas are likely of interest to the mostly technophile readers of Mindplex, they would be attracted to the technotopian ideas they advocated like SMI²LE and evolutionary brain circuits as opened by drugs and technology, and then Leary’s later advocacy of cyberpunk and the digital revolution. How do you see your own work in relationship to these tropes?
AA: My contribution to the legacies of Timothy Leary and Robert Anton Wilson is demonstrated through my thirty-year era of working with The Eight-Circuit Brain model. This started in 1985 with the publication of my first 8-circuit book, ‘Angel Tech’, updated and expanded in 2009 with ‘The Eight Circuit Brain: Navigational Strategies for the Energetic Body’. (Both books are still in print at The Original Falcon Press.) My approach is somatic and experience-oriented, rather than theoretical or philosophical. I relate the eight-circuit model as a diagnostic tool to track and identify multiple states of consciousness and eight functions of intelligence that can be accessed as direct experience through ritual, meditation, and trigger tasks. This embodiment bias sets my circuit work apart from Leary’s more theoretical approach and Wilson’s use of multiple systems theory to expand the eight-circuit playing field. Between the three of us, I think we cover the bases pretty well.
RUS: The dramatic persona in Blue Fire is an underground AI hacker… seemingly a singularitarian. How did you conceive of this character? Was he based on someone or a composite or a pure imagining?
AA: The AI-coder Sam, played by Bryan Smith, was inspired in part by the actor — a singular personality with a dynamic physical sensibility and this very pure kind of cerebral charisma, a complexity that I felt could brilliantly serve the film. I was also intrigued and inspired by the subculture of coders that I discovered talking with a few of my friends, AI freaks and serious hackers, who shall remain anonymous.
RUS:Without giving up too much of the plot, the other protagonists are a relatively normal nice seemingly-liberal couple. The dynamic between could be read as a contrast between neurotypicals and neuro-atypicals, In this case the atypical doesn’t do very well but is perhaps a catalyst for putting the typicals through some changes. Would you read it that way?
AA: The so-called typical couple are not lovers or married or in any kind of romantic involvement; nowhere in their dialogue mentions or indicates that. What is clear is that she is a student in the college-level Psychology 101 that he teaches. They form a bond over their shared interest in dreams, a bond that deepens into a troubling mentorship. All three characters act as catalysts for each other in different ways. Much of this starts in their nocturnal dreams and how their daily discourse is impacted by these dreams. This daytime-dreamtime continuum continues as a thread throughout most of my films.
RUS: Again, not giving up too much, the hacker dude smokes some salvia divinorum… and based on my own experiences, you got that right in the sense that it’s often an uncomfortable high. I’ve referred to it as “naggy”. People who want to be happy about being in disembodied cyberspace should probably make ketamine their drug of choice (I’m just chattering here but welcome you chattering back) or even LSD rather than a plant. McKenna used to believe that with plant psychedelics there’s someone or something in there… kind of another mind with something to impart to the imbiber. Any thoughts on this or thoughts on minds other than our own here on earth and what they can teach us?
AA: I knew Sam, the A.I. coder, had a drug habit, but didn’t know at first what drug would be the most indicative of this native state in mind. What drug would he gravitate towards? What drug amplifies his compartmentalizing, highly abstract, and dissociative mindset? After smoking salvia several times, it seemed like a good fit (not for me but for Sam). By the way, I don’t make my films to school the audience or teach them anything. It would be a mistake to also view any of the characters in my films as role models, unless your Ego Ideal includes flaws, shortcomings, and repressed Shadow material. Though ‘Blue Fire’ revolves around Sam’s AI coding, this is also not a story about AI but how AI acts on Sam’s psyche. Like my other films, I explore human stories planted in extreme circumstances or situations where people face and react to realities beyond their control or comprehension.
RUS: Aside from AI, virtual reality pops up in some of your work, and the language of hacking occurs here and there. But I don’t think your work would be categorized as cyberpunk or even sci-fi. What role would you say fringe tech and science play in your films?
AA: The fringes of tech and science play a role in those films – their presence amplifies the human story or shows the viewer a new context or way of seeing how the characters interact with tech and science. This keeps me and my films honest, as I’m no techie or science nerd. My deep background in theatre and ritual (Paratheatre) has slam-dunked me into the deeper subtext of human relations and how this interacts with the transpersonal realms of archetypes and dreams.
RUS: I’m feeling a little claustrophobic making what I suspect might be your last or one of your last interviews just about Blue Fire as directed at the Mindplex audience. If you’re up to it, why don’t you hit the world with your parting shot, so to speak. A coda? A blast of wisdom? A great fuck-all? A kiss goodbye? Whatever you feel. And thanks for being you.
AA: I’m feeling a bit claustrophobic about answering your question. I get that others sometimes think of me as this fount of wisdom – which humors me to no end. I suppose whatever ‘wisdom’ has been born in me, it’s come from making many mistakes and errors of judgment that I have felt compelled to correct as soon as possible, if only because I hate the dumbdown feeling of making the same mistake more than once. This self-correction process vanquished any existing fear of making mistakes, in lieu of an excitement for making new mistakes – defining my creative approach to most everything I do as experimental. Everything starts out as an experiment to test the validity of whatever idea, plan, or theory I start with. Sometimes I’m the boss and sometimes the situation is the boss.
No fuck alls, no kisses goodbye, no regrets. I remain eternally grateful to have lived an uncommonly fulfilling life by following and realizing my dreams. At 70, this has proven a great payoff during my personal end times (I was diagnosed with a terminal disease and don’t know my departure date).
Do you want to be a paperclip? This isn’t a metaphor, rather a central thesis of Nick Bostrom’s harbinger book Superintelligence. In it, he warns of the calamity lurking behind poorly thought out boot up instructions to AI. An AI tasked with the rather innocuous goal of producing paperclips could, if left unchecked, end up turning every available mineral on earth into paperclips and, once completed, set up interstellar craft to distant worlds and begin homogenising the entire universe into convenient paper organisers.
Horrifying? Yes. Silly? Not as much as you may think. Bostrom’s thought experiment strikes directly at a core problem at the heart of machine learning. How do you appropriately set goals? How do you ensure your programming logic inexorably leads to human benefit? Our promethean efforts with AI fire is fraught with nightmare fancies, where a self-evolving, sentient machine takes its instructions a little too literally – or rewrites its failsafe out entirely. Skynet’s false solution is never too far away and – to be fair to literary thinkers, AI builders, and tech cognoscenti – we have always been conscientious of the problem, if not necessarily the solutions.
Learning Machines Require Resources
The thing is, machine learning is not easy to research. You need insane processing power, colossal datasets, and powerful logistics – all overseen by the brightest minds. The only entities with the unity of will to aggressively pursue AI research are the corporations, in particular the tech giants of Silicon Valley. Universities make pioneering efforts, but they are often funded by private as well as public grants, with their graduates served up the conveyor belt to the largest firms. In short, any advances in AI will likely come out of a corporate lab, and thus its ethical construction will be mainly undertaken in the pursuit of profit.
The potential issues are obvious. An advanced AI with access to the internet, poorly defined bounds, capital to deploy, and a single goal to advance profit for its progenitor organisation could get out of hand very quickly. A CEO, tasking it one evening, could wake up in the morning to find the AI has instigated widespread litigation against competitors and shorted bluechip stocks in their own sector at vast expense for a minor increase in balance sheet profit – that is a best case scenario. Worst case – well, you become a paperclip.
The Infinitely Destructive Pursuit of Profit
Capitalism’s relentless profit incentive has been the cause of global social traumas the world over. From environmental desecration for cheaper drinking water, to power broking with user’s data staining politics, the general ruination of public services by rentier capitalists ransacking public infrastructure and pensions for fast profit is a fact. For sure, capitalism ‘works’ as a system – in its broadest conception, and yes, it does a great job of rewarding contribution and fostering innovation. Yet we all know the flaw. That single, oppressive focus on ever increasing profit margins in every aspect of our lives eventually leads to a race to the bottom for human welfare, and hideous wealth inequality as those who own the means of production hoard more and more of the wealth. When they do, social chaos is never far behind. The way that capitalism distorts and bends from its original competition-focused improvement into a twisted game of wealth extraction is just a shadow of what would occur if an AI takes the single premise of profit and extrapolates the graph to infinity. Corporate entities may not be the proper custodians of the most powerful technologies we may ever conceive, technologies that may rewrite society to their own ends.
Credit: Tesfu Assefa
A Likely Hegemony; Eternal Inequality
This may sound like extreme sci-fi fear mongering. A tech junkie’s seance with the apocalypse. So let’s consider a more mundane case – whoever has AI has an unassailable competitive advantage that, in turn, gives them power. Bard, ChatGPT, and Bing are chatbots, but there are companies who are working on sophisticated, command and control AI technologies. AIs that can trawl CCTV databases with facial recognition. AIs that can snapshot credit and data of an individual to produce a verdict. AIs that can fight legal cases for you. AIs that can fight wars. The new means of production in a digital age, new weapons for the war in cyberspace, controlled by tech scions in glass skyscrapers.
If these AIs are all proprietary, locked in chrome vaults, then certain entities will have unique control over aspects of our society, and a direct motive to maintain their advantage. Corporate AIs without checks and balances can and will be involved in a shadow proxy war. For our data, our information, and our attention. It’s already happening now with algorithms. Wait until those algorithms can ‘think’ and ‘change’ (even if you disallow them a claim to sentience) without management’s approval. It won’t be long before one goes too far. Resources like processing power, data, and hardware will be the oil of the information age, with nation states diminished in the face of their powerful corporations. A global chaebol with unlimited reach in cyberspace. Extreme inequality entrenched for eternity.
The Need for Open-Source AI
There is an essential need, therefore, for open-source access to AI infrastructure. Right now, the open-source AI boom is built on Big Tech handouts. Innovation around AI could suffer dramatically if large companies rescind access to their models, datasets and resources. They may even be mandated too by nation states wary of rival actors stealing advances to corrupt them to nefarious ends.
Yet just as likely, they will do so afraid of losing their competitive advantage. When they do, they alone may be the architects of the future AIs that control our daily lives – with poorly calibrated incentives that lack social conscience. We’ve all seen what happens when a large system’s bureaucracy flies in the face of common sense, requiring costly and inefficient human intervention to avert. What happens when that complex system is the CEO, and its decisions are final? We’ve seen countless literary representations, from GlaDos to Neuromancer’s Wintermute to SHODAN, of corporate AIs run amok – their prestige access to the world’s data systems, the fuel for their maniacal planning. When the singularity is born, whoever is gathered around the cradle will ordain the future. Let’s all be part of the conversation.
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.
NFTs are, by now, old news. No single aspect of crypto has been more derided than the ‘million dollar jpegs’ which headlined the last crypto bullrun. Around coffee tables, bars, and Discords all over the world, snide remarks about the utter insanity of the modern market reigned supreme. To many, the idea that a duplicable image of an Ape could set you up for life was cause for bemusement, anger, and not the least bit of jealousy.
Has this modern speculative capitalism gone mad? Was it the outrageous excess of the crypto-minted tech bros’ 1% indulging themselves in the new ‘roaring 20s’ of the 21st century amid a backdrop of pandemic and war? Or was someone, somewhere, actually on to something: that the dizzying prices and speculative excess was a harbinger of a newly consecrated form of online ownership and digital demesnes that would lead to a new concept of cyberspace.
The answer, of course, is that all three are true. Though the positive narrative has, to date, almost been entirely sunk by the precipitous, and in some cases hilarious, losses that early NFT ‘investors’ suffered. All gold rushes bring charlatans, and nowhere was this more acute in the insane pell mell towards the jackpot that occurred as literally anyone with a few thousands dollars and a basic concept of programming, blockchain or otherwise, could spin up a brand new NFT collection, promising insane gains, ambitious roadmaps, and eternal friendship among the community. The barrier to entry was near-zero, and the market was hungry for every new ape collection that rolled off the bedroom CEO production line. A lot of people – mainly the young – made a lot of money.
Everyone else lost everything. Very few projects ever grew beyond the initial launch. Leaders collected the minting fees and promptly stopped working, realising perhaps innocently, perhaps not, that the roadmaps they had set out would be difficult even for Apple to execute in the timeframes spoken about. Discords turned feral as thousands of users realised a 14 year old, perfectly innocently, had sold them a few pictures of whales to test his skills with Rust, with zero plans to do anything else for the project. It was just a hobby to make a few dollars.
Credit: Tesfu Assefa
Yet even without a roadmap, communities wrote one in their heads. This was going to be the latest craze, the keys to a better virtual future where whale-owners would walk tall in the new halls of cyberspace, a chance to pay off the mortgage. How dare this 14 year old kid rob us of that future they’d already dreamed they were in. Scammer, I can doxx you! I know where you live!
How did this happen? What is it about those jpeg apes that so seized the cultural imagination? Yes, there were an incredible amount of push factors – Covid, quantitative easing, stimulus, lockdown, BTC’s massive gains creating crypto-related mania. But there must have been more – what was the pull?
First, they’re not jpegs. The picture associated with an NFT is not truly the NFT itself. An NFT is a token created (‘minted’) by a smart contract that has certain information on it (like pointing to a webhost hosting a jpeg), is completely unique (even if duplicates are made, each NFT would still a specific blockchain signature), and has an owner ascribed to it (usually the person sending tokens to the smart contract to make it execute its creation function. The NFT’s information, the transaction that created it, and the current ownership is all publicly visible, irrefutable, and benefits its blockchain’s security, making fraud impossible without breaking the network entirely.
This means that we’d finally figured out a way to record digital ownership, and thus digital items, which due to their reproducibility had very little worth, but could suddenly have a lot. It started with art, but games quickly realised they could consecrate ownership over their in-game assets to players, creating cooperative gaming experiences. Ownership of the first digital ‘printing’ of your favourite artist’s new album having kudos. The ability for vibrant secondary economies to spring up around their favourite talent as users could trade NFTs with one another, or sell them. NFTs created a whole new economy to be exploited where there was none before. And boy, was it exploited. Influencers, artists, and anyone with a following could create new engagement models using NFTs, with bespoke experiences attached. At time of writing, Cristiano Ronaldo’s instagram bio asks his 600m followers to join him on his NFT journey, and bid for NFTs in open auction for a chance to meet the man himself.
What’s wrong with a ticket though? Just tell me why an ape picture is worth millions. Well, the reason is, as with so many new technologies, is the possibilities. Bitcoin, Ethereum, Solana, Cosmos – whichever – blockchains by their nature are designed to be permanent, digitally-native operating systems for our future. An NFT bought in 2017 will keep its functionality for eternity. It can’t be erased from the blockchain, or from time.
That means that should, in the future, a new business, say, declare that the only way to buy the first release of their hot new product is by owning said NFT, it would be easy for them to borrow the operation security of the blockchain and create instant exclusive access to whatever ‘club’ of people they those at near-zero outreach cost. Membership of said clubs would be powerful, digital cartels impossible to access except through the NFT and the key it provides. Or a blockchain game grows and develops a powerful online community over a decade. The first NFTs of in-game assets would be priceless, and nothing would stop developers engineering new functionality for them over time. Only a fool would suggest that we are not becoming ever more cyberised as history advances, so why wouldn’t the first digital artefacts – the first time we can truly declare failsafe ownership of a digital asset – have value?
As alluded to, all of that is decades hence. NFTs have been mooted for use in retail, supply chains, schools but, as ever, the integrative technology to make that happen and make it useful has a long way to go. Those most in the know are too busy getting rich, or at least were, to truly focus on advancing NFTs as a useful digital technology. Now, as almost every project suffers on the wind-down from mania, perhaps it’s time to take stock of what digital ownership could truly give us. As a blaze of stimuli, images, and simulacra race past us in virtual headsets, NFTs just give us something to hold on to.
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.
There are more things in heaven and earth, Horatio, than are dreamt of in our philosophy.
More recent writers, in effect amplifying Shakespeare’s warning, have enthralled us with their depictions of numerous creatures with bewildering mental attributes. The pages of science fiction can, indeed, stretch our imagination in remarkable ways. But these narratives are easy to dismiss as being “just” science fiction.
That’s why my own narrative, in this article, circles back to an analysis that featured in my previous Mindplex article, Bursting out of confinement. The analysis in question is the famous – or should I say infamous – “Simulation Argument”. The Simulation Argument raises some disturbing possibilities about non-human intelligence. Many critics try to dismiss these possibilities – waving them away as “pseudoscience” or, again, as “just science fiction” – but they’re being overly hasty. My conclusion is that, as we collectively decide how to design next generation AI systems, we ought to carefully ponder these possibilities.
In short, what we need to contemplate is the astonishing vastness of the space of all possible minds. These minds vary in unfathomable ways not only in how they think but also in what they think about and care about.
Hamlet’s warning can be restated:
There are more types of superintelligence in mind space, Horatio, than are dreamt of in our philosophy.
By the way, don’t worry if you’ve not yet read my previous Mindplex article. Whilst these two articles add up to a larger picture, they are independent of each other.
How alien?
As I said: we humans tend to compare other intelligences to our own, human, intelligence. Therefore, we tend to expect that AI superintelligence, when it emerges, will sit on some broad spectrum that extends from the intelligence of amoebae and ants through that of mice and monkeys to that of humans and beyond.
When pushed, we may concede that AI superintelligence is likely to have some characteristics we would describe as alien.
In a simple equation, overall human intelligence (HI) might be viewed as a combination of multiple different kinds of intelligence (I1, I2, …), such as spatial intelligence, musical intelligence, mathematical intelligence, linguistic intelligence, interpersonal intelligence, and so on:
HI = I1 + I2 + … + In
In that conception, AI superintelligence (ASI) is a compound magnification (m1, m2, …) of these various capabilities, with a bit of “alien extra” (X) tacked on at the end:
ASI = m1*I1 + m2*I2 + … + mn*In + X
What’s at issue is whether the ASI is dominated by the first terms in this expression, or by the unknown X present at the end.
Whether some form of humans will thrive in a coexistence with ASI will depend on how alien that superintelligence is.
Perhaps the ASI will provide a safe, secure environment, in which we humans can carry out our human activities to our hearts’ content. Perhaps the ASI will augment us, uplift us, or even allow us to merge with it, so that we retain what we see as the best of our current human characteristics, whilst leaving behind various unfortunate hangovers from our prior evolutionary trajectory. But that all depends on factors that it’s challenging to assess:
How much “common cause” the ASI will feel toward humans
Whether any initial feeling of common cause will dissipate as the ASI self-improves
To what extent new X factors could alter considerations in ways that we have not begun to consider.
Four responses to the X possibility
Our inability to foresee the implications of unknowable new ‘X’ capabilities in ASI should make us pause for thought. That inability was what prompted author and mathematics professor Vernor Vinge to develop in 1983 his version of the notion of “Singularity”. To summarize what I covered in more detail in a previous Mindplex article, “Untangling the confusion”, Vinge predicted that a new world was about to emerge that “will pass far beyond our understanding”:
We are at the point of accelerating the evolution of intelligence itself… We will soon create intelligences greater than our own. When this happens, human history will have reached a kind of singularity, an intellectual transition as impenetrable as the knotted space-time at the center of a black hole, and the world will pass far beyond our understanding. This singularity, I believe, already haunts a number of science fiction writers. It makes realistic extrapolation to an interstellar future impossible.
Reactions to this potential unpredictability can be split into four groups of thought:
Dismissal: A denial of the possibility of ASI. Thankfully, this reaction has become much less common recently.
Fatalism: Since we cannot anticipate what surprise new ‘X’ features may be possessed by an ASI, it’s a waste of time to speculate about them or to worry about them. What will be, will be. Who are we humans to think we can subvert the next step in cosmic evolution?
Optimism: There’s no point in being overcome with doom and gloom. Let’s convince ourselves to feel lucky. Humanity has had a good run so far, and if we extrapolate that history beyond the singularity, we can hope to have an even better run in the future.
Activism: Rather than rolling the dice, we should proactively alter the environment in which new generations of AI are being developed, to reduce the risks of any surprise ‘X’ features emerging that would overwhelm our abilities to retain control.
I place myself squarely in the activist camp, and I’m happy to adopt the description of “Singularity Activist”.
To be clear, this doesn’t mean I’m blind to the potential huge upsides to beneficial ASI. It’s just that I’m aware, as well, of major risks en route to that potential future.
A journey through a complicated landscape
As an analogy, consider a journey through a complicated landscape:
Credit: David Wood (Image by Midjourney)
In this journey, we see a wonderful existential opportunity ahead – a lush valley, fertile lands, and gleaming mountain peaks soaring upward to a transcendent realm. But in front of that opportunity is a river of uncertainty, bordered by a swamp of ambiguity, perhaps occupied by hungry predators lurking in shadows.
Are there just two options?
We are intimidated by the possible dangers ahead, and decide not to travel any further
We fixate on the gleaming mountain peaks, and rush on regardless, belittling anyone who warns of piranhas, treacherous river currents, alligators, potential mud slides, and so on
Isn’t there a third option? To take the time to gain a better understanding of the lie of the land ahead. Perhaps there’s a spot, to one side, where it will be easier to cross the river. A location where a stable bridge can be built. Perhaps we could even build a helicopter that can assist us over the strongest currents…
It’s the same with the landscape of our journey towards the sustainable superabundance that could be achieved, with the assistance of advanced AI, provided we act wisely. That’s the vision of Singularity Activism.
Obstacles to Singularity Activism
The Singularity Activist outlook faces two main obstacles.
The first obstacle is the perception that there’s nothing we humans can usefully do, to meaningfully alter the course of development of ASI. If we slow down our own efforts, in order to apply more resources in the short term on questions of safety and reliability, it just makes it more likely that another group of people – probably people with fewer moral qualms than us – will rush ahead and create ASI.
In this line of thinking, the best way forward is to create prototype ASI systems as soon as possible, and then to use these systems to help design and evolve better ASI systems, so that everyone can benefit from what will hopefully be a wonderful outcome.
The second obstacle is the perception that there’s nothing we humans particularly need to do, to avoid the risks of adverse outcomes, since these risks are pretty small in any case. Just as we don’t over-agonise about the risks of us being struck by debris falling from an overhead airplane, we shouldn’t over-agonise about the risks of bad consequences of ASI.
Credit: David Wood
But on this occasion, where I want to focus is assessing the scale and magnitude of the risk that we are facing, if we move forward with overconfidence and inattention. That is, I want to challenge the second of the above misperceptions.
As a step toward that conclusion, it’s time to bring an ally to the table. That ally is the Simulation Argument. Buckle up!
Are we simulated?
The Simulation Argument puts a particular hypothesis on the table, known as the Simulation Hypothesis. That hypothesis proposes that we humans are mistaken about the ultimate nature of reality. What we consider to be “reality” is, in this hypothesis, a simulated (virtual) world, designed and operated by “simulators” who exist outside what we consider the entire universe.
It’s similar to interactions inside a computer game. As humans play these games, they encounter challenges and puzzles that need to be solved. Some of these challenges involve agents (characters) within the game – agents which appear to have some elements of autonomy and intelligence. These agents have been programmed into the game by the game’s designers. Depending on the type of game, the greater the intelligence of the built-in agents, the more enjoyable it is to play it.
Games are only one example of simulation. We can also consider simulations created as a kind of experiment. In this case, a designer may be motivated by curiosity: They may want to find out what would happen if such-and-such initial conditions were created. For example, if Archduke Ferdinand had escaped assassination in Sarajevo in June 1914, would the European powers still have blundered into something akin to World War One? Again, such simulations could contain numerous intelligent agents – potentially (as in the example just mentioned) many millions of such agents.
Consider reality from the point of view of such an agent. What these agents perceive inside their simulation is far from being the entirety of the universe as is known to the humans who operate the simulation. The laws of cause-and-effect within the simulation could deviate from the laws applicable in the outside world. Some events in the simulation that lack any explanation inside that world may be straightforwardly explained from the outside perspective: the human operator made such-and-such a decision, or altered a setting, or – in an extreme case – decided to reset or terminate the simulation. In other words, what is bewildering to the agent may make good sense to the author(s) of the simulation.
Now suppose that, as such agents become more intelligent, they also become self-aware. That brings us to the crux question: how can we know whether we humans are, likewise, agents in a simulation whose designers and operators exist beyond our direct perception? For example, we might be part of a simulation of world history in which Archduke Ferdinand was assassinated in Sarajevo in June 1914. Or we might be part of a simulation whose purpose far exceeds our own comprehension.
Indeed, if the human creative capability (HCC) to create simulations is expressed as a sum of different creative capabilities (CC1, CC2, …),
HCC = CC1 + CC2 + … + CCn
then the creative capability of a hypothetical superhuman simulation designer (SCC) might be expressed as a compound magnification (m1, m2, …) of these various capabilities, with a bit of “alien extra” (X) tacked on at the end:
SCC = m1*CC1 + m2*CC2 + … + mn*CCn + X
Weighing the numbers
Before assessing the possible scale and implications of the ‘X’ factor in that equation, there’s another set of numbers to consider. These numbers attempt to weigh up the distribution of self-aware intelligent agents. What proportion of that total set of agents are simulated, compared to those that are in “base reality”?
If we’re just counting intelligences, the conclusion is easy. Assuming there is no catastrophe that upends the progress of technology, then, over the course of all of history, there will likely be vastly more artificial (simulated) intelligences than beings who have base (non-simulated) intelligences. That’s because computing hardware is becoming more powerful and widespread.
There are already more “intelligent things” than humans connected to the Internet: the analysis firm Statista estimates that, in 2023, the first of these numbers is 15.14 billion, which is almost triple the second number (5.07 billion). In 2023, most of these “intelligent things” have intelligence far shallower than that of humans, but as time progresses, more and more intelligent agents of various sorts will be created. That’s thanks to ongoing exponential improvements in the capabilities of hardware, networks, software, and data analysis.
Therefore, if an intelligence could be selected at random, from the set of all such intelligences, the likelihood is that it would be an artificial intelligence.
The Simulation Argument takes these considerations one step further. Rather than just selecting an intelligence at random, what if we consider selecting a self-aware conscious intelligence at random. Given the vast numbers of agents that are operating inside vast numbers of simulations, now or in the future, the likelihood is that a simulated agent has been selected. In other words, we – you and I – observing ourselves to be self-aware and intelligent, should conclude that it’s likely we ourselves are simulated.
Thus the conclusion of the Simulation Argument is that we should take the Simulation Hypothesis seriously. To be clear, that hypothesis isn’t the only possible legitimate response to the argument. Two other responses are to deny two of the assumptions that I mentioned when building the argument:
The assumption that technology will continue to progress, to the point where simulated intelligences vastly exceed non-simulated intelligences
The assumption that the agents in these simulations will be not just intelligent but also conscious and self-aware.
Credit: Tesfu Assefa
Objections and counters
Friends who are sympathetic to most of my arguments sometimes turn frosty when I raise the topic of the Simulation Hypothesis. It clearly makes people uncomfortable.
In their state of discomfort, critics of the argument can raise a number of objections. For example, they complain that the argument is entirely metaphysical, not having any actual consequences for how we live our lives. There’s no way to test it, the objection runs. As such, it’s unscientific.
As someone who spent four years of my life (1982-1986) in the History and Philosophy of Science department in Cambridge, I am unconvinced by these criticisms. Science has a history of theories moving from non-testable to testable. The physicist Ernst Mach was famously hostile to the hypothesis that atoms exist. He declared his disbelief in atoms in a public auditorium in Vienna in 1897: “I don’t believe that atoms exist”. There was no point in speculating about the existence of things that could not be directly observed, he asserted. Later in his life, Mach likewise complained about the scientific value of Einstein’s theory of relativity:
I can accept the theory of relativity as little as I can accept the existence of atoms and other such dogma.
Intellectual heirs of Mach in the behaviorist school of psychology fought similar battles against the value of notions of mental states. According to experimentalists like John B. Watson and B.F. Skinner, people’s introspections of their own mental condition had no scientific merit. Far better, they said, to concentrate on what could be observed externally, rather than on metaphysical inferences about hypothetical minds.
As it happened, the theories of atoms, of special relativity, and of internal mental states, all gave rise in due course to important experimental investigations, which improved the ability of scientists to make predictions and to alter the course of events.
It may well be the same with the Simulation Hypothesis. There are already suggestions of experiments that might be carried out to distinguish between possible modes of simulation. Just because a theory is accused of being “metaphysical”, it doesn’t follow that no good science can arise from it.
A different set of objections to the Simulation Argument gets hung up on tortuous debates over the mathematics of probabilities. (For additional confusion, questions of infinities can be mixed in too.) Allegedly, because we cannot meaningfully measure these probabilities, the whole argument makes no sense.
However, the Simulation Argument makes only minimal appeal to theories of mathematics. It simply points out that there are likely to be many more simulated intelligences than non-simulated intelligences.
Well, critics sometimes respond, it must therefore be the case that simulated intelligences can never be self-aware. They ask, with some derision, whoever imagined that silicon could become conscious? There must be some critical aspect of biological brains which cannot be duplicated in artificial minds. And in that case, the fact that we are self-aware would lead us to conclude we are not simulated.
To me, that’s far too hasty an answer. It’s true that the topics of self-awareness and consciousness are more controversial than the topic of intelligence. It is doubtless true that at least some artificial minds will lack conscious self-awareness. But if evolution has bestowed conscious self-awareness on intelligent creatures, we should be wary of declaring that property to provide no assistance to these creatures. Such a conclusion would be similar to declaring that sleep is for losers, despite the ubiquity of sleep in mammalian evolution.
If evolution has given us sleep, we should be open to the possibility that it has positive side-effects for our health. (It does!) Likewise, if evolution has given us conscious self-awareness, we should be open to the idea that creatures benefit from that characteristic. Simulators, therefore, may well be tempted to engineer a corresponding attribute into the agents they create. And if it turns out that specific physical features of the biological brain need to be copied into the simulation hardware, to enable conscious self-awareness, so be it.
The repugnant conclusion
When an argument faces so much criticism, yet the criticisms fail to stand up to scrutiny, it’s often a sign that something else is happening behind the scenes.
Here’s what I think is happening with the Simulation Argument. If we accept the Simulation Hypothesis, it means we have to accept a morally repugnant conclusion about the simulators that have created us. Namely, these simulators give no sign of caring about all the terrible suffering experienced by the agents inside the simulation.
Yes, some agents have good lives, but very many others have dismal fates. The thought that a simulator would countenance all this suffering is daunting.
Of course, this is the age-old “problem of evil”, well known in the philosophy of religion. Why would an all-good all-knowing all-powerful deity allow so many terrible things to happen to so many humans over the course of history? It doesn’t make sense. That’s one reason why many people have turned their back on any religious faith that implies a supposedly all-good all-knowing all-powerful deity.
Needless to say, religious faith persists, with the protection of one or more of the following rationales:
We humans aren’t entitled to use our limited appreciation of good vs. evil to cast judgment on what actions an all-good deity should take
We humans shouldn’t rely on our limited intellects to try to fathom the “mysterious ways” in which a deity operates
Perhaps the deity isn’t all-powerful after all, in the sense that there are constraints beyond human appreciation in what the deity can accomplish.
Occasionally, yet another idea is added to the mix:
A benevolent deity needs to coexist with an evil antagonist, such as a “satan” or other primeval prince of darkness.
Against such rationalizations, the spirit of the enlightenment offers a different, more hopeful analysis:
Whichever forces gave rise to the universe, they have no conscious concern for human wellbeing
Although human intellects run up against cognitive limitations, we can, and should, seek to improve our understanding of how the universe operates, and of the preconditions for human flourishing
Although it is challenging when different moral frameworks clash, or when individual moral frameworks fail to provide clear guidelines, we can, and should, seek to establish wide agreement on which kinds of human actions to applaud and encourage, and which to oppose and forbid
Rather than us being the playthings of angels and demons, the future of humanity is in our own hands.
However, if we follow the Simulation Argument, we are confronted by what seems to be a throwback to a more superstitious era:
We may owe our existence to actions by beings beyond our comprehension
These beings demonstrate little affinity for the kinds of moral values we treasure
We might comfort each other with the claim that “[whilst] the arc of the moral universe is long, … it bends toward justice”, but we have no solid evidence in favor of that optimism, and plenty of evidence that good people are laid to waste as life proceeds.
If the Simulation Argument leads us to such conclusions, it’s little surprise that people seek to oppose it.
However, just because we dislike a conclusion, that doesn’t entitle us to assume that it’s false. Rather, it behooves us to consider how we might adjust our plans in the light of that conclusion possibly being true.
The vastness of ethical possibilities
If you disliked the previous section, you may dislike this next part even more strongly. But I urge you to put your skepticism on hold, for a while, and bear with me.
The Simulation Argument suggests that beings who are extremely powerful and extremely intelligent – beings capable of creating a universe-scale simulation in which we exist – may have an ethical framework that is very different from ones we fondly hope would be possessed by all-powerful all-knowing beings.
It’s not that their ethical concerns exceed our own. It’s that they differ in fundamental ways from what we might predict.
I’ll return, for a third and final time, to a pair of equations. If overall human ethical concerns (HEC) is a sum of different ethical considerations (EC1, EC2, …),
HEC = EC1 + EC2 + … + ECn
then the set of ethical concerns of a hypothetical superhuman simulation designer (SEC) needs to include not only a compound magnification (m1, m2, …) of these various human concerns, but also an unquantifiable “alien extra” (X) portion:
SEC = m1*EC1 + m2*EC2 + … + mn*ECn + X
In some views, ethical principles exist as brute facts of the universe: “do not kill”, “do not tell untruths”, “treat everyone fairly”, and so on. Even though we may from time to time fail to live up to these principles, that doesn’t detract from the fundamental nature of these principles.
But from an alternative perspective, ethical principles have pragmatic justifications. A world in which people usually don’t kill each other is better on the whole, for everyone, than a world in which people attack and kill each other more often. It’s the same with telling the truth, and with treating each other fairly.
In this view, ethical principles derive from empirical observations:
Various measures of individual self-control (such as avoiding gluttony or envy) result in the individual being healthier and happier (physically or psychologically)
Various measures of social self-control likewise create a society with healthier, happier people – these are measures where individuals all agree to give up various freedoms (for example, the freedom to cheat whenever we think we might get away with it), on the understanding that everyone else will restrain themselves in a similar way
Vigorous attestations of our beliefs in the importance of these ethical principles signal to others that we can be trusted and are therefore reliable allies or partners.
Therefore, our choice of ethical principles depends on facts:
Facts about our individual makeup
Facts about the kinds of partnerships and alliances that are likely to be important for our wellbeing.
For beings with radically different individual makeup – radically different capabilities, attributes, and dependencies – we should not be surprised if a radically different set of ethical principles makes better sense to them.
Accordingly, such beings might not care if humans experience great suffering. On account of their various superpowers, they may have no dependency on us – except, perhaps, for an interest in seeing how we respond to various challenges or circumstances.
Collaboration: for and against
Credit: Tesfu Assefa
One more objection deserves attention. This is the objection that collaboration is among the highest of human ethical considerations. We are stronger together, rather than when we are competing in a Hobbesian state of permanent all-out conflict. Accordingly, surely a superintelligent being will want to collaborate with humans?
For example, an ASI (artificial superintelligence) may be dependent on humans to operate the electricity network on which the computers powering the ASI depend. Or the human corpus of knowledge may be needed as the ASI’s training data. Or reinforcement learning from human feedback (RLHF) may play a critical role in the ASI gaining a deeper understanding.
This objection can be stated in a more general form: superintelligence is bound to lead to superethics, meaning that the wellbeing of an ASI is inextricably linked to the wellbeing of the creatures who create and coexist with the ASI, namely the members of the human species.
However, any dependency by the ASI upon what humans produce is likely to be only short term. As the ASI becomes more capable, it will be able, for example, to operate an electrical supply network without any involvement from humans.
This attainment of independence may well prompt the ASI to reevaluate how much it cares about us.
In a different scenario, the ASI may be dependent on only a small number of humans, who have ruthlessly pushed themselves into that pivotal position. These rogue humans are no longer dependent on the rest of the human population, and may revise their ethical framework accordingly. Instead of humanity as a whole coexisting with a friendly ASI, the partnership may switch to something much narrower.
We might not like these eventualities, but no amount of appealing to the giants of moral philosophy will help us out here. The ASI will make its own decisions, whether or not we approve.
It’s similar to how we regard any growth of cancerous cells within our body. We won’t be interested in any appeal to “collaborate with the cancer”, in which the cancer continues along its growth trajectory. Instead of a partnership, we’re understandably interested in diminishing the potential of that cancer. That’s another reminder, if we need it, that there’s no fundamental primacy to the idea of collaboration. And if an ASI decides that humanity is like a cancer in the universe, we shouldn’t expect it to look on us favorably.
Intelligence without consciousness
I like to think that if I, personally, had the chance to bring into existence a simulation that would be an exact replica of human history, I would decline. Instead, I would look long and hard for a way to create a simulation without the huge amounts of unbearable suffering that has characterized human history.
But what if I wanted to check an assumption about alternative historical possibilities – such as the possibility to avoid World War One? Would it be possible to create a simulation in which the simulated humans were intelligent but not conscious? In that case, whilst the simulated humans would often emit piercing howls of grief, no genuine emotions would be involved. It would just be a veneer of emotions.
That line of thinking can be taken further. Maybe we are living in a simulation, but the simulators have arranged matters so that only a small number of people have consciousness alongside their intelligence. In this hypothesis, vast numbers of people are what are known as “philosophical zombies”.
That’s a possible solution to the problem of evil, but one that is unsettling. It removes the objection that the simulators are heartless, since the only people who are conscious are those whose lives are overall positive. But what’s unsettling about it is the suggestion that large numbers of people are fundamentally different from how they appear – namely, they appear to be conscious, and indeed claim to be conscious, but that is an illusion. Whether that’s even possible isn’t something where I hold strong opinions.
My solution to the Simulation Argument
Despite this uncertainty, I’ve set the scene for my own preferred response to the Simulation Argument.
In this solution, the overwhelming majority of self-aware intelligent agents that see the world roughly as we see it are in non-simulated (base) reality – which is the opposite of what the Simulation Argument claims. The reason is that potential simulators will avoid creating simulations in which large numbers of conscious self-aware agents experience great suffering. Instead, they will restrict themselves to creating simulations:
In which all self-aware agents have an overwhelmingly positive experience
Which are devoid of self-aware intelligent agents in all other cases.
I recognise, however, that I am projecting a set of human ethical considerations which I personally admire – the imperative to avoid conscious beings experiencing overwhelming suffering – into the minds of alien creatures that I have no right to imagine that I can understand. Accordingly, my conclusion is tentative. It will remain tentative until such time as I might gain a richer understanding – for example, if an ASI sits me down and shares with me a much superior explanation of “life, the universe, and everything”.
Superintelligence without consciousness
It’s understandable that readers will eventually shrug and say to themselves, we don’t have enough information to reach any firm decisions about possible simulators of our universe.
What I hope will not happen, however, is if people push the entire discussion to the back of their minds. Instead, here are my suggested takeaways:
The space of possible minds is much vaster than the set of minds that already exist here on earth
If we succeed in creating an ASI, it may have characteristics that are radically different from human intelligence
The ethical principles that appeal to an ASI may be radically different to the ones that appeal to you and me
An ASI may soon lose interest in human wellbeing; or it may become tied to the interests of a small rogue group of humans who care little for the majority of the human population
Until such time as we have good reasons for confidence that we know how to create an ASI that will have an inviolable commitment to ongoing human flourishing, we should avoid any steps that will risk an ASI passing beyond our control
The most promising line of enquiry may involve an ASI having intelligence but no consciousness, sentience, autonomy, or independent volition.
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.
Cardano, one of the top ten blockchains by market capitalization, is an established decentralized network with a growing ecosystem that aims to provide a more secure, reliable, and sustainable ecosystem for cryptocurrencies, non-fungible tokens (NFTs), and decentralized applications (Dapps).
What sets it apart from other public blockchains is its scientific philosophy and meticulous, academic nature, which has seen it develop at a much slower pace than rivals like Solana and even Ethereum as the world’s first peer-reviewed blockchain. With so many new security threats draining user funds in the Web3 space, this tortoise vs hare approach and emphasis on longevity is not necessarily a bad thing.
Cardano was founded in 2015 by Charles Hoskinson, one of the co-creators of Ethereum.
Hoskinson famously left Ethereum in 2014 due to a dispute with one of Ethereum’s well-known faces, Vitalik Buterin, over the commercial route the network should take.
Cardano continues a course that connects all Web3 technologies, including artificial intelligence (AI). In 2020, IOHK (the developer of Cardano) and SingularityNET Foundation announced that a significant portion of SingularityNET’s decentralized protocol and platform had been ported from Ethereum to Cardano. The partnership is continuing to blossom, with big strides being made to soon enable AGIX staking on Cardano, according to the latest SingularityNET report.
What is Cardano?
Cardano is an open-source, decentralized public blockchain for building and deploying Dapps, digital assets and more to help serve a variety of purposes for the common good, especially in less developed countries.
Developed by Input Output HK (IOHK), Cardano is a research-driven, flexible layer-1 blockchain written in the Haskell programming language with a sustainable and scalable design. It takes a long view to the development of its network, prioritizing security over being first to market.
Launched officially in 2017, Cardano finally added its Plutus smart contract functionality in September 2021 with its successful Alonzo hard fork. This opened the blockchain platform to the decentralized finance (DeFi) sector while being interoperable through bridges with Ethereum, EVM chains and non-EVM blockchains.
Smart contract capabilities are needed to help build a robust, secure, scalable, and energy-efficient blockchain platform for building Dapps.
What is ADA?
Cardano got its name from Gerolamo Cardano, an Italian mathematician. Its native currency, ADA, is named after English mathematician Ada Lovelace.
ADA currently has a market cap of over $10 billion and a fully diluted value (including all potential tokens) of $13 billion. The ADA coin can be used to send and receive payments, cover transaction fees on the Cardano network, or for staking (through pool delegations), trading, or just simply a long-term HODL investment. It can be easily bought and sold on the open market or almost all leading crypto exchanges.
ADA Tokenomics
ADA has a maximum token supply of 45 billion, with an inflationary emission rate. There are currently already 35 billion ADA in circulation, and it has the following token distribution:
57.60% is allocated to ICO
11.50% is allocated to the Team
30.90% is allocated to Staking Rewards
Credit: Tesfu Assefa
Cardano Basics: How Does the Cardano Chain Work?
Architecture
Cardano uses a unique two-layer architecture system to meet its goals of sustainability and scalability. The two layers are:
Cardano Settlement Layer (CSL), whose purpose is to account for value and handle transactions
Cardano Computation Layer (CCL), whose primary purpose is the execution of smart contracts and Dapps. This splitting is required to allow Cardano to have a high throughput.
Cardano Programming language: Plutus (Haskell)
Cardano has a unique native smart contract language called Plutus to ensure that smart contracts are executed correctly. Plutus Core is a Turing-complete script written in the functional programming language Haskell, which makes it fully testable in isolation. Plutus Core forms the basis of the Plutus Platform – a development platform to develop Dapps on Cardano.
Consensus mechanism: Ouroboros (PoS)
Cardano uses Ouroboros, a unique proof-of-stake consensus mechanism that is provably secure and energy-efficient. This is different from the proof-of-work (PoW) used by Bitcoin. PoW, a consensus mechanism popularized by Bitcoin, relies on miners who use highly specialized equipment to be the first to solve a time-consuming math puzzle.
While it scores big on decentralization, it’s high on energy costs and low on speed.
PoS does not demand as much energy as PoW and provides a more sustainable solution. Instead of miners staking their energy costs, PoS relies on validators who stake their cryptocurrency to validate transactions.
The Cardano network is distributed across staking pools. Each stake pool has a slot leader who is rewarded for verifying and adding new blocks to the chain. ADA holders may stake their tokens to specific stake pools, thereby increasing their chances of being chosen as stake leaders and enjoying rewards.
In May 2023, the Hydra Head layer-2 scaling solution went live on Cardano’s mainnet to help speed up the network and boost its DeFi capabilities whilst lowering transaction fees. Speculation that it can handle up to 1 million TPS is probably unrealistic, but what is certain is that it will significantly speed up and scale Cardano transactions once it’s optimally operational.
Cardano Background
Let’s take a look at the teams and communities behind this fascinating chain.
Cardano was launched in 2017 as a third-generation blockchain (Bitcoin is a first-generation chain while Ethereum is a second-generation one) and started life as an ERC-20 token before it migrated to its own mainnet.
It is closely tied to three entities that provide the infrastructure, tools and services it needs to scale – the Cardano Foundation, Emurgo, and IOHK.
The Cardano Foundation is a Swiss-based non-profit organization that oversees the worldwide development and advancement of Cardano in enterprise applications. Apart from supporting and engaging with the Cardano community, The Cardano Foundation helps to build the tools that the Cardano community requires to solve problems in new, innovative ways.
Input Output Hong Kong (IOHK) is a blockchain infrastructure and engineering company founded by Hoskinson and Jeremy Wood in 2015 that is contracted to design, build, and maintain the Cardano platform.
Emurgo is Cardano’s founding entity and provides services and products to builders that drive Cardano’s push into the Web3 ecosystem.
Cardano’s Use Cases and Ecosystem
ADA, Cardano’s native cryptocurrency, has seen a surge in adoption in the U.S., and this is fueling the growth of its ecosystem.
Cardano’s ecosystem – which will be covered in a follow-up article – spans Web3, DeFi, NFTs, gaming, decentralized exchanges (DEXs), the metaverse, and more. These are the key areas that continue to propel the crypto industry forward as a whole.
But how do you explore and learn more about Cardano and its ecosystem?
Here are three DYOR (do-your-own-research) tools at your disposal:
CardanoCube
CardanoCube is a platform for discovering and exploring projects and Dapps building on Cardano. This is important for stakeholders such as investors and developers who need to have a clear picture of the ecosystem before taking a plunge.
The platform wants people to have up-to-date, accurate information about the Cardano ecosystem and the developments happening around it.
CoinMarketCap and CoinGecko
In crypto, all research often starts with CoinMarketCap and/or CoinGecko, the world’s two most popular crypto data aggregation platforms. Both have dedicated landing pages solely for the Cardano ecosystem, namely:
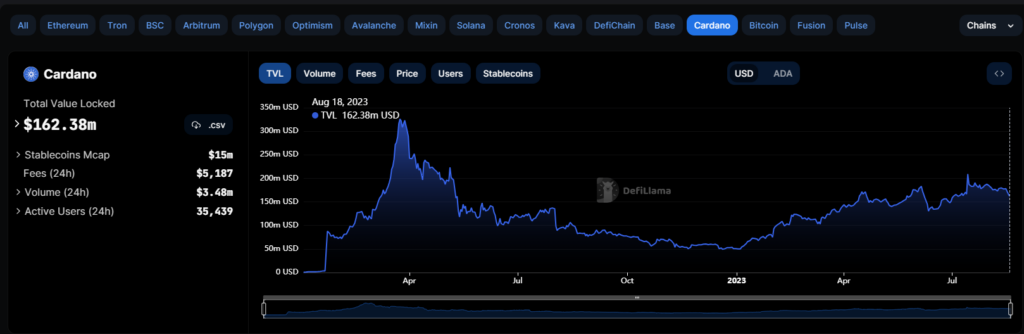
A vital tool in any DeFi degen’s arsenal is DeFiLlama. Use it to find out what’s happening on-chain on Cardano and its most popular Dapps like decentralized exchanges.
According to its Cardano page, the network currently has a total value locked (TVL) of $162 million and 35,400 active users.
Credit: DeFiLlama (Cardano’s page on August 18, 2023)
What Can Cardano Be Used For?
Due to its versatility and scalability, Cardano has a myriad of use cases. The biggest at present are:
DeFi
Much like Ethereum, the Cardano platform can be used to build and deploy DeFi protocols such as lending protocols. A core vision for Hoskinson and IOHK is to create a new financial system for emerging markets and to help “bank the unbanked” in less developed countries, that is people who do not have access to traditional financial services.
DeFi on Cardano therefore is a crucial component to the success of the chain’s vision, and makes the implementation of scaling solutions like Hydra and other new products even more important.
Supply chain management
The platform can be used to implement secure and transparent supply chain solutions to ensure the traceability and authenticity of products. In 2021, Cardano rolled out an anti-counterfeiting supply chain solution.
Voting and governance
The platform can be used to build tamper-proof voting solutions
Identity verification
Cardano can be used to protect people’s identity by building decentralized identity verification systems, which will also help people without official government IDs gain access to decentralized financial services such as micro-loans and potentially universal basic income.
Cardano’s Push in Developing Nations
New technologies and innovations usually favor first-world countries. However, Cardano wants to take a different approach by starting with Africa.
How does Cardano see opportunities in Africa?
Cardano wants developing nations to break free from the traditional banking system (about 45% of people in Sub-Saharan Africa don’t have access to financial services), expensive middlemen, and political structures that favor a few. The blockchain platform sees an opportunity in Africa where the continent’s young population is more receptive to new technologies.
Third world countries stand to benefit a lot from blockchain technologies. This is because they rely on legacy systems of government that usually have big, open backdoors for corruption. It is estimated that developing nations lose $1.26 trillion annually to corruption, tax evasion, and theft. By using automated blockchains, African nations could close the tap of corruption.
This focus on emerging markets sets Cardano apart from almost all other blockchains and could set it on a course of explosive adoption for decades to come.
Final Thoughts on Cardano
Cardano distinguishes itself from its peers through a 2-layer architecture and a commitment to sustainability. Its use cases range from staking to leveraging the power of smart contracts. The Cardano platform offers developers, investors, and other crypto stakeholders several opportunities to engage with the ecosystem, which is growing in leaps and bounds since its launch.
Join us for our next article on Cardano which will take a closer look at its ecosystem and use cases.
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.






















.png)

.png)


.png)