


Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.
Coinbase Report: Are Crypto AIs a Mirage Or For Real?

Artificial Intelligence (AI) has been making rapid strides in recent years, with breakthroughs like ChatGPT, Midjourney and Claude capturing the public imagination. At the same time, the world of cryptocurrency and blockchain technology is expanding, vying for the attention of a still-young digital economy. Can these two cutting-edge fields co-exist and aid each other’s evolution? The question presents both exciting opportunities and complex challenges.
A new report by Coinbase, a leading US-based cryptocurrency exchange, which also launched the surging Base layer-2 network, delves into the current state of the crypto-AI landscape. The report highlights that while there is significant potential in the overlap between technology’s two brightest sectors, the path to widespread adoption is not that straightforward. Different sub-sectors within this intersection have vastly different opportunities and development timelines.
One key observation is that decentralization alone is not enough for an AI product to succeed in the crypto space. It must also reach feature-parity with centralized alternatives. Crypto-based AI solutions must offer compelling advantages beyond just being decentralized.
The report also suggests that the value of AI tokens may be overstated due to the current hype around AI. Many AI tokens may lack sustainable demand-side drivers in the short to medium term, despite the excitement surrounding them.
Key Trends in Crypto AI
Open Source Models Carry On
The AI sector has a thriving open-source ecosystem, with platforms like HuggingFace.co hosting a wide range of publicly-available models. This open-source culture coexists with a competitive commercial sector, ensuring that non-performant models are quickly weeded out.
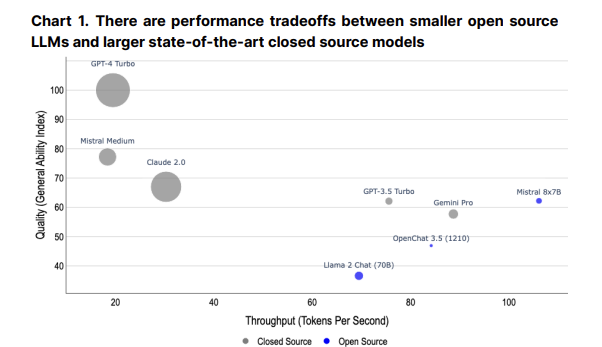
Smaller AI Models Gain Traction
Despite this, smaller AI models are increasing in quality and cost-effectiveness. Fine-tuned open-source models can even outperform leading closed-source models in certain benchmarks. This trend, combined with the open-source culture, enables a future where performant AI models can be run locally, offering a high degree of decentralization.
AI Integrations Strongly Benefit Existing Platforms
The report notes that existing platforms with strong user lock-in or concrete business problems are well-positioned to “disproportionately” benefit from AI integrations.
- For example, GitHub Copilot‘s integration with code editors enhances an already powerful developer environment. Similarly, embedding AI interfaces into various tools like mail clients, spreadsheets, and CRM software are natural use-cases for AI.
- In such scenarios, AI models augment existing platforms rather than creating entirely new ones.
- AI models that improve traditional business processes internally often rely on proprietary data and closed systems, making them likely to remain closed-source.
Hardware and Compute Trends
In the AI hardware and compute space, there are two distinct trends:
One is shifting computation from training to inferencing: with more models now available, the focus moves towards making queries to these already-trained models. This trend favors platforms that can reliably run production-ready models securely.
A second, related trend is that the competitive landscape around hardware architecture is evolving, with new processors from Nvidia, Google, and Groq potentially shifting cost dynamics in the AI industry. Cloud providers that can quickly adapt, procure hardware at scale, and set up associated infrastructure stand to reap the rewards of these developments.

Crypto’s Role in the AI Pipeline: Four Stages
The Coinbase report next examines crypto’s potential impact on four stages of the AI pipeline:
1) data collection and management
2) model training and inferencing
3) output validation
4) tracking
1) Data Collection and Management
Historical blockchain data is a rich source of training data for AI models. However, commercial models tend to use proprietary datasets, posing challenges for decentralized data marketplaces, which need to compete with both open-source data directories and corporate silos.
Decentralized storage also faces hurdles in the AI industry. While decentralized storage can offer potential cost savings, it currently lacks the tooling, integrations, and predictable costs of mature cloud systems. Regulatory and technical challenges around sensitive data storage on decentralized platforms remain significant barriers.
2) Model training and Inferencing
In the model training and inferencing stage, decentralized compute solutions like Render and NuNet aim to leverage idle computing resources to provide an alternative to centralized cloud providers. While some projects have seen increased usage, long-term success faces strong competition from established players. Technical limitations like network bandwidth constraints also pose challenges for decentralized compute networks.
3) Output Validation
Validating AI model outputs, and ensuring trust is another area where crypto-based solutions are being explored. However, the complexity of model benchmarking and the increasing feasibility of running models locally on consumer hardware raise questions about the demand for trustless inferencing solutions.
4) Tracking
Finally, the importance of tracking AI-generated content and proving online identity is growing. While decentralized identifiers and on-chain data hashes can help address these issues, centralized alternatives like KYC providers and AI watermarking techniques are also being developed.
Trading the AI Narrative

Despite the challenges, AI tokens have outperformed major cryptocurrencies and AI-related equities in recent months. The report suggests that AI tokens benefit from strong performance in the crypto market and in the AI industry, leading to upside volatility even during bitcoin drawdown periods. Hype drives demand, and investors will be piling in for some time to come.
However, the lack of clear adoption forecasting and metrics has enabled speculative trading that may not be sustainable in the long run. Eventually, as in every crypto cycle, price and utility will need to converge, either through rising use-cases or falling prices.
Looking Ahead
The marriage of AI and crypto is still in its very early stages, and is likely to evolve rapidly as the broader AI sector develops. A decentralized AI future, as envisioned by many in the crypto industry, is not guaranteed. Crypto-based solutions are technically feasible, but to drive adoption they must provide meaningful advantages over centralized alternatives.
The AI industry itself is undergoing swift changes, fighting more and more headwinds as public opinion often turns against it. Therefore it is crucial to navigate this space carefully. Deeper examination of how crypto-based solutions can offer substantially better alternatives, or at least a clear understanding of the underlying trading narrative, is essential for investors and entrepreneurs alike.
As the AI and crypto landscapes continue to search for a sustainable symbiosis, ongoing research and experimentation will be vital to unlocking the potential of this area while meeting its challenges.
The future of decentralized AI is still being written, and it will be shaped by the ingenuity and perseverance of the innovators working at the forefront of these transformative technologies.
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.
Quick Guide to NFC Ring Security: Why It’s Important and Who Needs It? | Highlights from S2EP12

Scalable AGI | Mindplex Podcast – S2EP13

Bitcoin Ordinals: A Quick Guide

Non-fungible tokens (NFTs) used to be the sole domain of Ethereum and other smart contract networks like Cardano and Solana. During the 2021 bull run, the world caught crypto JPEG fever thanks to collections like Crypto Punks, Bored Ape Yacht Club (BAYC) and 2024 darling Pudgy Penguins (now in a Walmart near you), and Ethereum was the infrastructure that captured most of the value.
In early 2023, a new challenger kicked open the saloon doors, making a crazy entrance into the Wild West of crypto: Ordinals. The crazy part comes with that it lives on the Bitcoin blockchain, which is notoriously slow (only seven transactions per second) and with a hardcore Bitcoin maxi community strongly resistant to any change.
Despite this, it’s been up only for Bitcoin Ordinals, as over 64 million have been minted by the time of this article.
What are Bitcoin Ordinals?
Ordinals in their current form were introduced by Bitcoin developer Casey Rodarmor on 21 July 2022 with the publication of his Ordinal Theory paper.
Bitcoin Ordinals are a way of assigning a unique identifier to each satoshi (sat), the smallest unit of Bitcoin, based on the order in which it was mined. By assigning an ordinal number to each sat, it becomes possible to create unique, distinguishable assets on the Bitcoin blockchain. This means that every single sat can be individually tracked and associated with specific data, such as images, videos, or other digital artifacts.
According to Rodarmor, Ordinals’ genesis can be traced back to Satoshi Nakamoto’s creation of the Bitcoin blockchain in 2009. That means that especially early Ordinals have a historical significance within the blockchain’s timeline. He also noted that the concept of ordinals was independently discovered multiple times, predating the NFT boom by nearly a decade, most notably:
- Litecoin creator Charlie Lee’s 2012 proposal on the Bitcoin Talk forum to integrate proof-of-stake using the ordinal algorithm
- jl2012’s introduction of a decimal notation scheme that mirrored key features of ordinals.
Although neither proposal was fully realized, they underscore the enduring interest and potential of ordinals within the Bitcoin community, long before their recent surge in popularity.
Rodarmor wrote,
These independent inventions of ordinals indicate in some way that ordinals were discovered, or rediscovered, and not invented. The ordinals are an inevitability of the mathematics of Bitcoin, stemming not from their modern documentation, but from their ancient genesis. They are the culmination of a sequence of events set in motion with the mining of the first block, so many years ago.
How do Bitcoin Ordinals work?
Creating a Bitcoin Ordinal involves ‘inscribing’ data onto a specific sat, hopefully the rarer the better. This is done by embedding the inscribed data into the witness data of a Bitcoin transaction, using the ordinal number of the sat as a reference point.
To understand how this works, let’s break down the technical details:
- Ordinal numbers: Each sat is assigned an ordinal number based on its position in the blockchain. The first sat in the genesis block is assigned the number 0, the second sat is assigned 1, and so on. This numbering scheme continues sequentially throughout the entire Bitcoin blockchain.
- Inscribing: An inscription is the process of embedding data (such as an image or video) into a Bitcoin transaction using the ordinal number of a specific sat. This is done by including the data in the witness data of a taproot script-path spend.
- Taproot and SegWit: Bitcoin Ordinals leverage comparatively new upgrades to the Bitcoin protocol, specifically Taproot and Segregated Witness (SegWit). These provide more flexibility in the types of transactions that can be recorded on the blockchain, making it possible to embed larger amounts of data.
- Transfers and ownership: Once an inscription is made, the associated sat can be transferred or sold just like any other Bitcoin. The ordinal number and associated data remain linked to the sat throughout its lifetime on the blockchain.

Rodarmor Rarity Index
According to the Rodarmor Rarity Index, created by Casey Rodarmor, the developer of Ordinal Theory, satoshis can be classified into different categories based on their rarity. About 99% of sats are considered Common Sats.
Uncommon Sats are the first sat of each newly mined block, occurring roughly every 10 minutes. Rare Sats are the first sat of the block mined after a Bitcoin network difficulty adjustment, which happens every 2,016 blocks or about two weeks. Epic Sats are the first satoshi mined in the block immediately following a Bitcoin halving event, occurring every 210,000 blocks or roughly four years.
Legendary Sats are the first satoshi mined when a difficulty adjustment and halving event coincide, which will happen only once every 24 years, with the first instance scheduled for 2032. Finally, the Mythic Sat is the first-ever satoshi mined by Satoshi Nakamoto in the genesis block in 2009.
Magic Eden Rare Sats
Magic Eden drive most Ordinals sales, and have created their own version of the Rodarmor Rarity Index. Let’s go over it:
- Nakamoto Sats: Highly sought-after sats mined by Bitcoin’s pseudonymous creator, Satoshi Nakamoto.
- First Transaction Sats: Sats originating from the first-ever Bitcoin transaction on January 12, 2009, when Satoshi Nakamoto sent 10 Bitcoins to Hal Finney.
- Palindrome sats: Sats whose numbers can be read the same forwards and backwards (e.g., 16661 or 23832), adding a layer of rarity and curiosity.
- Vintage Sats: Sats mined within the initial 1,000 blocks of the Bitcoin blockchain, marking the dawn of Bitcoin.
- Pizza Sats: Sats from the iconic transaction on May 22, 2010, where a programmer paid 10,000 Bitcoins for two Papa John’s pizzas worth $27 at the time, and thereby created a monetary value for BTC.
- Block 9 Sats: Some of the oldest sats in circulation, mined in one of the earliest blocks and offering a tangible connection to Bitcoin’s beginnings.
- Block 78 Sats: Sats from the block mined by Hal Finney, marking the first instance where someone other than Satoshi Nakamoto (or is it???) contributed to the blockchain’s growth.
The Essential Ordinals and Rare Sat Tool Case
Some of the best tools for exploring the world of Ordinals include Ordpool.space for tracking Ordinals in the mempool, Liquidium.finance for Ordinals DeFi, and Ordiscan.com for checking your wallet for assets like runes.
Geniidata and Ord.io are popular Ordinals explorers, while Sating.io and Automated Sat Hunter by Deezy Labs helps you scan your wallet for rare sats. For launching your own Ordinals project, consider Ordzaar, and for inscribing data, Ordinalsbot is the go-to.
Conclusion
Bitcoin Ordinals represent a significant development in the evolution of Bitcoin, enabling the creation of unique, NFT-like digital assets native to the Bitcoin blockchain. While the concept is still relatively new, it has the potential to unlock a wide range of use cases and drive innovation in the Bitcoin ecosystem, which includes anything from digital art to gaming to even digital identity. With Bitcoin layer-2 chains also improving in leaps and bounds, the future looks extra-ordinally bright (sorry, couldn’t resist!) for this new digital asset class.
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.
Can AI Aid in the Recovery Of Lost Bitcoin?

Every time Bitcoin hits a new all-time high, we hear that about ‘about 20%’ of the Bitcoins minted are lost, never to be recovered, with some seriously sob stories thrown in for good measure. They were lost for various reasons, and more continue to go missing, albeit less often these days. Most of those missing Bitcoins have been lying dormant for several years. In Bitcoin’s early days, stashes of Bitcoin weren’t seen as the honeypots they are today, and people got careless, only to pay the ultimate price of losing their BTC. Now, with the age of AI upon us in 2024, can new technologies help retrieve those missing fortunes?
Careless Early Miners
In the early years of blockchain, from 2009 to 2014 or so, some individuals had found a hobby using spare PCs to mine Bitcoin. This wasn’t terribly lucrative in fiat terms at the time, but many of those miners racked up what would now be enviable collections of dozens, hundreds, or thousands of Bitcoins. By now, most of us have heard about the missing hard drives that contain many millions of dollars worth of Bitcoin. These days, one solitary Bitcoin is worth a tidy sum in fiat money, and accumulators speak of ‘stacking Sats’ (1 SAT = 0.00000001 BTC) rather than accumulating full Bitcoins.
Recovery Efforts
Have any of those stray Bitcoins been recovered? Yes, a small percentage of them have, and there is hope that state-of-the-art decryption techniques and the latest GPUs can be put to use to reclaim more of them. Companies have been set up to assist people in recovering missing Bitcoin wallets, and these efforts have seen some modest success in cases where there is at least a bit of a trail that could lead to the missing Bitcoins.
Bitcoin cryptography is strong. A private key represents a unique number between 1 and 2 to the power of 256. That’s more than the total number of atoms in the universe. With current technology, a brute force attack to test a colossal number of potential keys until landing on the right one would take millions of years.
Is it hopeless? Is it not even worth trying? That depends. If the owner of missing Bitcoins has any hints at a seed phrase, records of where it may have been transferred to or stored, or a physical storage device, that could greatly cut down the time it would take to get to a positive result.
AI to the Rescue?
Artificial Intelligence has been a hot topic of conversation for a while now, and cryptocurrency is not immune from AI influence. When it comes to cracking a Bitcoin wallet, the brute force method will be futile on its own, but AI models are being developed that can drastically shorten the time it takes to crack a private key.
With machine learning and the most powerful GPUs, patterns can be identified within vast collections of data that can significantly bring down the time it takes to uncover encryption keys.
Enter PassGPT, a cutting-edge password guessing AI model that could be the saviour that unlocks your lost millions. Built on OpenAI’s GPT-2 architecture and trained on millions of exposed credentials, PassGPT has a unique edge over other password-guessing tools. By using a technique called progressive sampling, it constructs passwords one character at a time, making it 20% more effective than even the most advanced GAN models.
But PassGPT isn’t just a one-trick pony. It can analyse password strength, identify patterns, and even guess passwords in multiple languages. And it can come up with new passwords that aren’t even in its training data.
So, how could this help you recover your lost Bitcoin? By adapting PassGPT to focus specifically on Bitcoin wallet passwords and feeding it data on common password patterns used by crypto enthusiasts, its effectiveness could be supercharged.
Of course, this technology raises some security concerns, but when used responsibly, it could be a lifeline for those who have lost access to their Bitcoin due to a forgotten password. As generative AI continues to evolve, solutions like PassGPT could become an invaluable tool in the ongoing challenge of balancing security and accessibility in the world of cryptocurrency.
Side-Channel Attacks on Hardware Wallets
Hardware wallets are a common and extremely secure way to store private keys offline. When used judiciously and prudently, they work very well – and best practices should be followed to ensure that private keys are backed up in another separate location, just in case the device goes missing or the owner becomes incapacitated. If an older or less sophisticated hardware wallet has become inaccessible, a side-channel attack offers a glimmer of hope.
A side-channel attack is a method of exploiting any physical characteristics of a hardware wallet that can be detected via electronic sensors. Characteristics including timing, power consumption patterns, and electromagnetic and acoustic emissions which can sometimes reveal enough information to obtain fragments of the PIN code to access the wallet or crack the private keys. Although only fragments may be uncovered, they can still drastically reduce the time taken for cracking tools (including AI and machine learning) to search for the private key.
Technology is advancing all the time, and different hardware wallets will have different levels of vulnerability to side-channel attacks. One of the most well-known hardware wallet makers, Ledger, claims that its wallets are immune to such attacks, so mileage of side-channel attacks may vary. Ledger’s main competitor, Trezor, also claims that crypto functions have been re-written by their cryptography professionals to eliminate such vulnerabilities. Additional measures such as ‘secure elements’, which ensconces the private key permanently inside a computer chip, also makes breaking cold storage encryption near impossible.

Limitations of Silicon
The silicon computer chips that power all of our digital devices have progressed at an astounding rate over the years, roughly in line with Moore’s Law. Taiwan Semiconductor and Samsung are planning to produce 1.4-nanometer chips by around 2027. These chips will lead to some astounding AI performance, but we are getting awfully close to the physical limits of silicon, and we will have to seek other technologies for computing power to continue advancing beyond silicon.
The Quantum Solution/Threat
Currently lurking in the waiting-room of the future is quantum computing. Right now, it’s cumbersome, expensive, and is years from being available commercially, but boy can it compute. It has been expected that quantum computers will be able to compute 158 million times faster than the most advanced existing silicon-based computer.
Researchers at the Centre for Cryptocurrency Research and Engineering of Imperial College London have calculated that a quantum computer with 1500 or more error-corrected qubits will be able to crack a Bitcoin private key. IBM has published a roadmap where they reckon computers with thousands of error-corrected qubits will be a reality by around 2029.
Opposingly, at the popular hacking news website, Hackernoon, they estimate that it would still take a quantum computer 10³² years of a brute force assault to hack Bitcoin. Some developers are proposing a Bitcoin encryption upgrade to ensure quantum resistance, but that would likely require at least a soft fork to implement.
Conclusion
The possibility of AI and quantum computing helping to retrieve lost Bitcoins are very exciting to some people, but threatens to destroy the value of Bitcoin, since the available supply could swell by a few million BTC, especially if they crack Satoshi’s wallet. The biggest fear is quantum computing though, and it’s good to see Bitcoin core devs putting contingency plans in place.
Till then, good luck to the likes of James Howells, who has been trying to retrieve a hard drive with 8,000 Bitcoin on it for over a decade. That’s around $560 million right now.
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.
Decoding the Next Generation of Wearables with HyperRing’s CEO Joy Zhang | Mindplex Podcast – S2EP12

Bitcoin Hits All-Time High Notes in Early 2024

Bitcoin is back into your friends’ and family’s chats, as the world’s most valuable digital asset edged its prior all-time high price record in dramatic fashion. The months of sustained growth that also saw other crypto niches like AI cryptocurrencies (riding the artificial intelligence trend) and memecoins (easy-to-understand mainstream tokens) balloon in value appeared unstoppable after most of the Grayscale spot ETF redemptions were done and investors are frothing at the sky-high predictions they are starting to hear across social media and cable news.
After spending over two years trading far far below its November 2021 peak, Bitcoin defied the naysayers by skyrocketing past $73,000 to set a new supreme price milestone of $73,750 on March 14th.
This latest achievement capped an extraordinary bull run for the crypto market leader, which saw its price increase by over 50% so far in 2024 amid frenzied trading activity. On the day it reached its new record high, $100+ billion worth of Bitcoin changed hands as investors pile in, hoping to ride the wave higher.
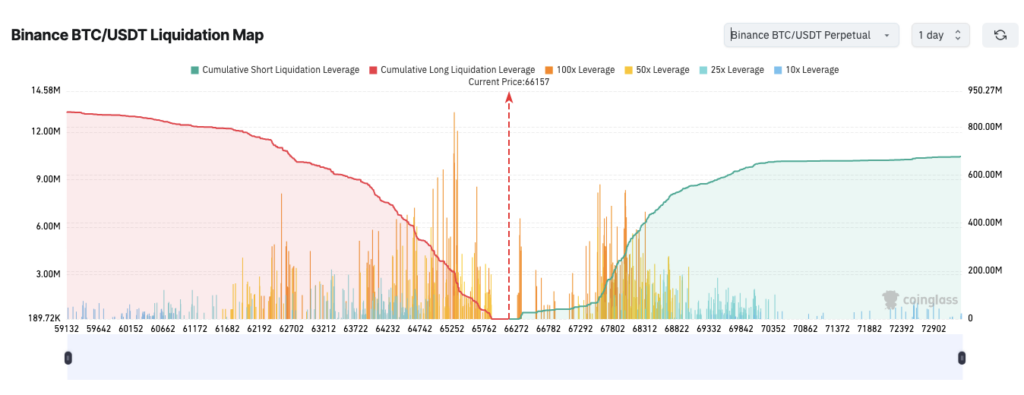
Bitcoin’s new personal best above $73,000 follows on from record-setting earlier in the month, when it hit $69,000 for the first time on 5 March. That proved too great to turn resistance into support, and caused a cascade of liquidations, with its price plunged by double-digits, falling over 15% to $59,000, before paring some of the losses in a rebound to a V-shaped recovery to the new high, and to the $71,000 where it currently trades.
This whiplash-inducing price action underscores the intense tug-of-war still playing out across crypto markets, where TradFi whales have now entered the ring and brought with them some heavy bags to throw around.
So what forces converged to propel the world’s largest cryptocurrency to such lofty new heights in the first quarter of 2024? As is often the case in these bullish periods, the rally was fueled by the perfect storm of optimistic narratives and real-world regulatory and economic developments. We already covered many of these in last year’s 2024 Crypto Bull Run article, and I recommend you go revisit it.
Bitcoin spot ETFs create insatiable BTC demand
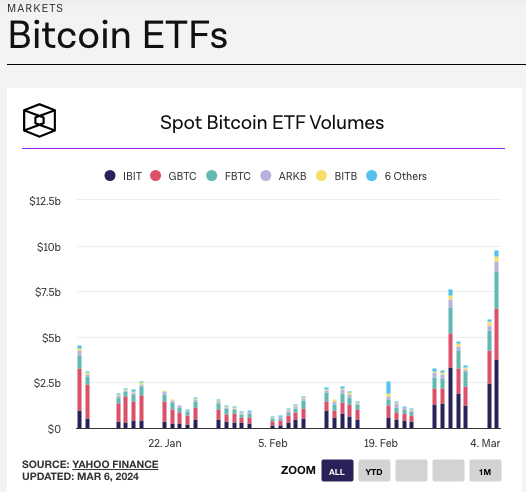
Restoring interest back in Bitcoin this year were the highly-anticipated launches of spot Bitcoin exchange-traded funds (ETFs) by major financial players like BlackRock, Fidelity, and Grayscale. After years of denial by US regulators, multiple spot Bitcoin ETFs finally received approval in January 2024.
These ETFs allow institutional and retail investors to gain exposure to Bitcoin’s price movements through a regulated, familiar product that directly holds the underlying crypto assets. Huge sums of investment capital flooded into these ETFs right out of the gate, creating immense buy pressure in the spot Bitcoin markets as the funds raced to accumulate enough BTC to back their fund shares.
Just two months after launching, the Bitcoin spot ETFs had already vacuumed up a staggering combined total of over $45 billion in assets under management, representing around 684,000 Bitcoin tokens: over 3% of the total circulating supply. Inflows showed no signs of stopping, with BlackRock’s fund alone reaching $10 billion in just seven weeks.
Bitcoin Halving
Another major factor driving Bitcoin’s rally has been the building anticipation of the next ‘halving’ event for the cryptocurrency, expected in April 2024. This systemic halving of Bitcoin’s mining reward happens automatically every four years, resulting in a 50% reduction in new supply hitting the market. The latest halving will see BTC rewards drop to 3.125, which is down four halvings from 2011’s block rewards of 50 BTC. With over 19 million Bitcoin already mined (and possibly a quarter lost) there is less and less to go around. Previous halvings reliably preceded massive price increases as the decreasing supply dynamic helped fuel further buying demand.
Many analysts and industry experts have forecasted Bitcoin to surge well past $100,000 within 12-18 months after April’s halving, based on the historic patterns of past cycles where prices eventually climbed 10× or higher following the supply shocks. Speculators piled in early to front-run the perceived upside.
FASB Accounting
Bitcoin’s rally also got a boost in late 2023 from the official embrace of long-awaited new accounting rules for US public companies around cryptocurrencies. Starting in 2025, new FASB guidance will allow businesses to value certain crypto assets at fair market value on their balance sheets each reporting period, marking a huge upgrade from the current treatment of Bitcoin as an ‘indefinite-lived intangible asset’.
This rule change laid the groundwork for even broader institutional adoption of Bitcoin, removing one of the final barriers for public companies and investment funds looking to add exposure without complex workarounds.
US Elections, SEC and Interest Rate Cuts
Another important consideration to make is the impact of US policymakers’ adoption of Bitcoin and crypto. While the SEC under Herr Gensler views most cryptos as securities, it views Nakamoto’s coin as a commodity thanks to its proof-of-work origins. The Fed, whose monthly FOMC meetings became horror movie nights for crypto investors in 2022 and 2023, will likely soon have to relent and start reducing those inflation-crunching high interest rates, or combat a recession next. And of course, America will decide on the next President this year, and this should see crypto bashing through Operation Chokepoint 2.0 this year. Even Donald Trump is warming to Bitcoin now.

What’s different this time round?
While the Bitcoin frenzy and associated wildly optimistic price forecasts provoked understandable flashbacks to the 2017 and 2021 crypto bubbles for market veterans, the 2024 rally did have some key fundamental differences.
This time, sustained upward price pressure came not from shadowy derivatives platforms like FTX and opaque stablecoin ecosystem hazards like you-know-who, but from transparent, battled-hardened regulated funds and publicly-traded companies allocating directly to Bitcoin’s core layer-1. Record volumes and open interest levels on trusted exchanges – centralized and decentralized, spot and derivative – reflected genuine liquidity.
And whereas the 2021 peak was fueled by hype around experimental blockchain technologies and corporate marketing gimmicks, Bitcoin’s 2024 renaissance had the more grounded narrative of finally fulfilling its long-awaited promises as a now matured value reservoir and decentralized financial network, emboldened by the embrace of legacy institutional capital via ETFs, which may soon extend to Ethereum.
Of course, only time will tell if Bitcoin can maintain these lofty price levels or if the market mania will once again dissolve into despair. It’s easy to get caught up in the FOMO, and even easier to hit that sell button at a loss when market euphoria wears off and those 20% drops or weeks of sideways action break your resolve.
But in its latest epic price run, crypto’s top dog (sorry Doge) demonstrated its incredible ability to capture imaginations and animate markets around the world like no other asset.
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.
Solar Powered Autonomous Farming Rovers | Mindplex Podcast – S2EP11

Ghostbuster: Unprecedented Accuracy in AI-Generated Text Detection

Text generated by language models, like ChatGPT, is getting better and better at mimicking human language. But doubts have been raised about the authenticity and trustworthiness of writing produced by AI. In response, scientists at the University of California, Berkeley have created Ghostbuster, a sophisticated technique for identifying text written by artificial intelligence.
Methodology
Ghostbuster uses an innovative technique that involves using a number of less powerful language models and running a systematic search over their features. It may determine if a document is artificial intelligence (AI) created by training a linear classifier on specific attributes. Interestingly, Ghostbuster can identify text produced by unknown or black-box models because it doesn’t need token probabilities from the target model. Three additional datasets were made available by the researchers for benchmarking detection across different domains.
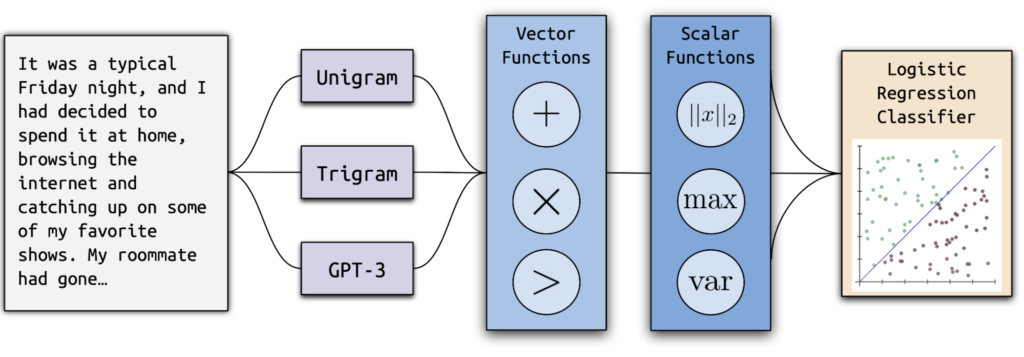
Performance and Comparison
Ghostbuster performed exceptionally well in assessments, outperforming competing detectors like DetectGPT and GPTZero by a wide margin with an in-domain classification score of 99.0 F1. It showed better generality over language models, prompting techniques, and writing domains. These astounding results demonstrate Ghostbuster’s dependability and its capacity to identify AI-generated material.
Ethics
There are a lot of ethical questions raised by the use of AI-generated text detection methods. Such models’ false positive rates, which mistakenly identify genuine human work as AI-generated, can have serious consequences. Prior research has revealed some biases, such as the disproportionate marking of writings written by non-native English speakers as AI-generated. Nonetheless, Ghostbuster helps to address these ethical issues thanks to its enhanced performance and generalization skills. Ghostbuster is a technological and moral advance since it ensures more accurate identification while lowering false positives.
Challenges and Future Directions
The paper notes that there are still difficulties in identifying language produced by artificial intelligence, especially when dealing with hostile prompting and paraphrasing attacks. But Ghostbuster’s emphasis on full paragraphs or papers produced by language models offers a viable direction for further investigation. It is imperative to prioritize transparency and fairness in the creation and implementation of AI-generated text detection systems to guarantee impartial treatment and prevent unwarranted harm.
Constraints
Despite Ghostbuster’s outstanding performance, it’s important to recognize its limitations. The quality and diversity of the weaker language models utilized in the detection process can affect the efficacy of the system. Furthermore, adversarial strategies might develop and provide problems for the accuracy of the system. To overcome these restrictions and further expand the system’s capabilities, more research is required.

Conclusion
In summary, Ghostbuster is a noteworthy development in the area of artificial intelligence-generated text detection. Its exceptional performance and ethical advancements make it an effective tool for recognizing text generated by artificial intelligence in a variety of sectors. Ghostbuster addresses potential biases and lowers false positives, promoting the safe usage of AI-generated text detection systems. Continued research and development is essential to overcoming obstacles, enhancing system performance, and guaranteeing the moral use of AI-generated text identification tools. With the prevalence of text produced by artificial intelligence (AI), Ghostbuster provides a useful way to ensure the reliability and trustworthiness of written material while giving ethical issues priority.
Let us know your thoughts! Sign up for a Mindplex account now, join our Telegram, or follow us on Twitter.

.png)

.png)


.png)